目录
C文件IO相关操作
介绍函数
文件相关系统调用接口
接口介绍
fd文件描述符
重定向
缓冲区
inode
软硬链接
动静态库
库的制作
制作静态库
制作动态库
使用库
使用静态库
使用动态库
C文件IO相关操作
介绍函数
打开文件

参数介绍:
const char* path:文件路径+文件名
const char* mode:打开的方式;
打开方式有大致有下类型(并不全面)。

向文件写入

参数说明:
const void* ptr:这是指向要被写入的元素数组的指针。
size_t size:这是要被写入的每个元素的大小,以字节为单位。
size_t nmemb:这是元素的个数,每个元素的大小为 size 字节。
FILE* stream:这是指向 FILE 对象的指针,该 FILE 对象指定了一个输出流。
返回值:如果成功,该函数返回一个 size_t 对象,表示元素的总数,该对象是一个整型数据类型。如果该数字与 nmemb 参数不同,则会显示一个错误。
读出文件数据

参数介绍:
void* ptr: 这是指向带有最小尺寸 size*nmemb 字节的内存块的指针。
size_t size: 这是要读取的每个元素的大小,以字节为单位。
size_t nmemb :这是元素的个数,每个元素的大小为 size 字节。
FILE* stream : 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输入流。
返回值:成功读取的元素总数会以 size_t 对象返回,size_t 对象是一个整型数据类型,表示读到了多少元素个数。如果总数与 nmemb 参数不同,则可能发生了一个错误或者到达了文件末尾。
移动文件位置

参数介绍:
FILE* stream : 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
long offset : 这是相对 whence 的偏移量,以字节为单位。
int whence : 这是表示开始添加偏移 offset 的位置。它一般指定为下列常量之一:
| SEEK_SET | 文件的开头 |
| SEEK_CUR | 文件指针的当前位置 |
| SEEK_END | 文件的末尾 |
返回值:如果成功,则该函数返回零,否则返回非零值。
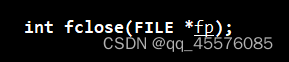
关闭文件
参数介绍:
FILE* fp: 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
返回值:如果流成功关闭,则该方法返回零。如果失败,则返回 EOF。
下边的代码将上述几个接口联合起来使用
#include <stdio.h>
int main(){
//关闭文件
FILE* fd = fopen("./bite","w+");
//向文件写入
char msg[] = "linux so easy!\n";
size_t w = fwrite(msg, sizeof(char), sizeof(msg), fd);
//调整文件位置
fseek(fd, 0, SEEK_SET);
//读取文件
char* buffer[1024];
size_t r = fread(buffer, sizeof(char),sizeof(buffer),fd);
if(r > 0){
printf("%s",buffer);
}
//关闭文件
fclose(fd);
return 0;
}
文件相关系统调用接口
接口介绍
打开文件

参数介绍
const char* pathname:要打开或创建的目标文件
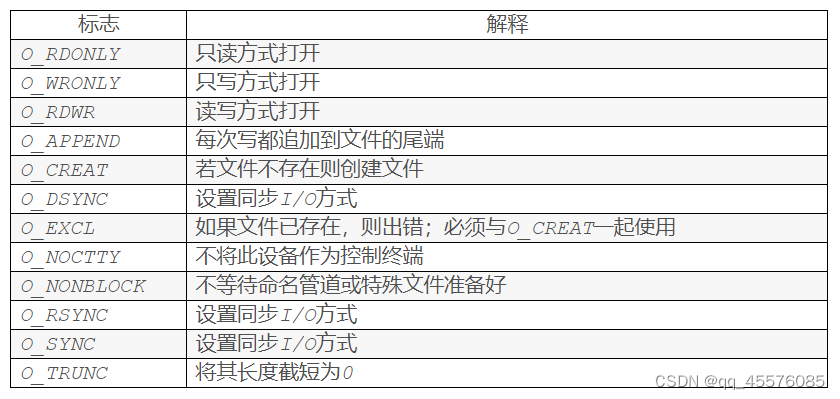
int flags:打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags
 mode_t mode: 文件权限。(对于一个已经存在的文件,参数mode是没有用的,通常将其省略,因此这种情况下open调用只需两个参数。)
mode_t mode: 文件权限。(对于一个已经存在的文件,参数mode是没有用的,通常将其省略,因此这种情况下open调用只需两个参数。)
返回值:
成功:新打开的文件描述符
失败:-1
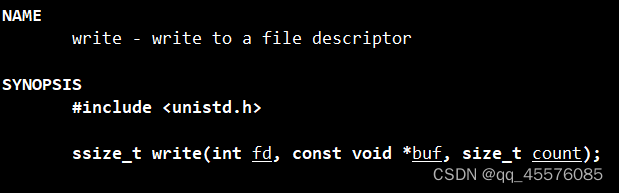
向文件写入
参数介绍:
int fd:文件描述符
const void* buf:指定写入数据的数据缓冲区
size_t count:指定写入的字节数
返回值:
成功:return 已写的字节数
失败:-1
return 0;(未写入任何数据)
读出文件数据
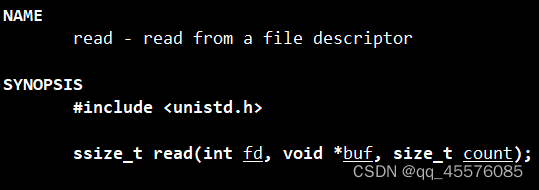
参数介绍:
int fd:文件描述符
void* buf:指定读入数据的数据缓冲区
size_t count: 指定读入的字节数
返回值:
成功:已读的字节数
0:未读入任何数据
-1:出错
移动文件位置
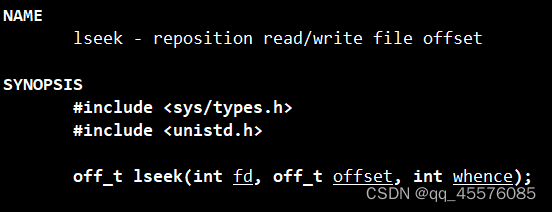
参数介绍:
int fd:文件描述符
off_t offset:偏移量,单位是字节
int whence:用于定义参数 offset 偏移量对应的参考值,该值需使用如下几个宏定义
SEEK_SET:文件的读写偏移量位于文件开头偏移offset的位置
SEEK_CUR:当前位置偏移量+offset字节就是读写偏移量的位置。这里需要注意的是offset可以为正值也可以为负值。如果为正值,则表示当前位置偏移量往后移offset就是读写偏移量的位置;如果为负值,则表示当前位置偏移量往前移offset就是读写偏移量的位置。
SEEK_END:文件末尾+offset字节就是读写偏移量的位置。offset的值也可以为正值或负值。
返回值
成功:当前读写位置相对于文件头部起始位置的偏移量
失败:return (offset - 1)
简单示例
off_t = lseek(fd, 0, SEEK_SET); //将读写位置放在文件的开头
off_t = lseek(fd, 100, SEEK_CUR); //将读写位置设为当前位置向后偏移100个字节的位置
off_t = lseek(fd, 0, SEEK_END); //将读写位置放在文件的末尾
关闭文件
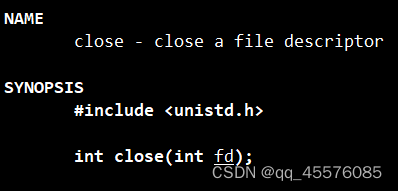
参数介绍:
int fd:文件描述符
返回值
成功:return 0
失败:return -1
下边代码将上述系统接口综合起来使用:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main(){
//打开文件
int fd = open("./bite", O_RDWR | O_CREAT, 0664 );
const char* msg="i like linux!\n";
//写入数据
write(fd, msg, strlen(msg));
//调整文件位置
lseek(fd, 0, SEEK_SET);//将读写位置放在文件的开头;
char buffer[1024];
//写入数据
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if(s > 0){
buffer[s] = 0;
printf("%s",buffer);
}
//写入数据
close(fd);
return 0;
}
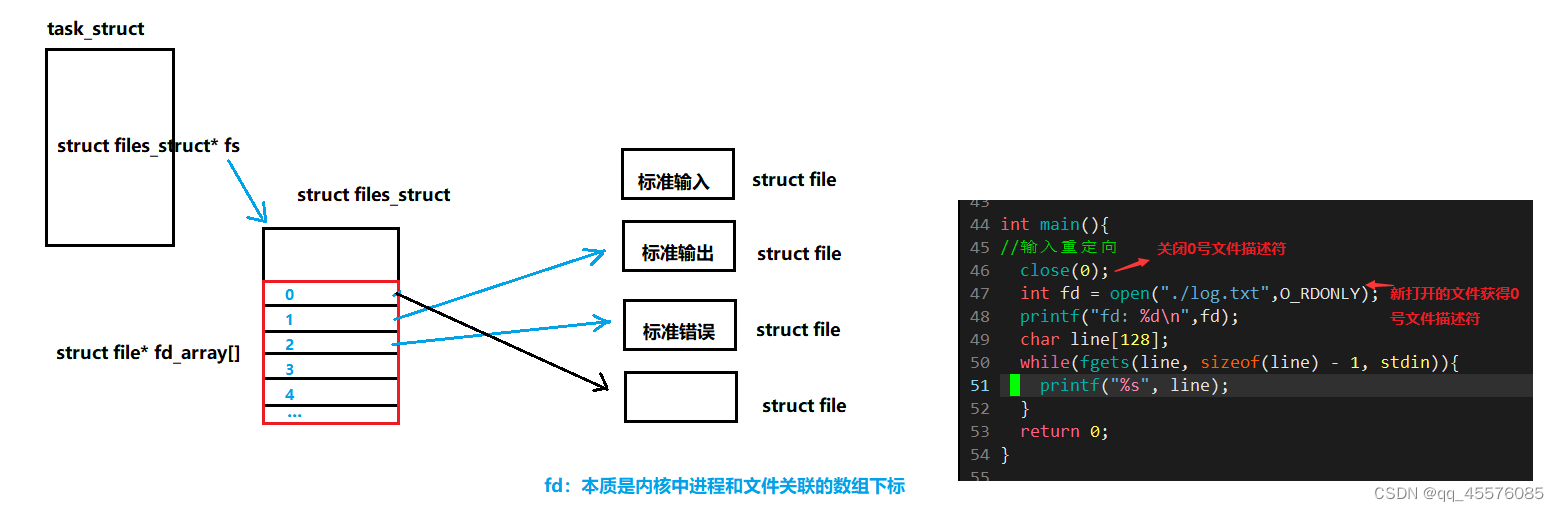
fd文件描述符

所有文件操作,表现上都是进程执行对应函数。操作文件必须首先打开文件,也就是先把文件加载到内存中。而系统中存在大量的进程,可能存在更多打开的文件。OS需要在内存(系统中)将这些打开的文件管理起来。OS存在struct file{};的结构体描述这些被打开的文件
下图描述了系统如何管理文件系统
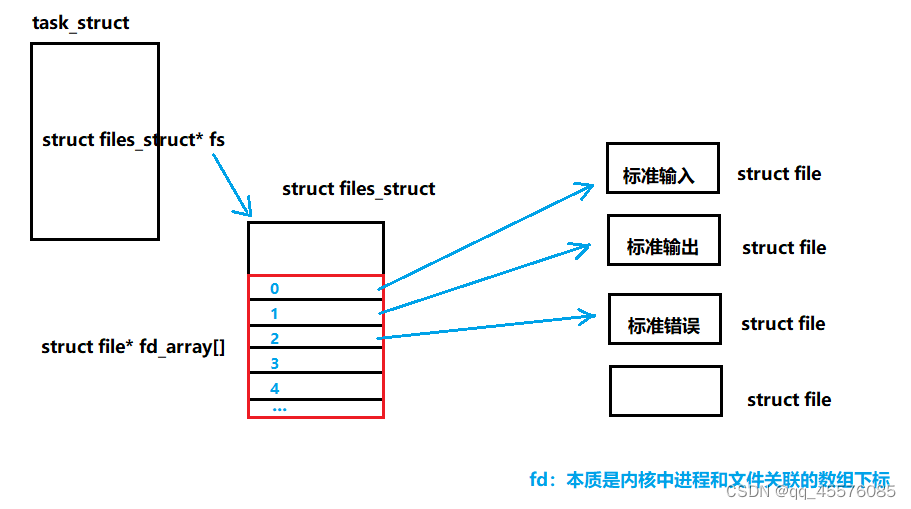
文件描述符的分配规则,给新文件分配的fd,是从fd_array中找一个最小的且没有被使用的fd作为其新分配的fd
重定向
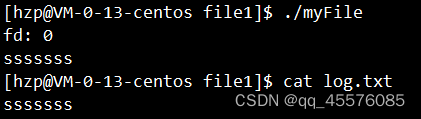
fgets是语言层面的读取函数,其底层也是用了系统标准输入接口。其中写死了只能对0号文件描述符进行读取操作。而现在上边的代码将0号文件描述符给了新的文件。故,该程序将读出log.txt文件中的内容。这里完成了输出重定向。
输出结果如下
上述代码是为了更清楚了解重定向的过程。其实系统给我们提供了更方便的系统接口函数。
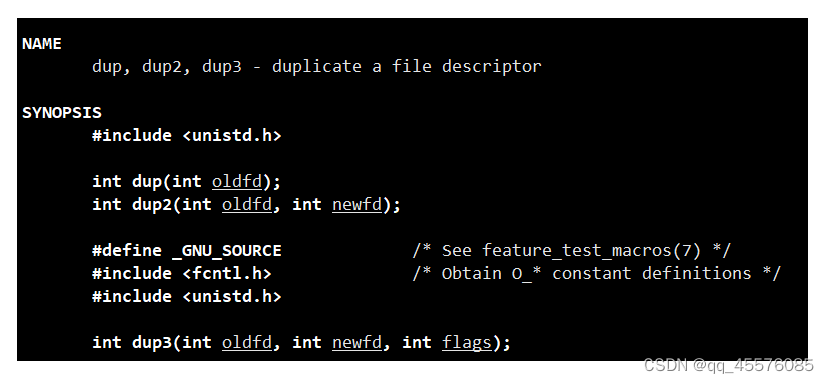
dup2将oldfd拷贝到了newfd。原本newfd指向的文件修改为指向新的文件了。完成重定向。
如下图代码:
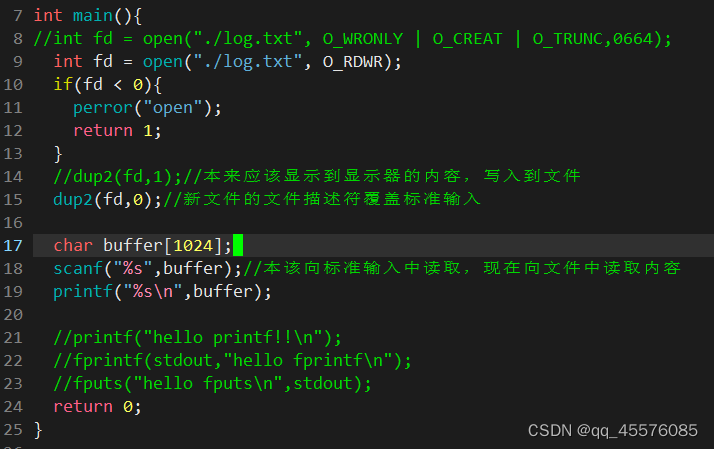
结果如下:
缓冲区

ps:上图的概念格外重要。
观察以下代码和执行结果
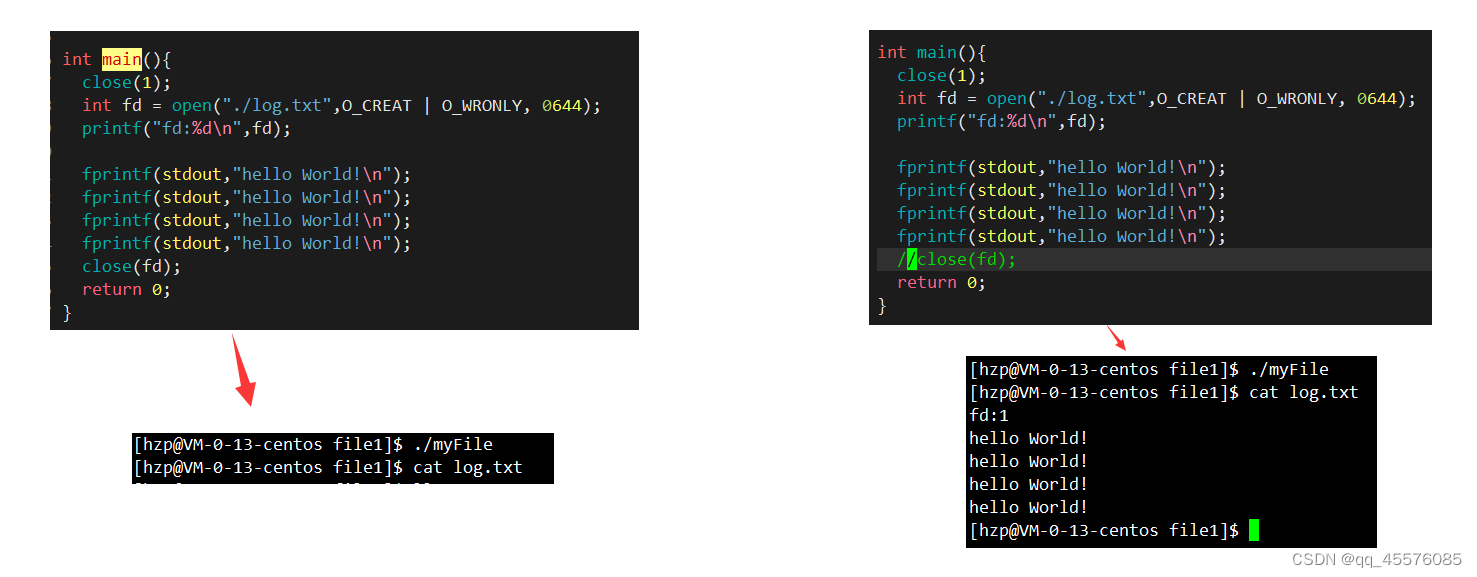
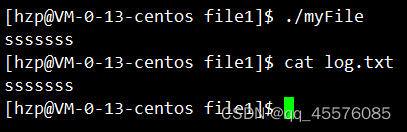
这里首先关闭了1号文件描述符,所以按照文件描述符分配规则,新打开的文件分配到的文件描述符为1。后边的打印语句,底层写死了向1号文件描述符操作,故会向新打开的文件进行写入操作。其刷新策略发生了改变。但是,最后一条语句close(fd);使得这个过程夭折。因为打印语句首先存放在C缓冲区中,因其关闭了文件描述符,C缓冲区无法向OS文件内核缓冲区刷新,更别说向外设刷新(比如这里会用到的显示器)了。

inode
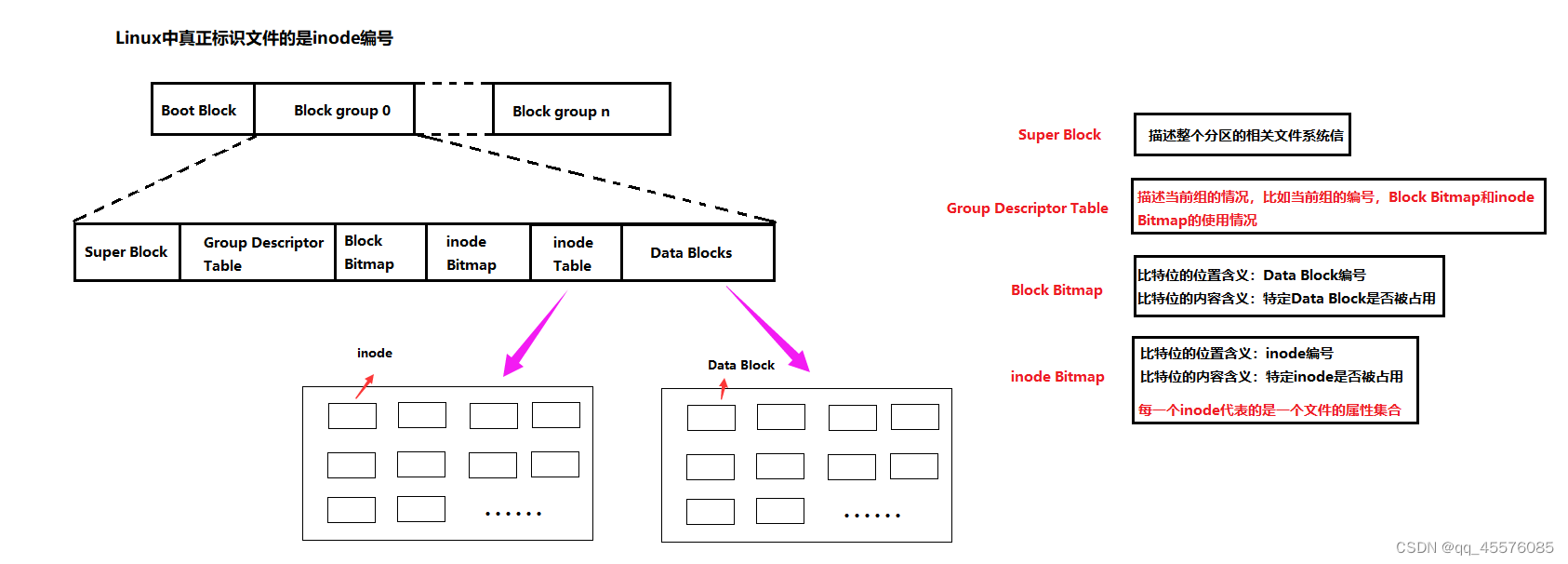
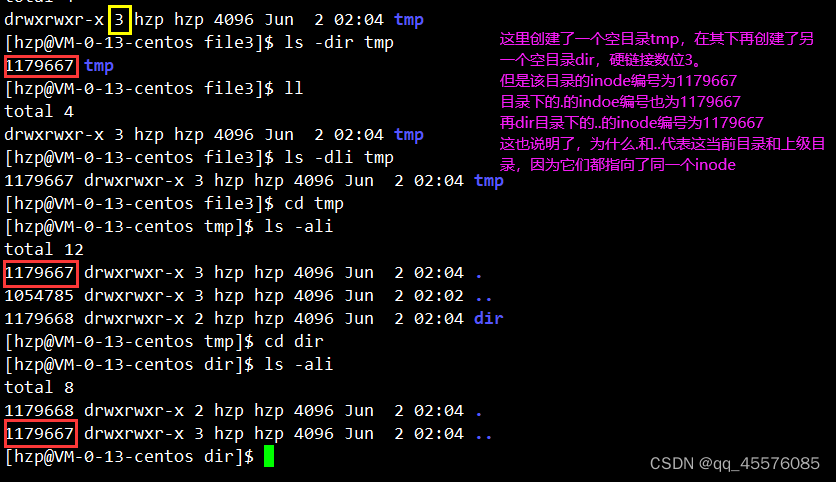
上边的图示非常重要;

查看log.txt内容。首先查看目录4-2的data block。这里的data block维护的是当前目录下的文件名和对应inode的映射关系。拿到inode编号,再去inode table中查找对应的inode,根据inode中的信息,找到其data block,打印其中的内容。
软硬链接
创建软链接:ln -s 文件名 软链接名
删除软链接:unlink 软链接名
创建硬链接:ln 文件名 硬链接名
删除硬链接:unlink 硬链接名
软连接作用相当于创建快捷方式,并且拥有自己独立的inode,意味着软连接是一个独立的文件。有自己的inode属性,也有自己的数据块(保存的是指向文件的所在路径+文件名)
硬链接本质不是一个独立的文件,而是一个文件名和inode编号的映射关系,因为自己没有独立的inode。创建硬链接,本质是在特定的目录下,填写一对文件名和inode的映射关系。可以完成重命名的工作。(ps:仔细观察下图)
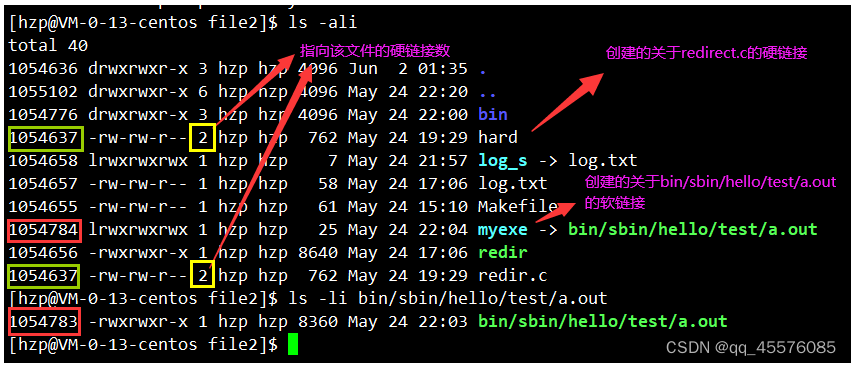
硬链接数存在inode属性中,当有一个文件指向它时就++,移除指向就--。也是我们说的引用计数
硬链接应用场景
动静态库
显式可执行程序依赖的库---->ldd+可执行程序

一般库分为两种,动态库和静态库
在Linux中,如果是动态库,库文件以.so作为后缀;如果是静态库,库文件以.a作为后缀
库文件的命名:libXXX.so- 或者 libXXX.a-
库的真实名字:去掉前缀lib,去掉后缀so-、a-后缀,剩下的就是库名称。
Linux下gcc编译默认使用的是动态链接编译

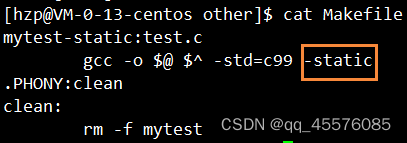
gcc使用静态链接编译需要在末尾加上 -static
所用动态链接,即程序所依赖的库在程序运行的时候并没有加载在程序中,而是在程序运行使用的时候系统链接库。
静态链接则是在程序运行的时候,将依赖的库加载到程序中。
我们可以预想到,静态链接产生的可执行文件一定会比动态链接产生的可执行文件大。我们可以使用不同链接方式验证这样的说法

库的制作
制作静态库
制作库的好处有两个。1、方便使用。2、私密(使用者看不到库中的源码)。
关于库的更好的理解我们需要知道程序的编译过程,请参考该博文:https://blog.csdn.net/qq_45576085/article/details/129604842
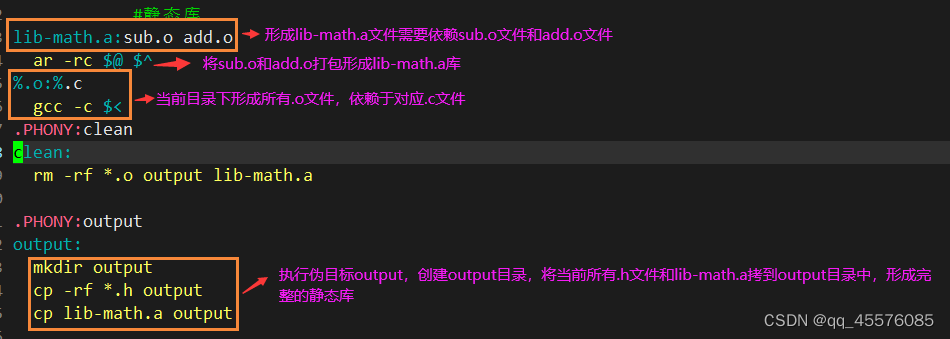
库的制作就是将所有的目标文件(.o文件)打包就能形成静态库。但是只有.o文件,使用者并不知道有什么方法,还需要添加.h告知库中有什么方法。才形成完整的静态库。静态库 = 所有.o文件+对应.h文件。

编译将当前目录下的所有.c文件打包形成库。
Makefile文件内容如下
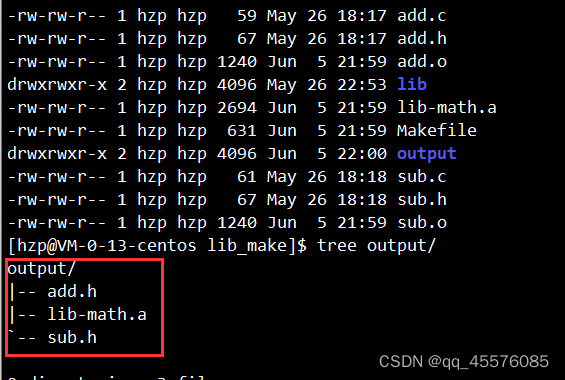
实行结果
制作动态库
makefile文件内容如下
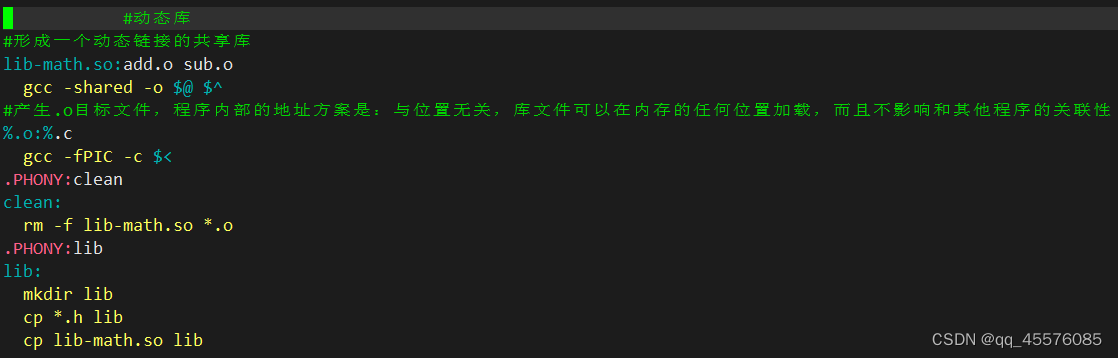
执行结果
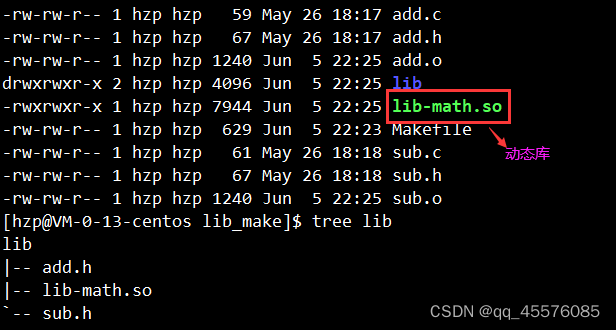
使用库
使用静态库
将制作的静态库添加到需要使用的目录下,使用gcc以下命令编译。

执行结果:

我们观察使用ldd查看可执行程序依赖的库,如下:
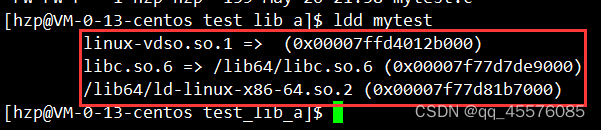
发现这里并没有我们自己制作的-math的静态库,这时因为编译的时候,我们的静态库就加载到了程序中了。
使用动态库
将制作的动态库添加到需要使用的目录下,使用gcc以下命令进行编译。

但是这样执行生成的可执行程序并不能运行。如下图:

这里提示我们的动态库并没有被找到,因为我们使用gcc命令编译的时候告知了编译器库在哪里,但是程序编译好之后,就和编译无关了。运行程序的时候加载器需要告知系统,库在哪里。这里还需要添加环境变量LD_LIBRARY_PATH,告知系统库的位置。

然后我们就能顺利使用动态库执行程序了,执行结果如下