需要使用的网址
Redis中文网 Download | Redis
数据库及缓存架构选型网址: DB-Engines Ranking - popularity ranking of database management systems
常识:
存储方面:
磁盘:
1,寻址:ms
2,带宽:G/M
内存:
1,寻址:ns
2,带宽:很大
秒>毫秒>微秒>纳秒 磁盘比内存在寻址上慢了10W倍
I/O buffer:成本问题
磁盘与磁道,扇区,一扇区 512Byte带来一个成本变大:索引
4K 操作系统,无论你读多少,都是最少4k从磁盘拿
关系型数据库:
关系型数据库存储:数据存储data page 4k 存储 ---》索引也是使用的是data page 4k(都在磁盘中进行的)----》内存及存储b+树方式搜索 将对应的data page读取数据到内存中
为什么使用4k 因为磁盘底层使用的是4k对齐方式
为什么要进行内存存储方式 因为数据可以比较快的找到索引页,通过索引页进行数据的查找
必须创建schema(数据库对象的集合(表,索引,视图,存储过程等))
类型:字节宽度(例如varchar char text 字节宽度就是varchar后边的存储个数 mysql4以前是字节数)
存:倾向于行级存储(mysql Oracle sql server 都是行级存储 大数据数仓是列式存储)
由于数据库:表很大,性能下降?
如果表有索引:
增删改变慢
查询速度呢?
1,1个或少量查询依然很快
2,并发大的时候会受硬盘带宽影响速度(常识中的磁盘解释,速度变慢很多---》从而引导出缓存概念)
内存数据库:
SAP HANA 内存级别的关系型数据库 2T内存 ibm与SAP都是老公司了主打数据库已经硬件方面
数据在磁盘与内存体积不一样:为什么?
因为在磁盘中我们可能会整理多个索引数据在磁盘中涨出,但是在内存中我们可以减少索引并且可以进行数据的压缩将我们存储的数据量减少
涨出问题:(在MySQL创建一个索引就有一个B+树,多个索引就有多个B+树,同时关系型数据库还有日志等相关信息,存储的内容肯定比内存要大)
但是这种数据库很贵,所以我们引用了一个折中的方法:
折中方法:
添加缓存技术
redis与memcached
基础设施:
冯诺依曼体系的硬件(计算机中初代程序与数据是不同的概念,但依曼体系:将程序编码为数据,然后与数据一同存放在存储器中):输入设备 输出设备 存储器 运算器 控制器
以太网 tcp/ip的网络:每次添加新的技术都会引起网络上的问题,需要多加注意
安装部署:
| centos 6.x redis 官网5.x http://download.redis.io/releases/redis-5.0.5.tar.gz |
| 1,yum install wget 2,cd ~ 3,mkdir soft 4,cd soft 5,wget http://download.redis.io/releases/redis-5.0.5.tar.gz 6,tar xf redis...tar.gz 7,cd redis-src 8,看README.md 9, make ....yum install gcc .... make distclean 10,make 11,cd src ....生成了可执行程序 12, cd .. 13,make install PREFIX=/opt/mashibing/redis5 14,vi /etc/profile ... export REDIS_HOME=/opt/mashibing/redis5 ... export PATH=$PATH:$REDIS_HOME/bin ..source /etc/profile 15,cd utils 16,./install_server.sh (可以执行一次或多次) a) 一个物理机中可以有多个redis实例(进程),通过port区分 b) 可执行程序就一份在目录,但是内存中未来的多个实例需要各自的配置文件,持久化目录等资源 c) service redis_6379 start/stop/stauts > linux /etc/init.d/**** d)脚本还会帮你启动! 17,ps -fe | grep redis |
使用场景:
类型:
string:
字符类型:
set get
strlen 长度
append 追加
setrange getrange 通过偏移量几开始修改,修改成什么 通过偏移量获取区间值
substr 通过偏移量截取值返回
exists 判断
setex:设置过期时间 psetex以毫秒为单位
setnx:判断key中没有值才进行设置有则不动
msetnx mget mset psetex
数值型:
incr +1
incrby 添加整数
incrbyfloat 添加小数
使用场景:
抢购,秒杀,详情页,点赞,评论
规避并发下,
对数据库的事务操作
完全由redis内存操作代替
bitmaps:
实际上, redis只支持5种数据类型. 并没有bitmap. 也就是bitmap是基于redis的字符串类型的. 而一个字符串类型最多存储512M.
8 * 1024 * 1024 * 512 = 2^32
例子:今有一个bitmap最大长度1024, 需要占用多大的空间?
解: 长度1024也就是他需要1024个位(bit), 或者单位为byte就是需要 1024 / 8, 即需要128byte
setbit getbit
bitcount
bitpos 查找到第一个为0或者为1 的bit位
bitop
1,有用户系统,统计用户登录天数,且窗口随机setbit sean 1 1
setbit sean 7 1
setbit sean 364 1
STRLEN sean
BITCOUNT sean -2 -1
01 02 03 04
sean 0 1 0 1 010101
json 0 1 0 1 011111
每用户46B * 用户数 10000000 =460 000 000
2,京东就是你们的,618做活动:送礼物
大库备货多少礼物
假设京东有2E用户
僵尸用户
冷热用户/忠诚用户
活跃用户统计!随即窗口
比如说 1号~3号 连续登录要 去重
setbit 20190101 1 1
setbit 20190102 1 1
setbit 20190102 7 1
bitop or destkey 20190101 20190102
BITCOUNT destkey 0 -1
u1 u2 u3
20190101 0 1 0 000100
20190102 1 1 0 10101
list:
rpush rpop brpop RPUSHX为已存在的列表存值
lpush lpop blpop blpoplpush 弹出值进行在另一个列表中存储
llen 列表长度 lrem 移除元素 lset通过索引更改值 ltrim 保留范围内的值
lrange 查看范围内的值
栈
队列
数组
阻塞 单播队列 FIFO
hash:
hset hget hmset hmget hvals获取哈希表中所有值 hkeys获取字段 hlen获取哈希表中数量
hgetall hexists hdel 删除一个或多个哈希字段
字段与浮点字段添加:hincrby hincrbyfloat
hsetnx 有数据时不设置
set:
sadd 添加
spop随机弹出 例子:抽奖:10个奖品 用户: 10 中将:是否重复 解决家庭争斗!
sdiff 差集 sdiffstore交集给新的集合
sunion 并集 sunionstore 并集给新的集合
sinter 交集 sinterstore 交集给新的集合
SMOVE 将集合元素移动到另一个元素中
scard 获取数据量
srandmember 返回一个或多个随机数 随机事件
SRANDMEMBER key count
正数:取出一个去重的结果集(不能超过已有集)
负数:取出一个带重复的结果集,一定满足你要的数量
如果:0,不返回
srem移除一个或多个随机数
smembers取出
sorted_set:
有序的,根据添加进入的分数值(可以是浮点数)进行排序 如果没有的话返回错误
如果分数相同这个字符串可根据典排序进行排序。典排序(字母顺序)
| ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| ZCARD key 获取有序集合的成员数 |
| ZCOUNT key min max 计算在有序集合中指定区间分数的成员数 |
| ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment |
| ZINTERSTORE destination numkeys key [key ...] 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| ZLEXCOUNT key min max 在有序集合中计算指定字典区间内成员数量 |
| ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合成指定区间内的成员 |
| ZRANGEBYLEX key min max [LIMIT offset count] 通过字典区间返回有序集合的成员 |
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员 |
| ZRANK key member 返回有序集合中指定成员的索引 |
| ZREM key member [member ...] 移除有序集合中的一个或多个成员 |
| ZREMRANGEBYLEX key min max 移除有序集合中给定的字典区间的所有成员 |
| ZREMRANGEBYRANK key start stop 移除有序集合中给定的排名区间的所有成员 |
| ZREMRANGEBYSCORE key min max 移除有序集合中给定的分数区间的所有成员 |
| ZREVRANGE key start stop [WITHSCORES] 返回有序集中指定区间内的成员,通过索引,分数从高到底 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| ZREVRANK key member 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| ZSCORE key member 返回有序集中,成员的分数值 |
| ZUNIONSTORE destination numkeys key [key ...] 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| ZSCAN key cursor [MATCH pattern] [COUNT count] 迭代有序集合中的元素(包括元素成员和元素分值) |
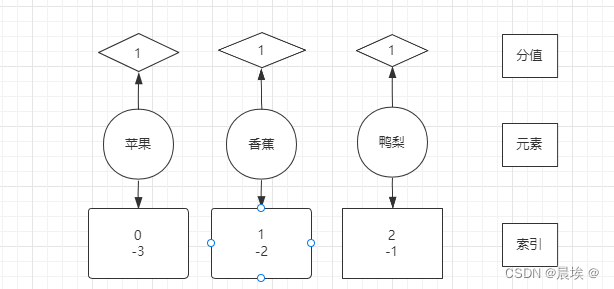
注意:
物理内存左小右大
不随命令发生变化
zrang
zrevrang
集合操作 并集,交集 -----》 权重/聚合指令
排序是怎么实现的 增删改查的速度?----》skip list 跳跃表
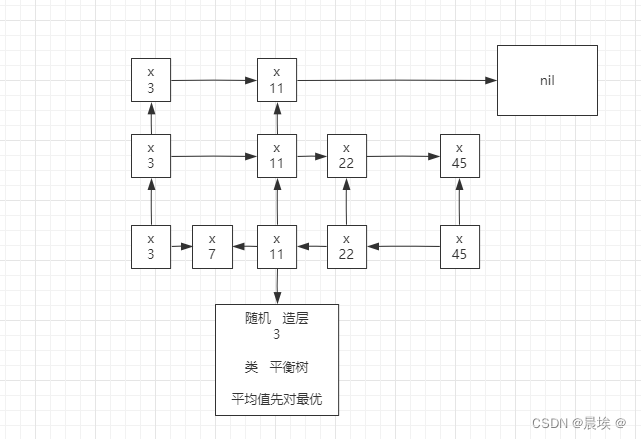
redis的使用:
发布与订阅:
redis发布订阅是(pub/sub)是一种消息通信模式:发送者(pub) 接收者(sub)
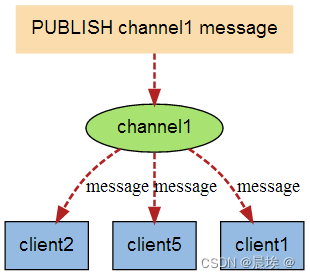
当有新消息通过 PUBLISH 命令发
送给频道 channel1 时, 这个消
息就会被发送给订阅它的三个客
户端:
| PSUBSCRIBE pattern [pattern ...] 订阅一个或多个符合给定模式的频道。 |
| PUBSUB subcommand [argument [argument ...]] 查看订阅与发布系统状态。 |
| PUBLISH channel message 将信息发送到指定的频道。 |
| PUNSUBSCRIBE [pattern [pattern ...]] 退订所有给定模式的频道。 |
| SUBSCRIBE channel [channel ...] 订阅给定的一个或多个频道的信息。 |
| UNSUBSCRIBE [channel [channel ...]] 指退订给定的频道。 |

redis持久化问题:
分为两种模式:rdb aof模式
在redis5之后aof模式压缩时掺杂了rdb模式,减少使用空间。
rdb:快照/副本
aof:日志
存储方式:因为redis单线程的。
要想将数据放在本地~推论:
RDB:
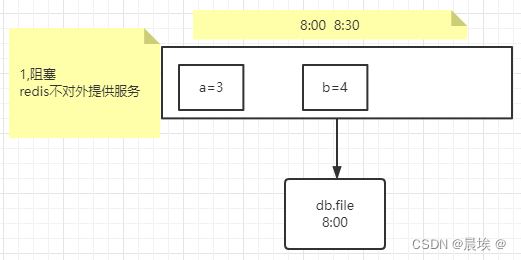
时点性:8点进行存储,但是存储需要时间,在存储是修改了,那么他是存储的什么点?8点的~~时点性
了解:
管道:more
1,衔接,前一个命令的输出作为后一个命令的输入
2,管道会触发创建【子进程】
echo $$ | more
echo $BASHPID | more
$$ 高于 |

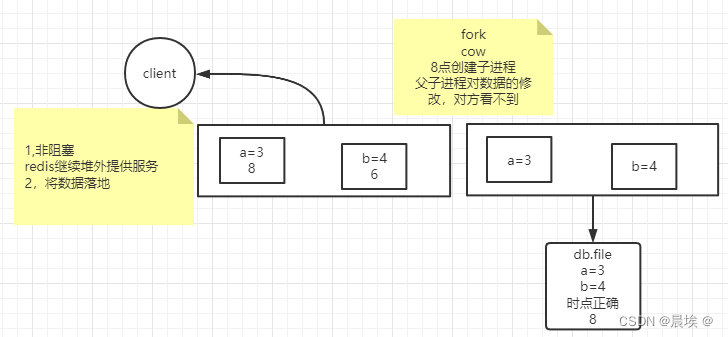
copy on write:内核机制
写时复制
创建子进程并不发生复制
创建进程变快了
根据经验,不可能父子进程把所有数据都改一遍
玩的是指针
使用linux的时候:
父子进程
父进程的数据,子进程可不可以看得到?
常规思想,进程是数据隔离的!
进阶思想,父进程其实可以让子进程看到数据!
linux中
export的环境变量,子进程的修改不会破坏父进程
父进程的修改也不会破坏子进程
创建子进程应该考虑什么?
1.速度
2.内存空间够不够
通过fork()方法--》速度快 空间小(因为使用的是指针)
方法一:阻塞redis不对外提供服务。
方法二:非阻塞 redis继续对外提供服务,使用父子进程将数据隔离开来
SAVE: 目的明确~~比如关机维护等使用
bgsave:fork 创建子进程。
创建文件中给出bgsave的规则:save这个表示,save 900 1 。。。
弊端:
不支持拉链,只有一个dump.rdb
丢失数据相对较多些,时点与时点之间窗口数据易丢失。
优点:类似于Java的序列化,恢复数据较快,快照型
AOF
redis的写操作记录到文件中,类似于日志存储方式。
丢失数据较小
redis中rdb和aof可以同时开启,如果开启了aof只会使用aof恢复,4.0后,aof中农包含rdb全量,层架记录新的写操作
弊端:
体量无限变大,恢复慢。
如何进行优化日志:
普通方法:hdfs,fsimage+edits.log 让日志制只记录增量合并的过程
不明白可以看下HDFS:Edits和Fsimage详解与合并流程 - 知乎 (zhihu.com)
reids的方法:
4.0之前:重写:删除抵消的命令,合并重复的命令。纯指令文件
4.0之后:重写:将老的数据RDB到aof文件中,将增量的以指令的方式Append到AOF,AOF
是一个混合体,利用了RDB的快,利用了日志的全量
redis---》kernel fd8 buffer ---》磁盘
kernel buffer--》操作系统修炼秘籍(14):两个缓冲空间:kernel buffer和io buffer | 骏马金龙 (junmajinlong.com)
配置:
redis是内存数据库,写操作会触发IO config配置:
appendonly yes
appendfilename "appendonly.aof"
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
appendfsync always
appendfsync everysec
appendfsync no
事务问题:
在集群中想要使用事务的话我们连接要使用redis-cli -c
使用特殊符进行前方点缀让他们在一个机器上,可以使用自己本身的事务操作
1、MULTI # 开启事务
2、命令1 # 执行命令
3、EXEC # 提交到数据库执行
4、DISCARD # 取消事务

redis常见问题之~击穿 穿透 雪崩
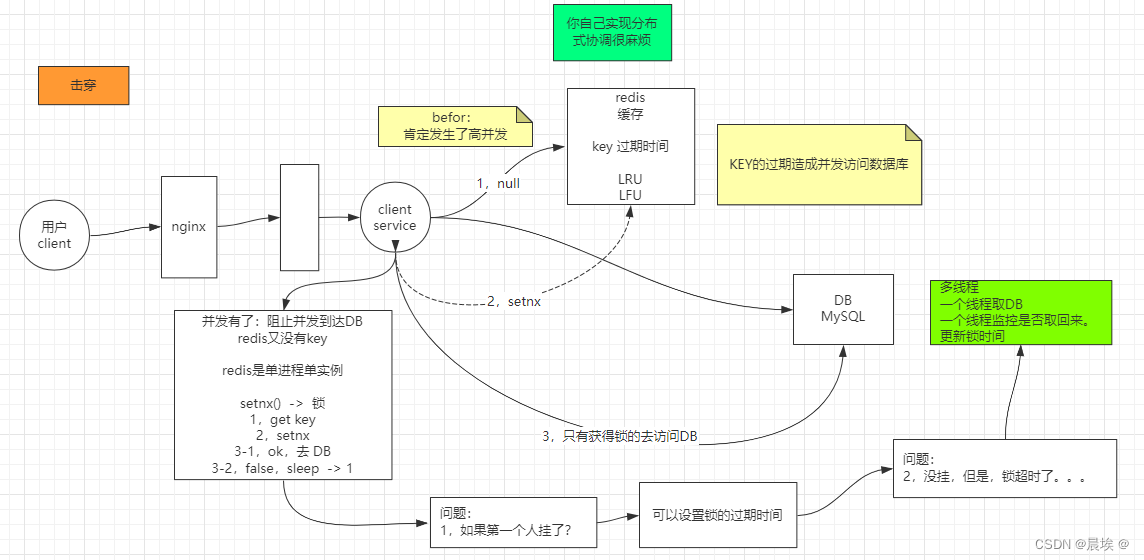
击穿:
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
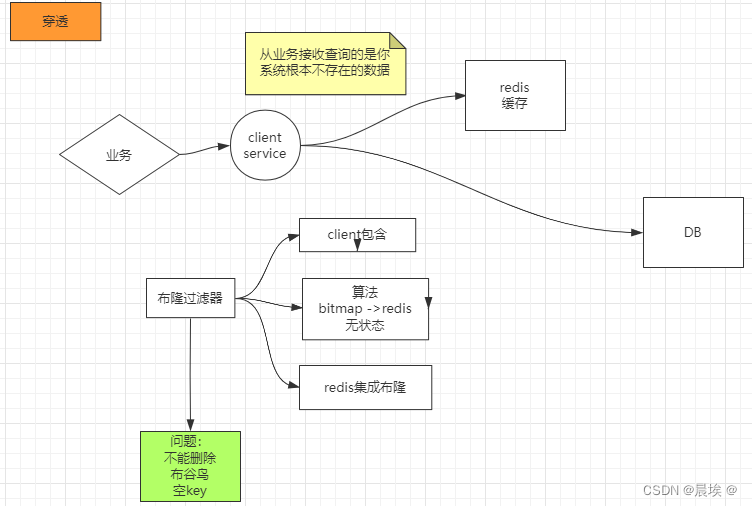
穿透:
假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。黑客发出的那 4000 个攻击,缓存中查不到,数据库中也没有,这种场景的缓存穿透可以直接将数据库干掉。
解决方法:
通过过滤器,将数据进行请求过滤,有效的减少数据的穿透,但是这种过滤不能够百分百的阻击,会有少部分请求穿透过来,但是也有可能查询会被过滤掉。
布隆过滤器流程:
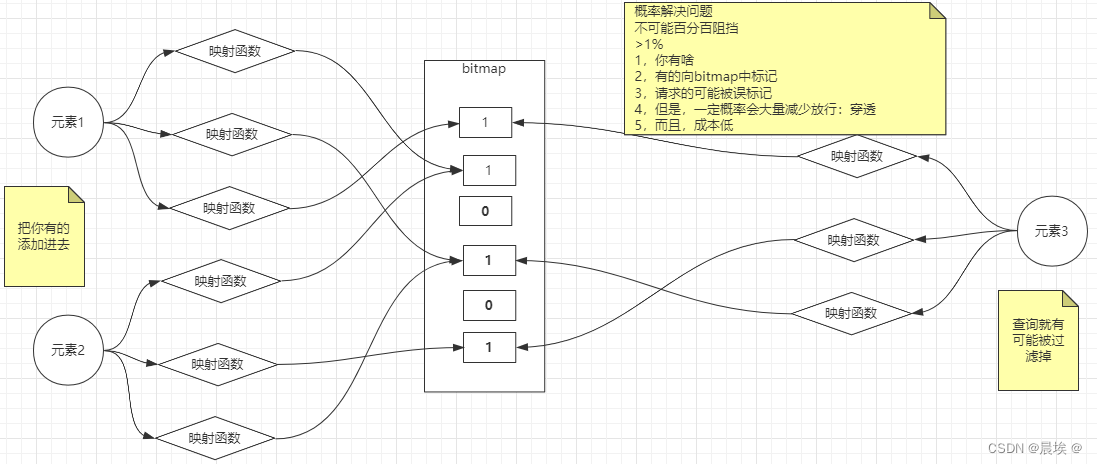
方案:
客户端实现bloom算法,自己承载bitmap 服务端就只有redis服务端
客户端实现bloom算法,服务端承载 bitmap和redis服务
客户端只有客户端,服务端实现bloom与bitmap并且实现redis服务
过滤器:
bloom 布隆过滤器
布隆过滤器服务端:
1,访问redis.io
2,modules
3,访问RedisBloom的github GitHub - RedisBloom/RedisBloom: Probabilistic Datatypes Module for Redis
4,linux中wget *.zip
5,yum install unzip
6,unzip *.zip
7,make
8,cp bloom.so /opt/mashibing/redis5/
9,redis-server --loadmodule /opt/mashibing/redis5/redisbloom.so
10 ,redis-cli
11,bf.add ooxx abc
bf.exits abc
bf.exits sdfsdf
12,cf.add # 布谷鸟过滤器
counting bloom
cukcoo 布谷鸟过滤器
雪崩:
redis中大量数据同时失效,间接造成数据大量访问db
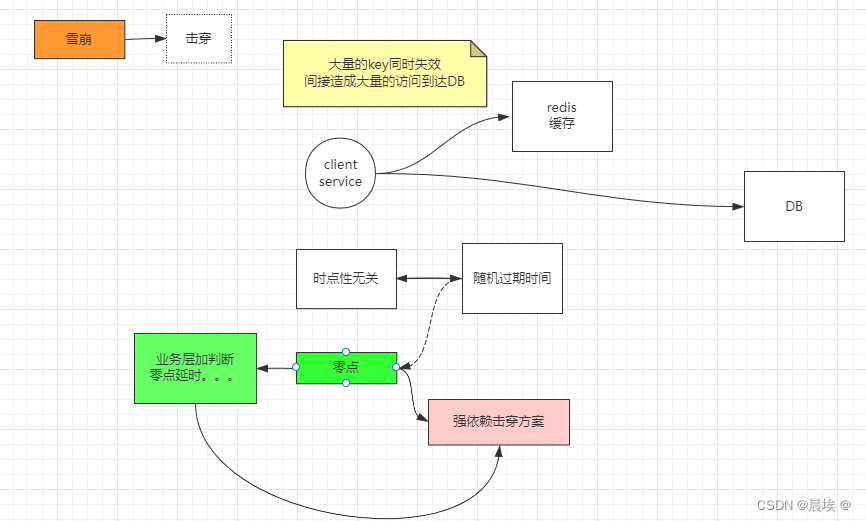
一致性(双写)
redis集群演化:
单节点问题:
单点故障
容量有限
压力
akf扩展立方体:
x:全量,镜像 (复制)
y:业务,功能 (拆分)
z:优先级,逻辑在拆分
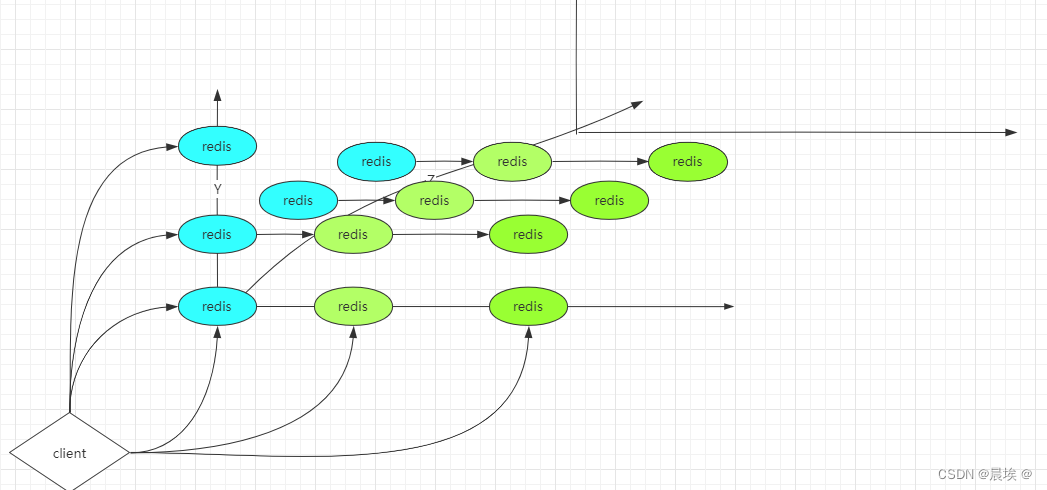
通过akf搭建成为了集群,但是集群模式一定会出现的问题:
cap问题:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance(分区容忍性)
三者取其二不可兼得
数据一致性问题:
所有节点阻塞直到数据全部一致
*,同步方式阻塞方式
强一致:
*,同步方式阻塞方式
破坏可用性!反问自己:为什么一变多,解决可用性(使用弱一致性)
弱一致性
*,通过异步方式
1,容忍数据丢失一部分
最终一致性

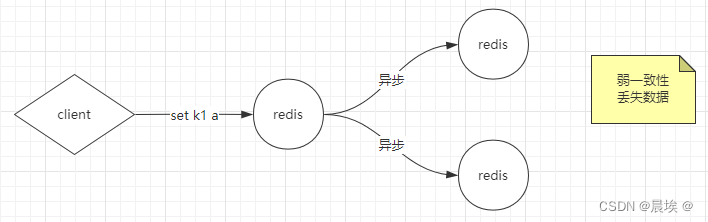
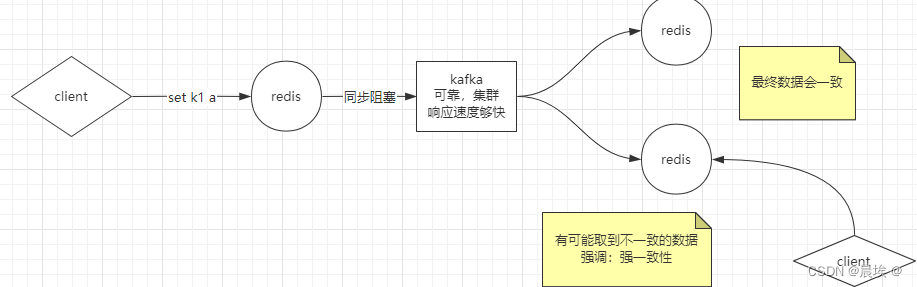
单节点模式上边已经介绍过了下边开始介绍多节点模式:
主备模式:主从复制模式
相当于是横向扩容,还是一个主使用节点,备节点进行数据备份。
推导:还是单机进行的操作,单点故障,容量有限,压力解决了单节点故障。
配置:
replica-serve-stale-data yesreplica-read-only yes
repl-diskless-sync no
repl-backlog-size 1mb
#增量复制
min-replicas-to-write 3
min-replicas-max-lag 10
哨兵模式:
通过哨兵进行对节点的监听,如果主节点设备挂掉了,可以通过哨兵进行选举从节点为主节点
只要是集群模式的这种那么就会出现一个问题,分区容忍性。
从节点几台可以进行选举呢 ?怎样算是选举成功,或者是判断主节点挂掉呢?
n/2+1个数进行判断 过半机制
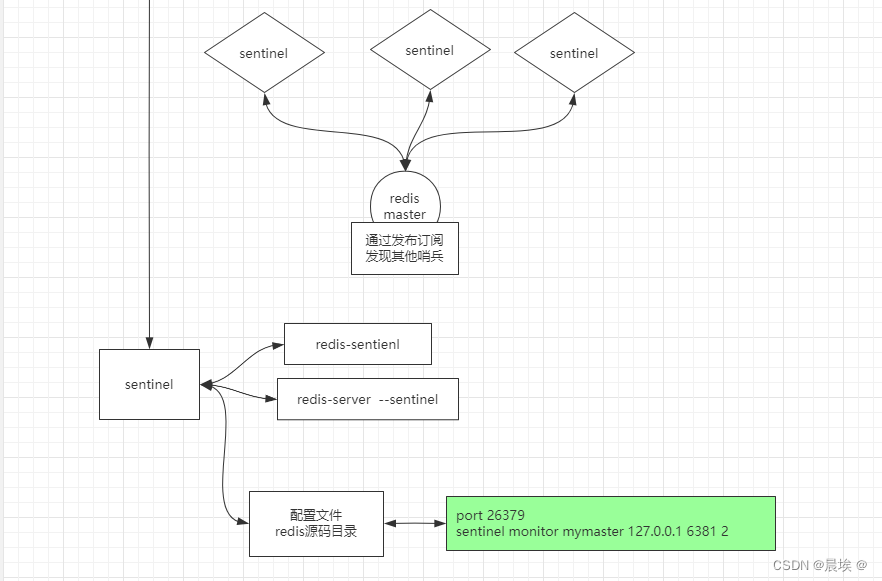
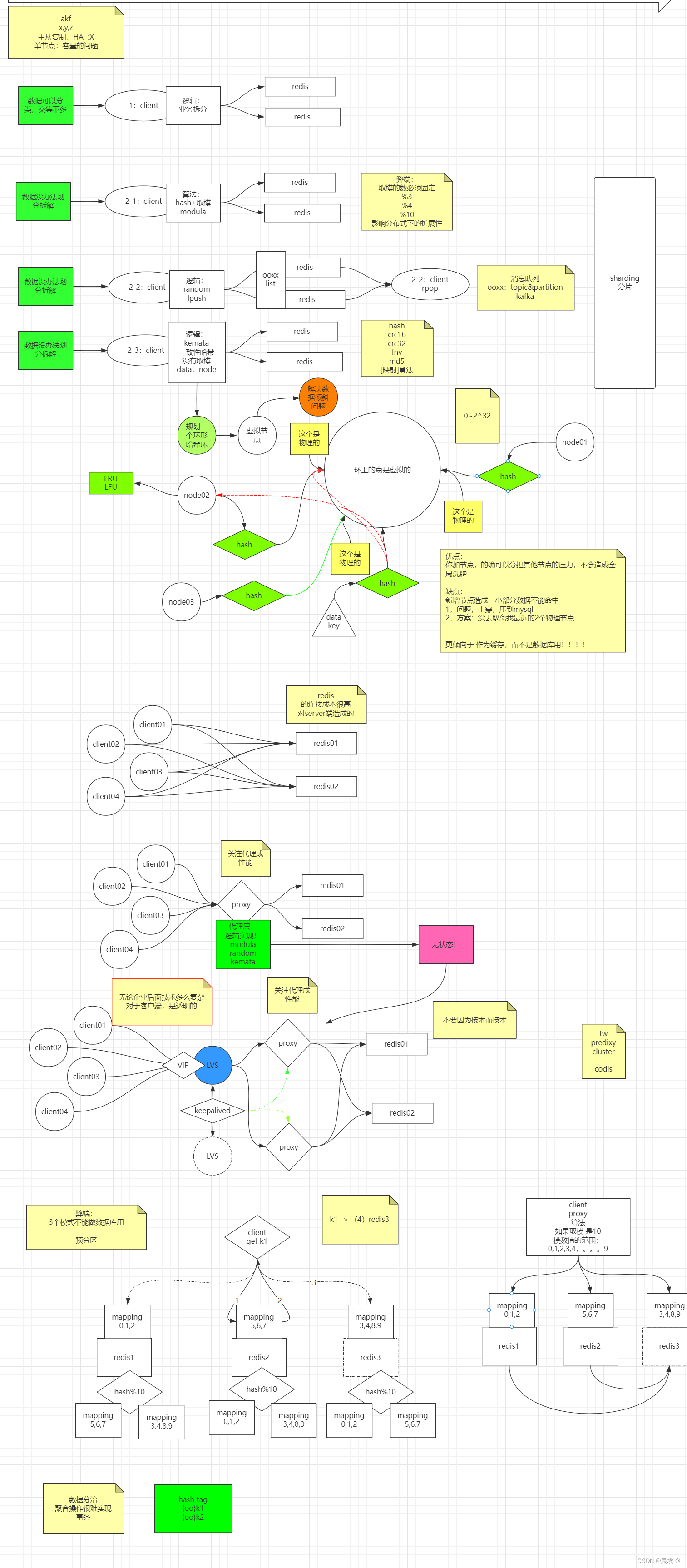
分片集群模式:
推导---分片集群:
数据可以分类,交集不多时,可以通过业务分类到不同redis中
当数据无法进行划分拆解时:通过算法取模+模块化 到不同的redis中,
弊端:
取模的数必须固定
%3
%4
影响分布式下的扩展性
或者:
使用随机数+list组成消息队列模式通过发布订阅将数据放入到对应的redis中
通过分片将不同的数据放在对应的redis中
(7条消息) 超详细 高性能redis集群搭建 —— 第二篇(predixy搭建)_秋丞的博客-CSDN博客_predixy
分布式锁:
使用setnx+过期时间+多线程(守护线程)延长时间
上方解释:设置过期时间进行判断以防setnx挂掉,通过多线程监测过期时间进行延长
使用redisson
zookeeper做分布式锁
(6条消息) Redis分布式锁-这一篇全了解(Redission实现分布式锁完美方案)_Venlenter的博客-CSDN博客_redission
api操作:
Clients | Redis
春季数据 Redis (spring.io)
缓存淘汰算法:
缓存淘汰算法(LFU、LRU、ARC、FIFO、2Q)分析 - 知乎 (zhihu.com)



![[数据结构 -- 手撕排序算法第一篇] 堆排序,一篇带你搞懂堆排序](https://img-blog.csdnimg.cn/img_convert/7c3e7bac40d5370d3ff4ff7da20481da.png)