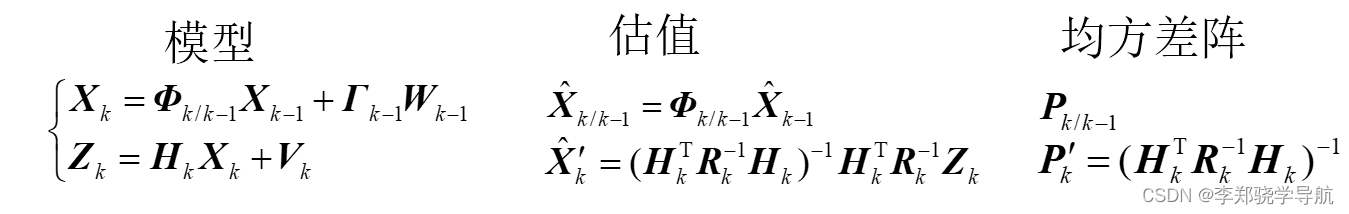阿里云OpenSearch重磅推出LLM智能问答版,面向行业搜索场景,提供企业专属问答搜索服务。
智能问答版基于内置的LLM大模型提供问答能力,一站式快速搭建问答搜索系统。
目前OpenSearch LLM智能问答版已开始邀测(https://page.aliyun.com/form/act704097138/index.htm),欢迎企业、开发者评测体验。
1. 企业专属问答搜索
1.1. 世界知识 vs 企业专属知识
以通义千问为代表的生成大模型正在引领搜索技术变革,其表现出的“什么都懂,什么都能聊”关键是依赖于底座大语言模型(Large Language Model, LLM)中压缩的世界知识。但无论是多强大的LLM,能压缩的知识量仍然是有限的。
下图中的问题是关于阿里巴巴内部的技术产品,属于企业专属知识,直接询问生成大模型给出的答案是完全错误不相关的。

针对这个问题,开源社区提出了DocsGPT、ChatPDF、基于langchain的检索增强chatbot等等一系列解决方案,足以证明业界对如何在个人/企业专属数据上结合LLM需求强烈。
1.2. LLM的检索增强式能力
OpenSearch团队结合多年搜索实践经验,提出LLM检索增强式能力,为用户提供一站式SaaS化行业问答搜索解决方案。
对于用户输入Query,如果结合业务数据中检索到的结果一起输入给LLM,则可以得到更精准的回答。
如下所示:
Query:阿里的TPP平台是什么
在企业内部文档中检索到的结果如下:
TPP是阿里个性化算法开发平台,依托阿里AI·OS引擎(特征、召回、打分等引擎)为众多的个性化业务(搜索、推荐、广告等)提供Serverless化的在线服务能力。用户在TPP平台上编写业务代码,做AB实验并对外提供服务,而无需关心机器资源、应用部署结构,不需编写服务框架。在TPP产品页面可管理业务代码的全生命周期,包括编译,调试、发布上线、监控报警、问题排查。结合AI·OS引擎套件接口和高性能图化开发框架,用户只需要实现自己的业务逻辑,即可拥有稳定、高性能的个性化在线服务。
将检索结果作为prompt输入模型后,模型给出了更加精准简练的回答:

对于LLM的检索增强式能力,有以下两点需要特别注意权衡:
- 有效性:生成的结果是基于检索结果中与Query最相关的部分总结。
- 有害性:生成的结果不应该是脱离检索结果随意编造,错误的信息反而会误导用户。
OpenSearch智能问答版在这一场景下对大模型预先进行了finetune,并针对性的调整了模型参数和prompt格式,尽可能的保障问答结果的精准可靠。
2. 技术实现
2.1. 系统架构

OpenSearch智能问答版系统架构主要包含业务数据处理、大模型预训练、问答搜索在线服务三个部分。
2.1.1. 业务数据处理
相比传统的搜索引擎,OpenSearch智能问答版离线数据处理流程最大的变化点在于对业务数据的处理:
- 传统搜索引擎的数据源是结构化文本,而这里需要处理的往往是非结构化文本,并且数据的格式会更加多样(HTML、Markdown、纯文本、PDF等)
- 传统搜索引擎构建索引是基于文档的唯一主键,而这里由于数据源的差异,需要先对文档进行段落拆分,对拆分后的段落生成新的段落主键
- 传统搜索引擎基于文本索引进行内容匹配,而这里采用向量索引,更加容易适配丰富的数据格式和长文本搜索

2.1.2. 在线服务
相比传统的搜索引擎,OpenSearch智能问答版在线服务架构变化非常大,主要区别有:
- 传统搜索返回的结果数一般在10以上,还经常会有翻页查询,而这里的检索是为了找到最相关的段落内容,Top N中的N不宜过大(一般在3以内),且需要控制相关性,不召回相关性过低的段落带来误导
- 检索完成得到Top N搜索结果后,会将结果添加到prompt中输入大模型,这一阶段耗时一般较大,OpenSearch智能问答版支持流式输出以缓解等待时间过长的体验问题
- 返回结果时,会基于用户业务数据,通过API输出指定Query下的相关搜索结果和模型生成的问答结果

2.2. 检索增强
2.2.1. 段落拆分模型:ops-text-ace-001
“巧妇难为无米之炊”,在检索增强式LLM的架构下,模型最终生成的效果很大程度上是由prompt中给出的检索结果决定的。
传统文档检索系统只需要针对Query给出最相关的文档列表,具体的信息筛选总结交由用户自己完成。
检索增强式LLM则需要给出具体与Query相关的段落,并且这里的段落不宜出现语义信息缺失或者输入超长,最好可以包含一段完整的语义信息。
权衡效率与效果,OpenSearch智能问答版的段落拆分模型特点如下:

最终的拆分效果可以参考下面的例子:
名词解释
<a name="ucuiH"></a>
## 实例管理
| **名称** | **说明** |
| --- | --- |
| 实例 | 实例是用户的一套数据配置,包括数据源结构、索引结构及其它属性配置。一个实例即一个搜索服务。 |
| 文档 | 文档是可搜索的结构化数据单元。文档包含一个或多个字段,但必须有主键字段,OpenSearch通过主键值来确定唯一的文档。主键重复则文档会被覆盖。 |
| 字段 | 字段是文档的组成单元,包含字段名称和字段内容。 |
| 插件 | 为了在导入过程中进行一些数据处理,系统内置了若干数据处理插件,可以在定义应用结构或者配置数据源时选择。 |
| 源数据 | 原始数据,包含一个或多个源字段。 |
| 源字段 | 组成源数据的最小单元,包含字段名称和字段值,可选数据类型请参见[应用结构&索引结构]。 |
| 索引 | 索引是用于加速检索速度的数据结构,一个实例可以创建多个索引。 |
| 组合索引 | 可将多个TEXT或SHORT_TEXT文本类型的字段配置到同一个索引,用来做组合索引。如一个论坛搜索,需要提供基于标题(title)的搜索及基于标题(title)和内容(body)的综合搜索,那么可以将title建立title_search索引,将title和body建立default组合索引。那么,在title_search上查询即可实现基于标题的搜索,在default上查询即可实现基于标题和内容的综合搜索。 |
| 索引字段 | 在[query子句]中使用,需要定义索引字段,通过索引字段来做高性能的检索召回。 |
| 属性字段 | 在[filter]、[sort]、[aggregate]、[distinct]子句使用,用来实现过滤、统计等功能。 |
| 默认展示字段 | 用来做结果展示。可以通过API参数fetch_fields来控制每次结果的返回字段,需注意在程序中配置fetch_fields该参数后会覆盖默认展示字段配置,以程序中的fetch_fields设置为主;若程序中不设置fetch_fields参数则以默认展示字段为主。 |
| 分词 | 对文档进行词组切分,TEXT类型按检索单元切分,SHORT_TEXT按单字切分。如“浙江大学”,TEXT类型会切分成2个词组:“浙江”、“大学”。SHORT_TEXT会切分成4个词组:“浙”、“江”、“大”、“学”。 |
| term | 分词后的词组称为term。 |
| 构建索引 | 分词后会进行索引构建,以便根据查询请求,快速定位到文档。搜索引擎会构建出两种类型的链表:倒排和正排链表。 |
| 倒排 | 词组到文档的对应关系组成的链表,query子句采用这种排序方式进行查询。例如:term1->doc1,doc2,doc3;term2->doc1,doc2。 |
| 正排 | 文档到字段对应关系组成的链表,filter子句采用这种排序方式,性能略慢于倒排。例如:doc1->id,type,create_time。 |
| 召回 | 通过查询的关键词进行分词,将分词后的词组通过查找倒排链表快速定位到文档。 |
| 召回量 | 召回得到的文档数为召回量。 |
<a name="aLREa"></a>
## 数据同步
| **名称** | **说明** |
| --- | --- |
| 数据源 | 数据来源,目前支持阿里云RDS、MaxCompute、PolarDB的数据同步。 |
| 索引重建 | 重新构建索引。在配置/修改应用结构、数据源后需要索引重建。 |
<a name="wuTSI"></a>
## 配额管理
| **名称** | **说明** |
| --- | --- |
| 文档容量 | 实例中各个表的总文档大小累加值(不考虑字段名,字段内容按照string来计算容量)。 |
| QPS | 每秒查询请求数。 |
| LCU | LCU(逻辑计算单元)是**衡量搜索计算能力的单位**,一个LCU代表搜索集群中1/100个核的计算能力。 |
{"text": "实例管理:名称:实例,说明:实例是用户的一套数据配置,包括数据源结构、索引结构及其它属性配置。一个实例即一个搜索服务。|名称:文档,说明:文档是可搜索的结构化数据单元。文档包含一个或多个字段,但必须有主键字段,OpenSearch通过主键值来确定唯一的文档。主键重复则文档会被覆盖。|名称:字段,说明:字段是文档的组成单元,包含字段名称和字段内容。|名称:插件,说明:为了在导入过程中进行一些数据处理,系统内置了若干数据处理插件,可以在定义应用结构或者配置数据源时选择。|名称:源数据,说明:原始数据,包含一个或多个源字段。|名称:源字段,说明:组成源数据的最小单元,包含字段名称和字段值,可选数据类型请参见应用结构&索引结构。|名称:索引,说明:索引是用于加速检索速度的数据结构,一个实例可以创建多个索引。|名称:组合索引,说明:可将多个TEXT或SHORT_TEXT文本类型的字段配置到同一个索引,用来做组合索引。如一个论坛搜索,需要提供基于标题(title)的搜索及基于标题(title)和内容(body)的综合搜索,那么可以将title建立title_search索引,将title和body建立default组合索引。那么,在title_search上查询即可实现基于标题的搜索,在default上查询即可实现基于标题和内容的综合搜索。|名称:索引字段,说明:在query子句中使用,需要定义索引字段,通过索引字段来做高性能的检索召回。|名称:属性字段,说明:在filter、sort、aggregate、distinct子句使用,用来实现过滤、统计等功能。|名称:默认展示字段,说明:用来做结果展示。可以通过API参数fetch_fields来控制每次结果的返回字段,需注意在程序中配置fetch_fields该参数后会覆盖默认展示字段配置,以程序中的fetch_fields设置为主;若程序中不设置fetch_fields参数则以默认展示字段为主。", "index": 1, "source": {"title": "名词解释", "url": "url"}}
{"text": "实例管理:名称:分词,说明:对文档进行词组切分,TEXT类型按检索单元切分,SHORT_TEXT按单字切分。如“浙江大学”,TEXT类型会切分成2个词组:“浙江”、“大学”SHORT_TEXT会切分成4个词组:“浙”、“江”、“大”、“学”。|名称:term,说明:分词后的词组称为term。|名称:构建索引,说明:分词后会进行索引构建,以便根据查询请求,快速定位到文档。搜索引擎会构建出两种类型的链表:倒排和正排链表。|名称:倒排,说明:词组到文档的对应关系组成的链表,query子句采用这种排序方式进行查询。例如:term1->doc1,doc2,doc3;term2->doc1,doc2。|名称:正排,说明:文档到字段对应关系组成的链表,filter子句采用这种排序方式,性能略慢于倒排。例如:doc1->id,type,create_time。|名称:召回,说明:通过查询的关键词进行分词,将分词后的词组通过查找倒排链表快速定位到文档。|名称:召回量,说明:召回得到的文档数为召回量。", "index": 2, "source": {"title": "名词解释", "url": "url"}}
{"text": "数据同步:名称:数据源,说明:数据来源,目前支持阿里云RDS、MaxCompute、PolarDB的数据同步。|名称:索引重建,说明:重新构建索引。在配置/修改应用结构、数据源后需要索引重建。配额管理:名称:文档容量,说明:实例中各个表的总文档大小累加值(不考虑字段名,字段内容按照string来计算容量)。|名称:QPS,说明:每秒查询请求数。|名称:LCU,说明:LCU(逻辑计算单元)是衡量搜索计算能力的单位,一个LCU代表搜索集群中1/100个核的计算能力。", "index": 3, "source": {"title": "名词解释", "url": "url"}}
2.2.2. 文本向量化模型:ops-text-embedding-001
相比于传统搜索,在与LLM的交互中,很大的一个改变就是用户可以用非常自然的语言,而不是传统搜索中的关键词。对于自然语言化的输入,基于语义的向量检索架构天然契合。
在大模型浪潮的推动下,基于大模型的语义向量模型也给检索领域带来了一次不小的变革。在Massive Text Embedding Benchmark (MTEB)上可以看到以OpenAI的text-embedding-ada-002为代表的一系列基于大模型底座的语义向量模型在检索任务的效果上有着“划时代”的提升。
为了更加适配多语言以及多行业的问答搜索场景,OpenSearch算法团队基于自研语义向量大模型进行了定制训练与效果调优,并对模型效率进行了针对性的优化,以满足搜索场景实时性的需求,最终产出ops-text-embedding-001模型。我们在中文数据集Multi-CPR上做了验证,在检索相关性MRR@10等关键指标上的效果已经优于OpenAI的text-embedding-ada-002:

除了在中文检索效果上的优势,OpenSearch智能问答版的文本向量化模型特点如下:

而在向量检索能力方面,OpenSearch智能问答版内置自研高性能向量检索引擎,擅长处理向量维度更高的大模型场景。
相比于其他开源向量检索引擎,OpenSearch更适配智能搜索场景,可以达到数倍于开源引擎的搜索性能和更高的召回率。
2.2.3. 图像向量化模型:ops-image-embedding-001
对于内容行业而言,尤其是产品文档和文章等内容,大量关键信息以图片的形式呈现,图文结合的多模态展现可以让企业专属智能问答搜索效果大幅提升。
如下图在介绍如何接入OpenSearch产品的时候透出对应的接入流程图,会让用户更直观的理解。

为实现上述图片搜索能力,OpenSearch智能问答版的图像检索模型特点如下:

模型结合多模态的信息,计算Query与文档中图片的图文相关性,最终返回相关性最高的图片作为参考图片结果。
2.3. 大模型(LLM)
2.3.1. 模型训练
有了LLM模型底座后,为了提升模型在检索增强场景下的有效性,减少有害性,OpenSearch智能问答版还对模型进行了有监督的模型微调(Supervised Finetune,SFT)进一步强化检索增强的能力。

具体是使用精心构建的一个检索增强的SFT Dataset,以Query和在对应检索系统下返回的段落组成prompt,Answer作为模型的回答。
对比SFT后的问答搜索模型与原始LLM模型,经过SFT的模型更擅于总结输入文档中的内容,从而精准简练的回答用户问题,达到智能问答搜索效果。
3. 产品能力
3.1. 问答搜索效果演示
为演示OpenSearch智能问答版的效果,我们以阿里云产品文档数据作为业务数据,通过OpenSearch智能问答版搭建问答搜索系统。
以下为问答搜索效果演示:


上述效果演示中,只需将相应的文档数据导入OpenSearch智能问答版,即可根据用户输入的Query返回问答模型生成的答案和相应的参考链接,实现智能问答搜索效果。
相比原系统,基于OpenSearch智能问答版搭建的产品文档问答搜索系统问答准确率可以达到70% 以上,相比原系统同比提升10% 以上,且大幅降低了人工维护成本。
3.2. 知识库干预
此外,针对搜索领域常见的高频Query干预与效果调优问题,OpenSearch智能问答版还支持基于知识库的人工干预。用户可以指定干预问题与对应回答,OpenSearch智能问答版会识别相似问题,并根据知识库中的预设结果给出相应答案,从而实现针对指定Query、活动等场景的运营干预。
如下面的问题,直接给到系统由于文档中找不到相关内容,生成的结果并不能解答:

配上知识库干预之后,同样的问题可以自动通过语义相似度匹配到知识库中预置好的问题,给出对应的干预结果:

3.3. 应用场景
- 企业内部搜索:企业内部资料、文档搜索,相关内容结果生成等场景
- 内容搜索:内容社区、教育搜题等场景,根据问题直接返回对应的答案和相关内容
- 电商、营销行业:围绕产品、价格、需求等问答搜索,回答问题更加精准及时
3.4. 使用流程
(1)获取邀测资格
(2)前往OpenSearch LLM智能问答版售卖页购买实例
(3)通过数据上传API导入业务数据
(4)在控制台测试页或通过API输入Query,获取对应的问答搜索结果
4. 总结与规划
本文介绍了OpenSearch LLM智能问答版的技术实现与能力演示。目前OpenSearch LLM智能问答版已开启邀测,有企业专属问答搜索需求的用户请前往邀测申请获取邀测资格。
未来OpenSearch LLM智能问答版将推出更多行业问答搜索相关功能,支持更多大模型在搜索场景下的应用,敬请期待。