0.概述
此文章不涉及复杂的理论知识,仅仅只是利用PyTorch组建一个简单的CNN去实现MNIST的手写数字识别,用好的效果去激发学习CNN的好奇心,并且以后以此为基础,去进行一些改造。(前提是把基础代码看明白)
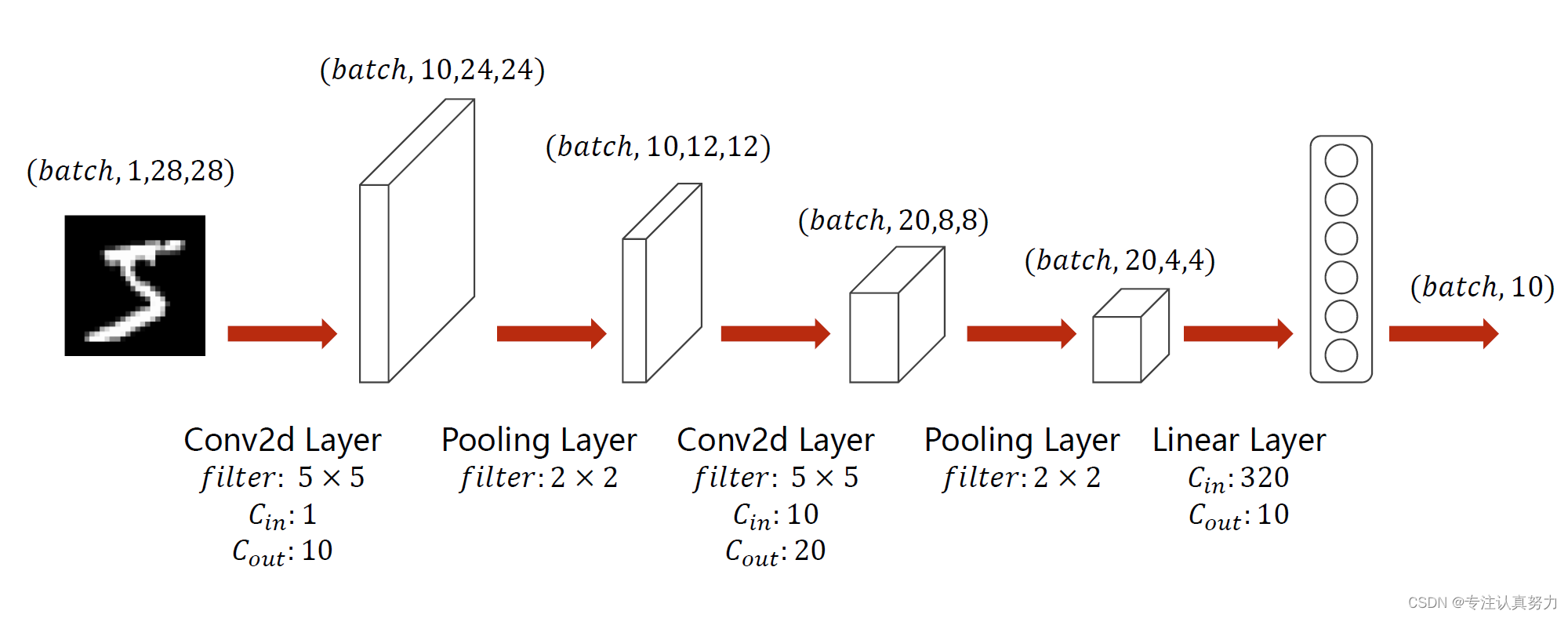
本文CNN网络结构:
以下为最基本的代码(不需要GPU):
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# Super parameter
batch_size = 64
lr = 0.01
momentum = 0.5
epoch = 10
# Prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# Design model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(2),
)
self.fc = nn.Sequential(
nn.Linear(320, 10)
)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(x.size(0), -1) # flatten (batch, 20,4,4) ==> (batch,320)
x = self.fc(x)
return x
model = Net()
# Construct loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)
# Train and Test
def train():
for (images, target) in train_loader:
outputs = model(images)
loss = criterion(outputs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def test():
correct = 0
total = 0
with torch.no_grad():
for (images, target) in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('[%d / %d]: %.1f %% ' % (i + 1, epoch, 100 * correct / total))
# Start train and Test
print('Accuracy on test set:')
for i in range(epoch):
train()
test()
输出结果:
Accuracy on test set:
[1 / 10]: 96.7 %
[2 / 10]: 97.7 %
[3 / 10]: 98.1 %
[4 / 10]: 98.4 %
[5 / 10]: 98.2 %
[6 / 10]: 98.8 %
[7 / 10]: 98.6 %
[8 / 10]: 98.7 %
[9 / 10]: 98.7 %
[10 / 10]: 98.9 %
1.MNIST数据集介绍
1.数据量
MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图像都是28×28的单通道灰度图像,每张图像包含一个手写数字。
2.标注类别
共10个类别,每个类别代表0~9之间的一个数字,每张图像只有一个类别。
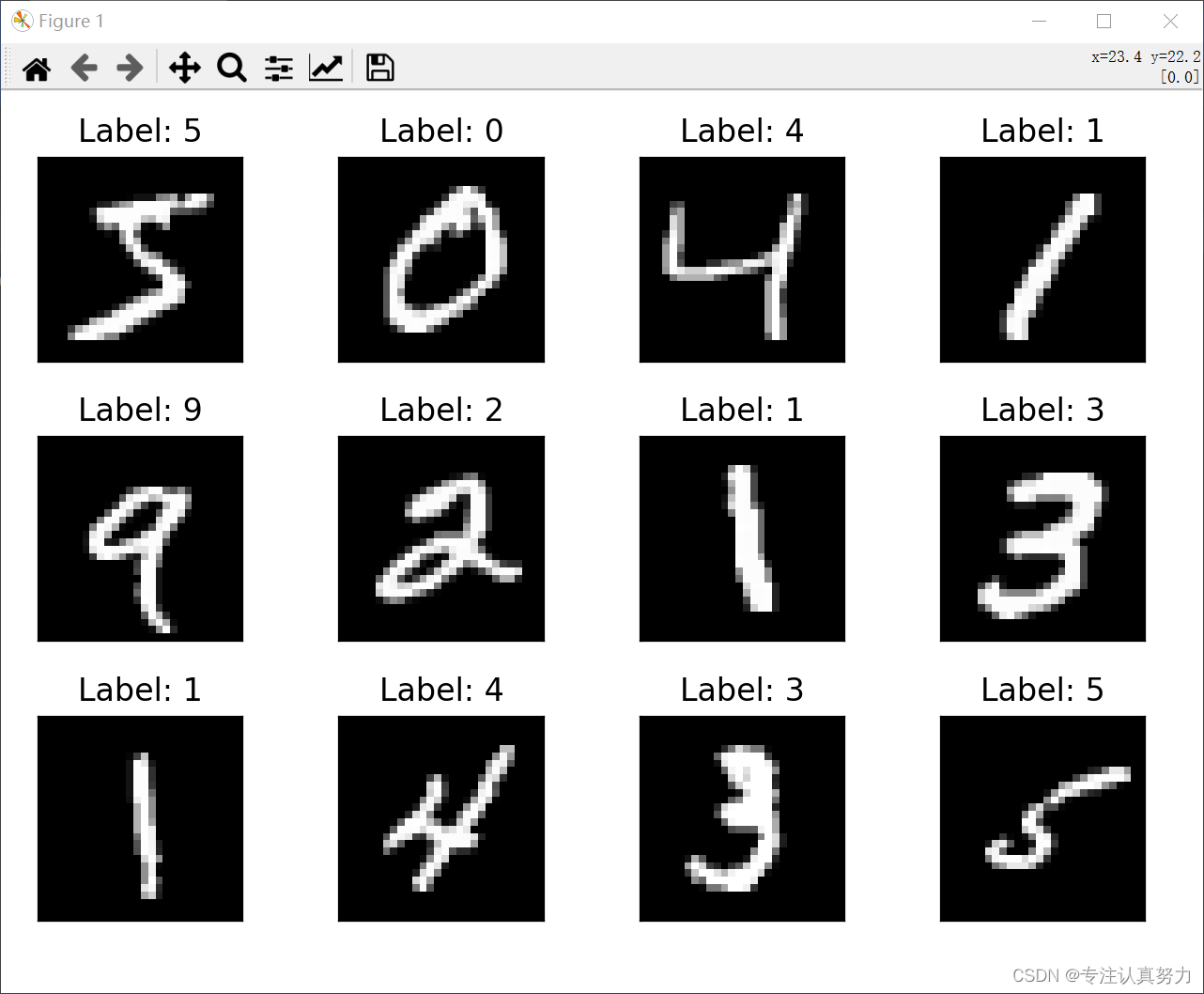
3.可视化
from matplotlib import pyplot as plt
from torchvision import datasets, transforms
# Prepare dataset
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
# View picture
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i + 1)
plt.tight_layout()
plt.imshow(train_dataset.data[i], cmap='gray', interpolation='none')
plt.title("Label: {}".format(train_dataset.targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
4.张量化
二进制压缩文件–>train_dataset->train_loader
# Prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform,download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
1.train_dataset中的数据组织
from torchvision import datasets, transforms
# Prepare dataset
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
# Explore train_dataset
x = train_dataset
print(type(x)) # <class 'torchvision.datasets.mnist.MNIST'>
print(len(x)) # 60000
print(x)
print(type(x[0])) # <class 'tuple'>
print(x[0])
print(len(x[0])) # 2
print(type(x[0][0])) # <class 'torch.Tensor'>
print(type(x[0][1])) # <class 'int'>
print(x[0][0].shape) # torch.Size([1, 28, 28]) 图片
print(x[0][1]) # 5 类别标签
结论:train_dataset是一个含有60000个数据点的Dataset类,每个数据点(如x[0])是一个长度为2的元组,索引0表示图片张量,索引1表示图片的类别标签(0~9)
2.train_loader中的数据组织
同理可得结论: train_loader是一个生成器,我们设置了batch_size是4,所以dataloader会把60000个样本,4个样本一组,按照组的顺序一组一组传给我们,总共938组,每组4张图片和对应标签。每一组的类型是长度为2的list列表,索引0表示一个412828的张量,即把4个图片张量拼在一起,索引1表示一个41的张量,即把4个标签拼在一起。
2.模型设计
图片张量维度的两个变化点:
1.通道数C:卷积层会改变它,1->10->20
2.尺寸W*H:卷积层会小幅改变它,池化层会大幅改变它,28->24->12->8->4
构造模型的两个关注点:
1.卷积层关注前后的通道数变化
2.全连接层关注连接前一张图片的全通道像素数320和连接后的分类标签数10
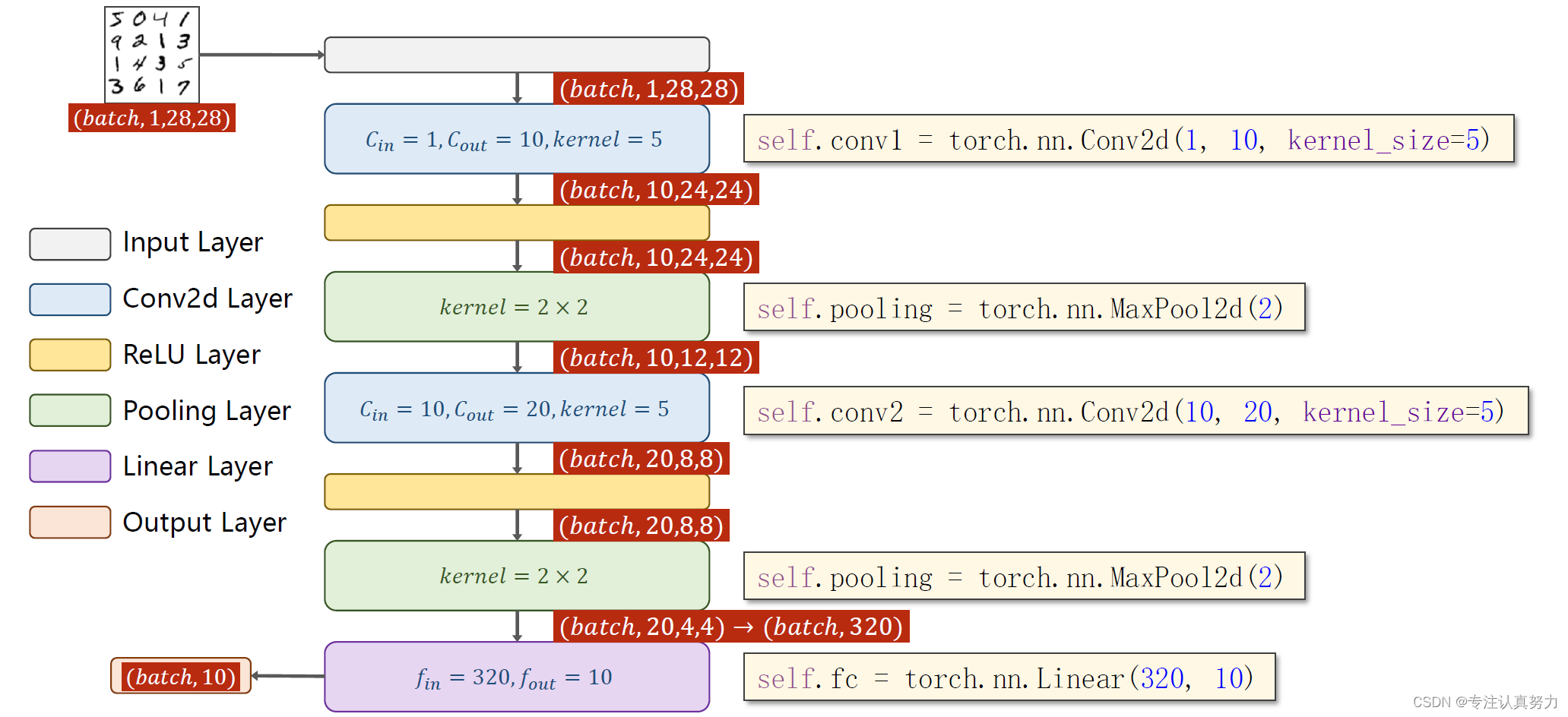
在连接到全连接层之前,将一张图片的所有通道全部展开和连接构成一个一维数组,即2044展开为320个元素组成的数组,经过全连接层将其按权重加和为10个类别标签。
按照模型图代码设计如下:
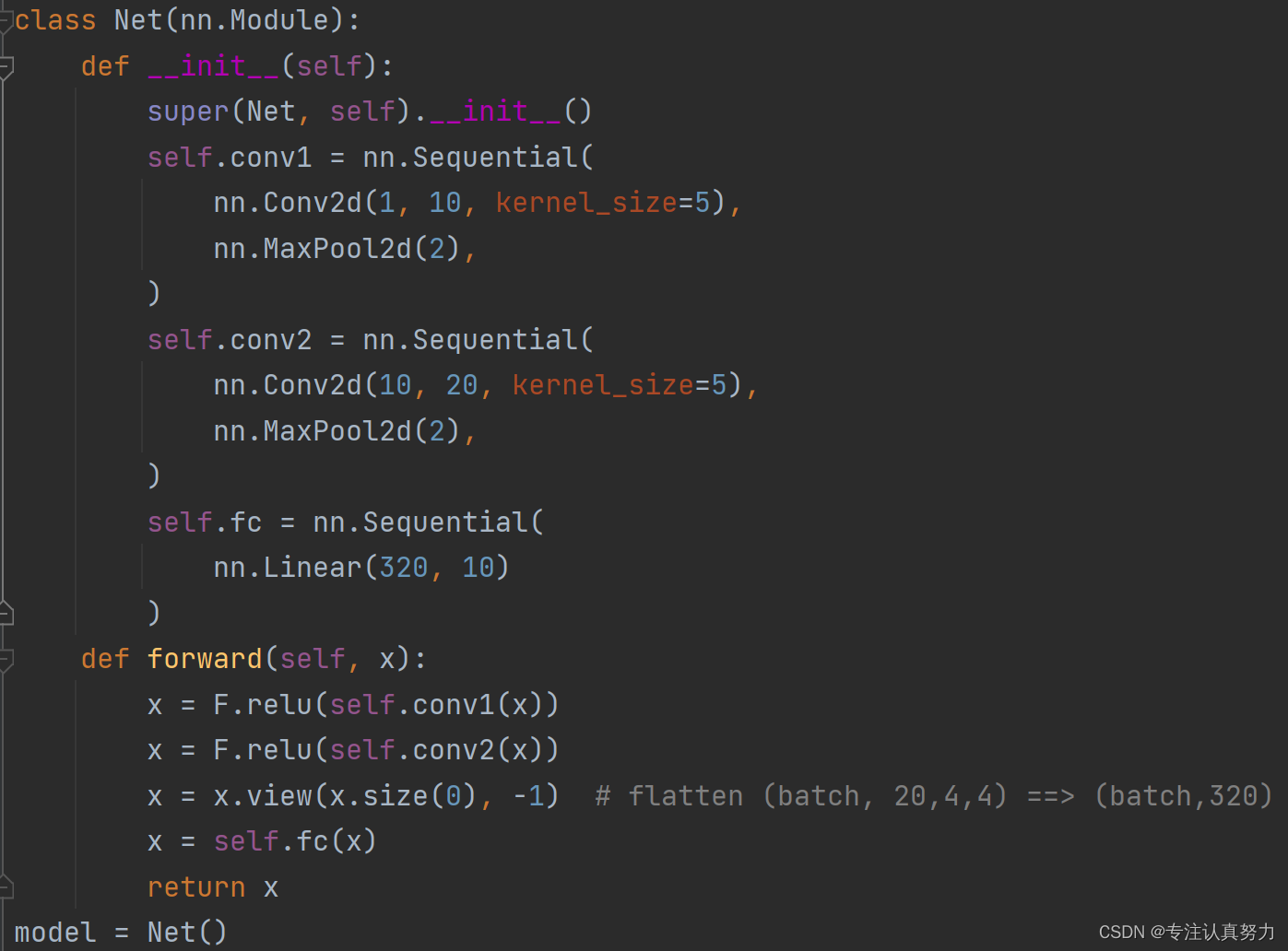
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(2),
)
self.fc = nn.Sequential(
nn.Linear(320, 10)
)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(x.size(0), -1) # flatten (batch, 20,4,4) ==> (batch,320)
x = self.fc(x)
return x
model = Net()
1.torch.nn.Module
Module类是所有神经网络模块的基类,Module可以以树形结构包含其他的Module。Module类中包含网络各层的定义及forward方法,下面介绍我们如何定义自已的网络:
- 需要继承nn.Module类,并实现forward方法;
- 一般把网络中具有可学习参数的层放在构造函数__init__()中;
- 不具有可学习参数的层(如ReLU)可在forward中使用nn.functional来代替;
- 只要在nn.Module的子类中定义了forward函数,利用Autograd自动实现反向求导。
2.super(Net, self).init()
子类Net类继承父类nn.Module,super(Net, self).init()就是对继承自父类nn.Module的属性进行初始化。并且是用nn.Module的初始化方法来初始化继承的属性。也就是:用父类的方法初始化子类的属性。
为什么要用父类的方法去初始化属性呢?原因很简单:因为父类的方法已经写好了,我们只需要调用就可以了。不需要自己写一堆代码去初始化各种权重和参数和处理一堆forward和backward的逻辑。
python中__init()的作用:在python中创建类后,通常会创建一个 init ()方法,这个方法会在创建类的实例的时候自动执行。
3.torch.nn.Sequential()
torch.nn.Sequential 类是 torch.nn 中的一种序列容器,最主要的是,参数会按照我们定义好的序列自动传递下去。
不使用Sequential :

使用Sequential :
输出model结果如下:
Net(
(conv1): Sequential(
(0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=320, out_features=10, bias=True)
)
)
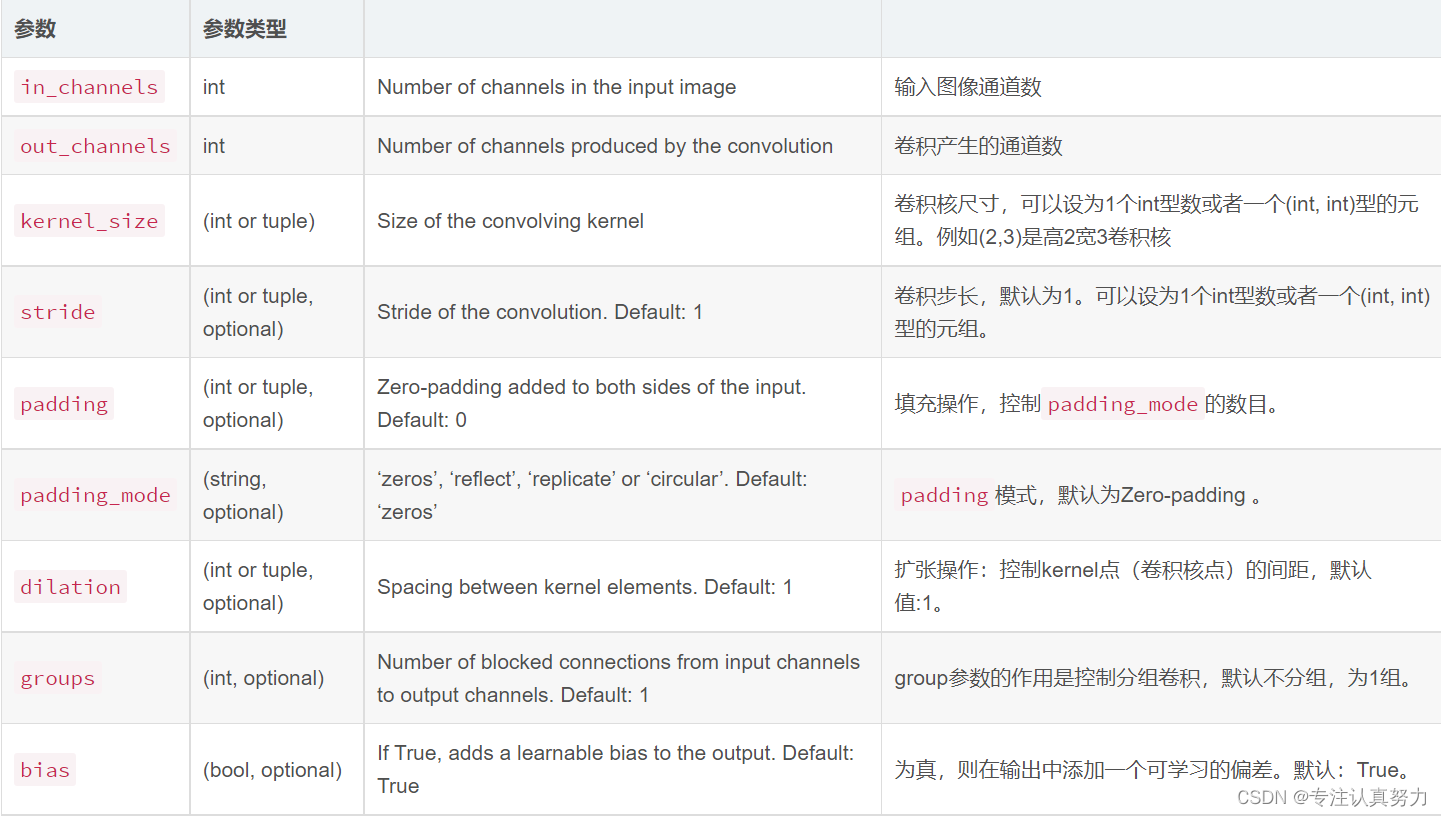
4.torch.nn.Conv2d(1, 10, kernel_size=5)
函数原型:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
参数说明:
5.torch.nn.Linear(320, 10)
函数原型:torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)

6.x = x.view(x.size(0), -1)
作用是将前面多维度的tensor展平成一维。一般出现在model类的forward函数中,具体位置一般都是在调用分类器之前。分类器是一个简单的nn.Linear()结构,输入输出都是维度为1的值。
x.size()为(batch_size,channels,H,W),则x.size(0)=batch_size。
view()函数的功能和reshape类似,用来转换size大小。x = x.view(batchsize, -1)中batchsize指转换后有几行,而-1指在不告诉函数有多少列的情况下,根据原tensor数据和batchsize自动分配列数。
3.训练与测试
1.训练
def train():
for (images, target) in train_loader:
outputs = model(images)
loss = criterion(outputs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
1.获取loss:输入图像和标签,通过infer计算得到预测值,计算损失函数。
2.optimizer.zero_grad() 清空过往梯度。
3.loss.backward() 反向传播,计算当前梯度。
4.optimizer.step() 根据梯度更新网络参数。
2.测试
def test():
correct = 0
total = 0
with torch.no_grad():
for (images,target) in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('[%d / %d]: %.1f %% ' % (i+ 1, epoch, 100 * correct / total))
如何理解_, predicted = torch.max(outputs.data, dim=1)?
torch.max()这个函数返回的是两个值,第一个值是具体的value(我们用下划线_表示),第二个值是value所在的index(也就是predicted)。
在图像分类任务中,值所对应的index就对应着相应的类别class,当我们只关心网络预测的类别是什么,而不关心该类别的预测概率是多少时,就选择使用下划线_。
dim=1表示输出所在行的最大值,若改写成dim=0则输出所在列的最大值。





![[附源码]Python计算机毕业设计SSM金牛社区疫情防控系统(程序+LW)](https://img-blog.csdnimg.cn/417db15b077449b8b45f4073bfec11b4.png)
![[附源码]JAVA毕业设计老年人健康饮食管理系统(系统+LW)](https://img-blog.csdnimg.cn/47bec3a52da948c0b5e07b9a18165cf7.png)
![[附源码]计算机毕业设计车源后台管理系统](https://img-blog.csdnimg.cn/107c4e4b04f84972b751d7ef35584073.png)