一、数据聚合
聚合,可以实现对文档数据的统计、分析、运算。常见的聚合有三类:
①、桶聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组。
- Date Histogram:按照日期解题分组,例如一周为一组,或者一月为一组。
②、度量聚合:用以计算一些值,例如:最大值、最小值、平均值等
- Avg:求平均
- Max:求最大
- Min:求最小
- Stats:同时求最大、最小、平均、合计等
③、管道聚合:其他聚合的结果为基础做聚合
1、桶聚合
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
①对聚合结果进行排序:
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
#聚合功能,自定义展示排序规则
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"_count": "asc"
}
}
}
}
}②、限定聚合范围
#聚合功能,限定聚合范围
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
},
"query": {
"range": {
"price": {
"lte": 200
}
}
}
}③、基于RestAPI实现
@Test
void testAggregation() throws IOException {
//1.准备
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
//2.1、size
request.source().size(0);
//2.2、聚合
request.source().aggregation(AggregationBuilders.terms("brandAgg")
.field("brand")
.size(20)
);
//3.发出结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
//4.1、解析聚合结果
Aggregations aggregations = response.getAggregations();
//4.2、很具名称获取聚合结果
Terms brandAgg = aggregations.get("brandAgg");
//4.3、获取桶
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
//4.4、遍历
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println(brandName + " " + docCount);
}
}2、度量聚合
①、求每个品牌的用户评分的最小值、最大值、平均值(聚合嵌套)
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算
"score_stats": { // 聚合名称
"stats": { // 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}
②、在①的基础上再对显示结果进行按平均值降序排列
#度量聚合_聚合的嵌套_metric
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"scoreAgg.avg": "desc"
}
},
"aggs": {
"scoreAgg": {
"stats": {
"field": "score"
}
}
}
}
}
}3、多条件聚合+带过滤条件的聚合
案例:
在业务层定义方法,实现对品牌、城市、星级的聚合。搜索页面的品牌、城市等信息不应该是写死在页面的,而是通过聚合索引库中的酒店数据得来的。同时,例如当我们选择上海这个城市时,品牌和星级都是根据上海的酒店得来的,因此,我们需要对聚合的对象做限制,也就是我们说的加过滤条件。
@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
Map<String,List<String>> result = new HashMap<>();
List<String> list = new ArrayList<>();
list.add("brand");
list.add("city");
list.add("starName");
for (String s : list) {
//1.准备Request
SearchRequest request = new SearchRequest("hotel");
//2.准备DSL
//2.1、设置size
request.source().size(0);
//2.2、聚合
request.source().aggregation(AggregationBuilders
.terms(s + "Agg")
.field(s).size(20));
//2.3、查询信息
BoolQueryBuilder boolQuery = buildBasicQuery(params);
request.source().query(boolQuery);
//3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
List<String> res = storageResult(response,s);
if (s.equals("city")){
result.put("city",res);
}else if (s.equals("brand")){
result.put("brand",res);
}else {
result.put("starName",res);
}
}
return result;
}catch (Exception e){
throw new RuntimeException(e);
}
}
private List<String> storageResult(SearchResponse response,String aggName) {
List<String> result = new ArrayList<>();
//4.1、解析聚合结果
Aggregations aggregations = response.getAggregations();
//4.2、很具名称获取聚合结果
Terms brandAgg = aggregations.get(aggName + "Agg");
//4.3、获取桶
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
//4.4、遍历
for (Terms.Bucket bucket : buckets) {
String value = bucket.getKeyAsString();
result.add(value);
}
return result;
}二、拼音分词器以及自动补全查询

#自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": { //自定义分词器
"my_analyzer": { //分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { //自定义tokenizer filter
"py": { //过滤器名称
"type": "pinyin",//过滤器类型,这里是拼音
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}案例:酒店系统实现搜索自动补全功能
1、修改索引库数据结构
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}2、导入数据到索引库
①、修改实体类
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
if (this.business.contains("、") || this.business.contains("/")){
//business有多个值,需要切割
String[] arr = new String[10];
if (business.contains("、")){
arr = this.business.split("、");
}else {
arr = this.business.split("/");
}
//添加元素
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion,arr);
}else {
this.suggestion = Arrays.asList(this.brand,this.business);
}
}
}②、导入
//批量新增文档数据
@Test
void testBulkRequest() throws IOException {
//1.创建Request
BulkRequest request = new BulkRequest();
//2.准备Json文档
//批量查询酒店数据
List<Hotel> list = hotelService.list();
for (int i = 0; i < list.size(); i++) {
HotelDoc hotelDoc = new HotelDoc(list.get(i));
request.add(new IndexRequest("hotel").
id(hotelDoc.getId().toString()).
source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
//3.发送请求
client.bulk(request,RequestOptions.DEFAULT);
}3、接口编写
①、controller
@GetMapping("/suggestion")
public List<String> getSuggestion(@RequestParam("key") String prefix){
return hotelService.getSuggestion(prefix);
}②、service
@Override
public List<String> getSuggestion(String prefix) {
try {
//1、准备Request
SearchRequest request = new SearchRequest("hotel");
//2、准备DSL
request.source().suggest(new SuggestBuilder()
.addSuggestion("mySuggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)));
//3、发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析结果
Suggest suggest = response.getSuggest();
//4.1、根据名称获取补全结果
CompletionSuggestion suggestion = suggest.getSuggestion("mySuggestions");
//4.2、获取options并遍历
List<String> result = new ArrayList<>();
for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {
//4.3、获取一个option中的text,也就是补全的此条
String text = option.getText().string();
result.add(text);
}
return result;
} catch (Exception e) {
throw new RuntimeException(e);
}
}三、Es数据与MySQL数据同步
一旦用户对数据库的数据进行了增删改操作后,Es将如何感知到数据发生了变化并进行同步呢?我们有如下几种方案可供我们解决上述问题:
- 异步通知,业务层修改时调用MQ将修改信息发送至队列当中,由ES同步端获取该信息并将更新的数据同步到索引库中。
- 同步更新,业务层修改完成后调用ES同步端的接口,将修改信息发送给该接口,由该接口执行数据同步操作。
- 开启MySQL的binlog并进行监听,一旦数据库当中的数据发生变化,ES同步端则通过监听binlog得知变更信息,之后ES进行数据同步。
针对以上三种,其优缺点如下:

此处我们采用异步通知的方式进行数据同步:
1、声明交换机、队列、routing_key
public class MqConstants {
/**
* 交换机
*/
public static final String EXCHANGE_NAME = "hotel.topic";
/**
* 监听数据新增队列(包括新增和修改)
*/
public static final String INSERT_QUEUE_NAME = "hotel.insert.queue";
/**
* 新增队列routing_key
*/
public static final String INSERT_ROUTING_KEY = "hotel.insert";
/**
* 监听数据删除队列
*/
public static final String DELETE_QUEUE_NAME = "hotel.delete.queue";
/**
* 删除队列routing_key
*/
public static final String DELETE_ROUTING_KEY = "hotel_delete";
}@Configuration
public class MqConfig {
//声明交换机
@Bean("exchange")
public TopicExchange hotelExchange(){
return new TopicExchange(EXCHANGE_NAME);
}
//声明新增队列
@Bean("insertQueue")
public Queue insertQueue(){
return QueueBuilder.durable(INSERT_QUEUE_NAME).build();
}
//声明删除队列
@Bean("deleteQueue")
public Queue deleteQueue(){
return QueueBuilder.durable(DELETE_QUEUE_NAME).build();
}
//新增队列和交换机绑定
@Bean
public Binding insertQueueBinding(@Qualifier("exchange") TopicExchange topicExchange,
@Qualifier("insertQueue") Queue queue){
return BindingBuilder.bind(queue).to(topicExchange).with(INSERT_ROUTING_KEY);
}
//删除队列和交换机绑定
@Bean
public Binding deleteQueueBinding(@Qualifier("exchange") TopicExchange topicExchange,
@Qualifier("deleteQueue") Queue queue){
return BindingBuilder.bind(queue).to(topicExchange).with(DELETE_ROUTING_KEY);
}
}2、处理变更消息发送
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
Long id = hotel.getId();
if (id == null){
buildHotelId.init();
id = Long.valueOf(buildHotelId.hotelId);
hotel.setId(id);
}
hotelService.save(hotel);
rabbitTemplate.convertAndSend(MqConstants.EXCHANGE_NAME,
MqConstants.INSERT_ROUTING_KEY,hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MqConstants.EXCHANGE_NAME,
MqConstants.INSERT_ROUTING_KEY,hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MqConstants.EXCHANGE_NAME,
MqConstants.DELETE_ROUTING_KEY,id);
}3、消息监听+ES数据同步
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/**
* 监听新增或修改信息
* @param id
*/
@RabbitListener(queues = MqConstants.INSERT_QUEUE_NAME)
public void insertData(Long id){
hotelService.insertById(id);
}
/**
* 监听删除信息
* @param id
*/
@RabbitListener(queues = MqConstants.DELETE_QUEUE_NAME)
public void deleteData(Long id){
hotelService.deleteById(id);
}
} @Override
public void insertById(Long id) {
try {
Hotel hotel = getById(id);
HotelDoc doc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(doc.getId().toString());
request.source(JSON.toJSONString(doc), XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void deleteById(Long id) {
try {
DeleteRequest request = new DeleteRequest("hotel", String.valueOf(id));
client.delete(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}四、ES集群部署
0、集群结构介绍
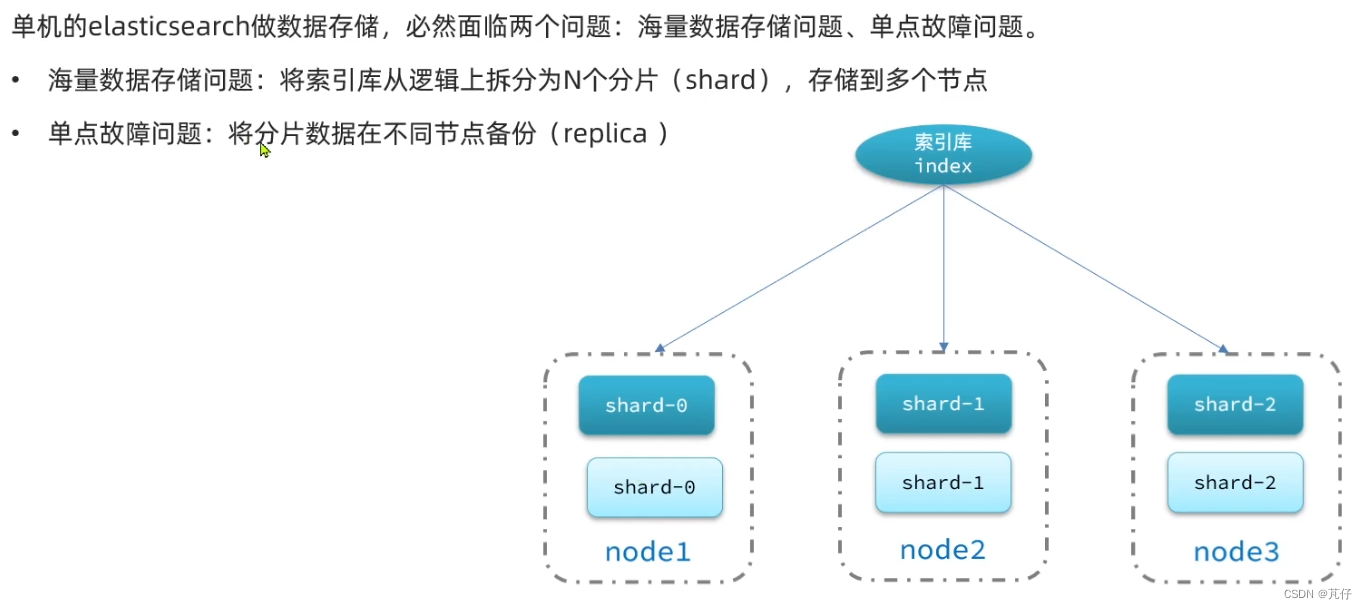
1、集群搭建
①、创建docker-compose.yml文件
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge②、es运行需要修改一些linux系统权限,修改/etc/sysctl.conf文件
vi /etc/sysctl.conf③、添加如下内容
vm.max_map_count=262144④、执行命令,使配置生效
sysctl -p⑤、通过docker-compose启动集群
docker-compose up -d2、集群监控
①、启动监控程序
②、浏览器查看WEB界面
localhost:90003、集群职责及脑裂
①、集群职责
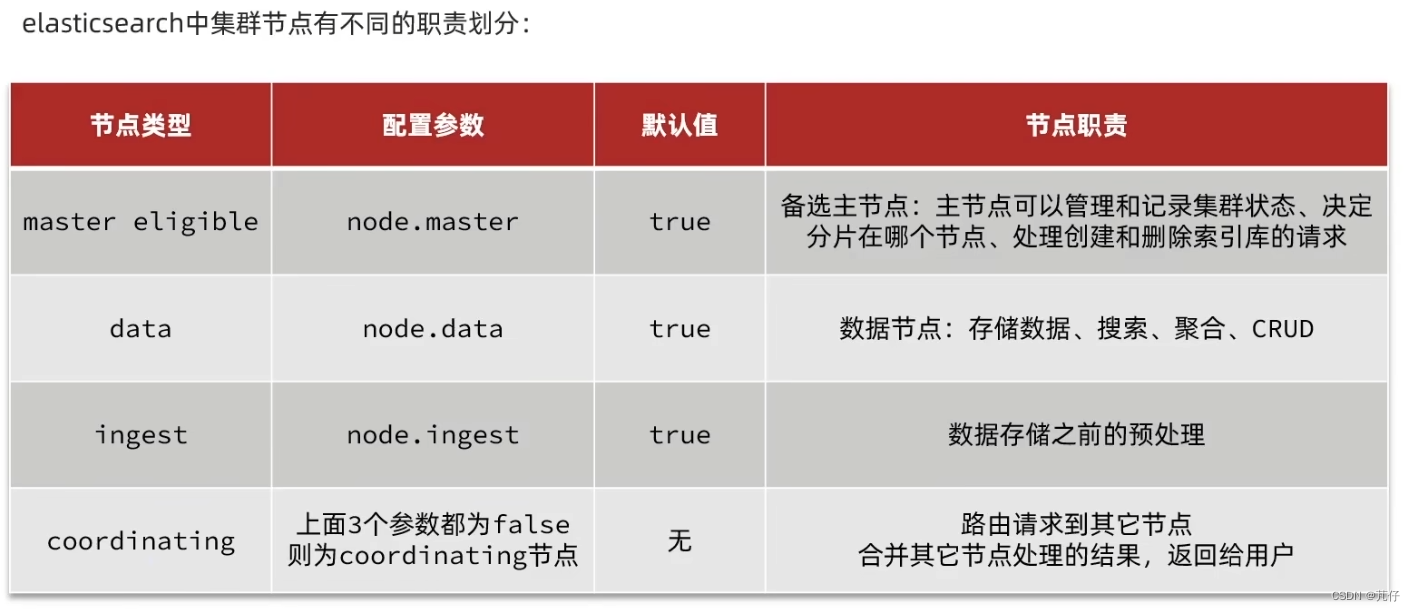
Ⅰ、master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
Ⅱ、data节点的作用是什么?
- 数据的CRUD
Ⅲ、coordinator节点的作用是什么?
- 路由请求到其它节点
- 合并查询到的结果,返回给用户
②、脑裂
默认情况下,每个节点都是master eligible节点,因此一旦master节点宕机,其它候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能发生脑裂问题。 为了避免脑裂,需要要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题。
4、分布式新增和查询
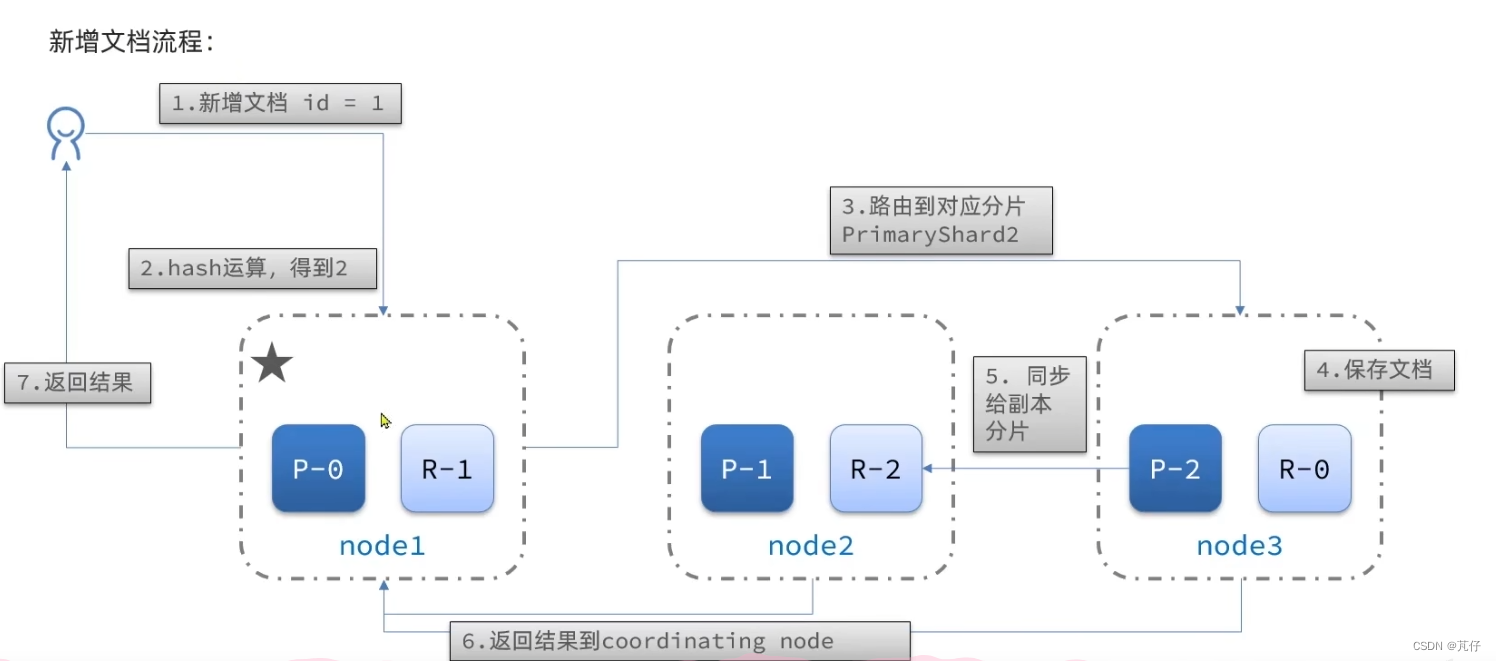
 新增流程:
新增流程:
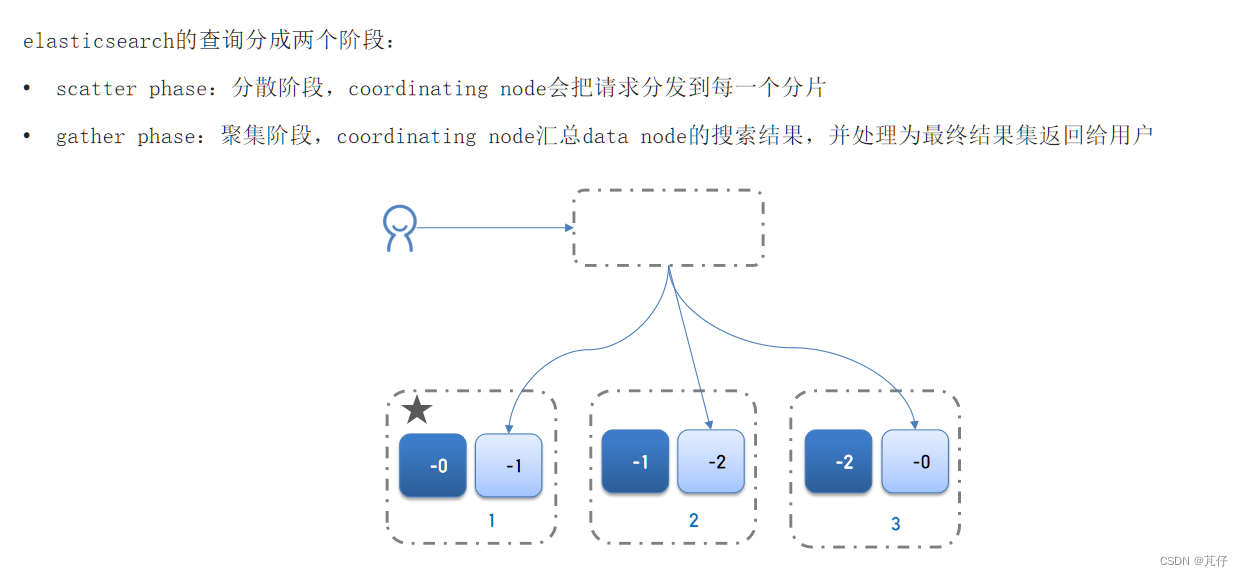
查询流程:
5、ES故障转移
假设有三个节点,node1、node2、node3,node1此时为主节点,node2和node3为备选节点,当node1节点发生故障宕机时,node2节点和node3节点就会进行主节点选举,选举出新的主节点,假设我们的node2节点当选了主节点,此时它就会去检查集群当中分片的状态,参考上图,我们可以看到分片一和分片二的主分片都在,备份分片2和备份分片0也都在,那就缺少了主分片0和备份分片1,此时主节点node2就会把node1节点当中的分片迁移到node2和node3上。