详细情况:
业务反馈:“用int查出来有两条数据,char类型查出来只有一条数据 ,这几个字段还是uk的 ”(版本MySQL 5.7.25)

表结构如下:
CREATE TABLE test_table (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL ,
`master_id` int(11) NOT NULL,
`create_time` datetime NOT NULL ,
`update_time` datetime NOT NULL ,
`version_id` int(11) DEFAULT NULL ,
`device_id` varchar(128) DEFAULT NULL ,
`resource_type` tinyint(4) NOT NULL,
`status` tinyint(4) NOT NULL DEFAULT '0',
`apply_status` tinyint(4) NOT NULL DEFAULT '0',
`pay_status` tinyint(4) NOT NULL DEFAULT '0',
`count` int(11) NOT NULL DEFAULT '0',
`ext` text NOT NULL ,
`idc_region` varchar(20),
PRIMARY KEY (`id`),
UNIQUE KEY `index_user_mid_deviceid_region` (`user_id`,`master_id`,`device_id`,`idc_region`),
KEY `index_apply_user` (`user_id`) USING BTREE,
KEY `index_apply_mid` (`master_id`) USING BTREE
) ENGINE=InnoDB;初步结论:唯一索引未能起到唯一约束作用。
分析
从上面情况来看,有唯一性冲突的数据在表里了,但除了唯一约束的列,其它字段字并不相同,也就是说,两个数据都可能是有效数据,不能删除一条了事,需要确定为什么有唯一索引还能再插入相同值,下次避免同类问题。
询问当时操作的运维同学,这些数据是批量导入的,分析当时binlog,发现导入前关了外键检查和唯一性检查:
SET @@session.foreign_key_checks=0, @@session.unique_checks=0/*!*/;
这两个关闭并不是运维同学手动设置的,是导入工具为了提高导入性能做的默认设置,需要人工保证数据无外键冲突,无唯一键冲突,通常,仅用于对空表导入数据,但本案例中,是对一个已有数据的表导入数据。显然,unique_checks关闭,字面上来看很可能导致重复数据插进去。
但是,当尝试复现时,发现无论怎么unique_checks是开是关,都会检查唯一性,并不能插入数据,因此还有其它条件影响。
深度分析
尝试多种办法,均无法复现,分析对应部分源码:
unique_checks 设置是设置是改变option_bits变量第OPTION_RELAXED_UNIQUE_CHECKS位的值,这个事最终会保存到事务结构trx->check_unique_secondary上:
static Sys_var_bit Sys_unique_checks(//设置参数时影响值
"unique_checks", "unique_checks",
SESSION_VAR(option_bits), NO_CMD_LINE,
REVERSE(OPTION_RELAXED_UNIQUE_CHECKS),
DEFAULT(TRUE), NO_MUTEX_GUARD, IN_BINLOG);
innobase_trx_init(
THD* thd, /*!< in: user thread handle */
trx_t* trx) /*!< in/out: InnoDB transaction handle */
{
trx->check_foreigns = !thd_test_options(
thd, OPTION_NO_FOREIGN_KEY_CHECKS);
trx->check_unique_secondary = !thd_test_options(
thd, OPTION_RELAXED_UNIQUE_CHECKS);//最终保存在此
trx->stats.set(innobase_slow_log_verbose(thd));
DBUG_VOID_RETURN;
}然后在检查后续对这个变量做一次转换保存到search_mode 中:
/* Note that we use PAGE_CUR_LE as the search mode, because then
the function will return in both low_match and up_match of the
cursor sensible values */
if (!thr_get_trx(thr)->check_unique_secondary) {
search_mode |= BTR_IGNORE_SEC_UNIQUE; //保存在此
}再在 btr_cur_search_to_nth_level 函数中,转换成btr_op= BTR_INSERT_IGNORE_UNIQUE_OP,如下:
case BTR_INSERT:
btr_op = (latch_mode & BTR_IGNORE_SEC_UNIQUE)
? BTR_INSERT_IGNORE_UNIQUE_OP
: BTR_INSERT_OP;
break;btr_cur_search_to_nth_level 函数中继续向下看,扫描查找是先在buffer pool中找对应的页面,如果找不到,即block =NULL时,且上面的btr_op为BTR_INSERT_IGNORE_UNIQUE_OP时,才会不检查唯一性,直接插入ibuf中,ibuf就是change buffer:
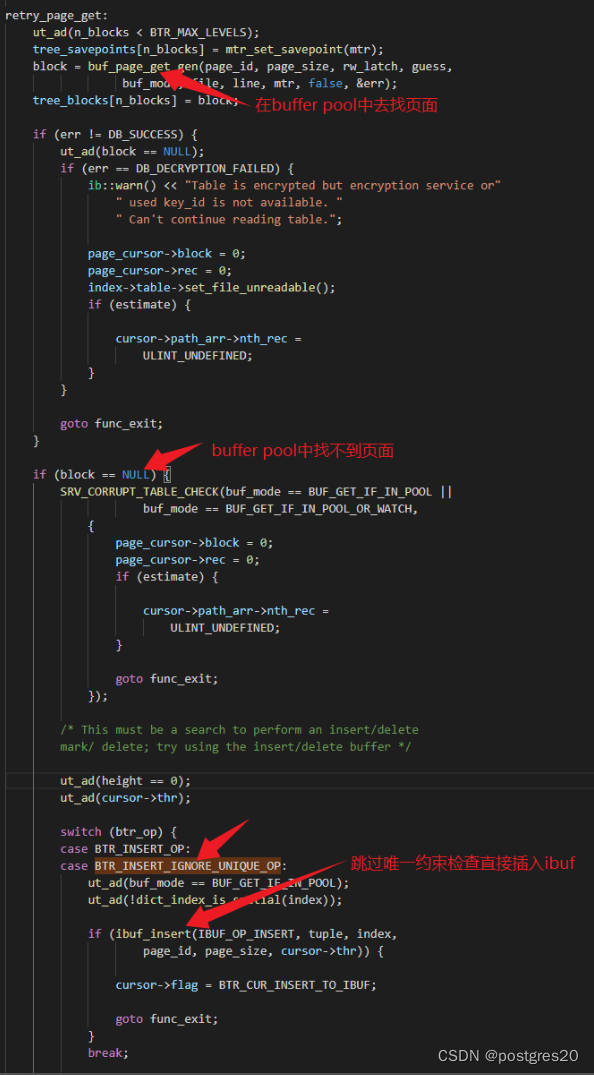
如果能从buffer pool中找到页面,会直接更新,也不会有问题。从源码上分析来看,只有找不到block的这一个路径,会让唯一约束检查失效,全局搜索代码,未发现有其它入口会不检查唯一性直接插入。关于change buffer作用,介绍的文章很多,分享一个链接:
写缓冲(change buffer),这次彻底懂了!!! - 掘金
根因猜测:
因此,从源码上看,满足以下几个条件可能导致这个问题:
- unique_checks=off
- 使用了change buffer(使用change buffer的要求同时要满足)
- 要更新的页刚好不在buffer pool中,如果在buffer pool中就会直接更新,不走changer buffer,不会有问题,详细见上面的changer buffer说明文章。
复现验证:
既然源码上看存在可能性,那么可尝试构造场景复现。
将buffer pool改到很小的200MB,打开change buffer, 关闭unique_checks,对sbtest1表插入10W条件记录,sbtest1表如下:
CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `c` (`c`,`k`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=100002 DEFAULT CHARSET=utf8;插一行记录,直接插入违反唯一约束的值会报错:
insert into sbtest1 values(100001,49898,1234567801,'fdsfsafsdfsfsadfffffffffdfsa');
![]()
对另外一个表插入100W行,将sbtest1表的buffer pool页面淘汰,一会之后再次插入上面内容成功: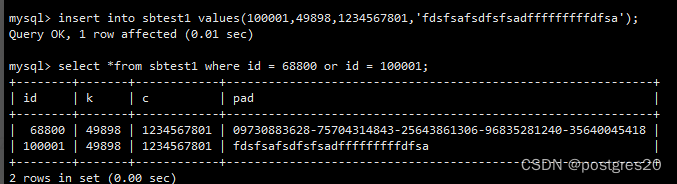
使用数字和字符串查询得到不同结果,与线上问题完全一致,成功复现该bug: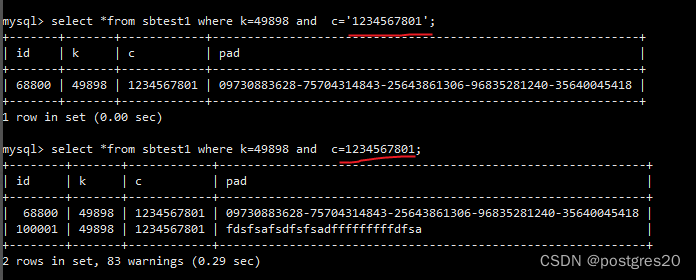
虽然复现了,能插入数据,的确存在了冲突数据,但还有一个小问题,为什么带引号和不带引号结果不一样?
字段c的类型char(120),当带引号是传入值是字符串,会走唯一索引,所以只有一条记录。当不带引号用int查询时, 内部有隐式转换,这个转换会导致唯一索引失效,计划不会走使用这个唯一索引,所以能查出两条。
如何避免此类问题:
检查导入数据工具是否有设置约束参数配置,如果对非空表导入数据,不能去掉相关约束检查,有可能导致数据重复。
可以在导入数据时,手动关闭change buffer,导入完成后再打开。在大批量导入数据时,change buffer并不能优化性能。
补充:当时是用Mydumper导出数据,该工具默认就是foreign_key_checks、unique_checks检查均关闭,且不支持参数设置,那么使用Mydumper导出数据,导入到非空表时,要记得关闭changer buffer。