MCMC方法是什么
- 具体而言,假设我们要计算积分 μ = ∫ S h ( θ ) π ( θ ∣ x ) d θ \mu=\int_Sh(\theta)\pi(\theta|x)d\theta μ=∫Sh(θ)π(θ∣x)dθ如果后验分布 π ( θ ∣ x ) \pi(\theta|x) π(θ∣x)难以直接抽样,那么我们就可以构造一条马氏链 θ \theta θ,使其状态空间为 S S S且其平稳分布就是 π ( θ ∣ x ) \pi(\theta|x) π(θ∣x),将此马氏链运行一段时间使其收敛于平稳分布后,将产生一系列服从该平稳分布的随机样本 θ 0 , θ 1 , θ 2 , . . . , θ n − 1 \theta_0,\theta_1,\theta_2,...,\theta_{n-1} θ0,θ1,θ2,...,θn−1,由该定理可得 μ ≈ 1 n ∑ i = 0 n − 1 h ( θ i ) \mu\approx\frac{1}{n}\sum_{i=0}^{n-1}h(\theta_i) μ≈n1i=0∑n−1h(θi)这种以马尔可夫链生成随机样本,通过蒙特卡罗方法进行积分计算的方法就称为马尔可夫链蒙特卡罗算法,即 M C M C MCMC MCMC方法
为什么需要MCMC方法
- 在之前的文章中有提到,接受-拒绝采样方法在高维随机变量的情形下很难找到合适的提议分布 q ( x ) q(x) q(x),而 M C M C MCMC MCMC方法正是为了解决这个问题而生。 M C M C MCMC MCMC方法通过马尔可夫链收敛后的平稳分布产生随机样本,随机变量的维度就是马氏链 X X X的维度,因此无论随机变量的维数是多少,只要马尔可夫链能够收敛, M C M C MCMC MCMC方法都可以很好的工作。
MCMC方法中的若干术语
- 初始值: 初始值被用于初始化一条马氏链
- 预烧期: 在 M C M C MCMC MCMC方法中用于保证马氏链收敛到平稳分布的运行时间,其迭代次数记为 B B B,只要运行的时间足够长,去除预烧期对后验推断几乎是没有影响的
- 筛选间隔或抽样步长: 马氏链产生的样本并不是相互独立的,如果需要独立样本,可以通过监视产生样本的自相关图,然后选择筛选间隔或抽样步长 L L L,使得步长 L L L以后的样本自相关性很低,可近似为独立样本
- 迭代保持数: 指提供给贝叶斯分析的实际样本数,其计算公式为 迭代保持数 = 迭代总次数 − 预烧期的迭代次数 迭代保持数=迭代总次数-预烧期的迭代次数 迭代保持数=迭代总次数−预烧期的迭代次数如果抽样步长 L > 1 L>1 L>1,则 迭代保持数 = 迭代总次数 − 预烧期的迭代次数 L 迭代保持数=\frac{迭代总次数-预烧期的迭代次数}{L} 迭代保持数=L迭代总次数−预烧期的迭代次数
- 蒙特卡罗误差: 度量了每一个估计因为随机模拟而导致的波动性,计算方法略
利用MCMC的输出结果描述目标后验分布
- MCMC输出结果给我们提供了一系列随机样本
θ
1
,
θ
2
,
θ
3
,
.
.
.
,
θ
n
\theta_1,\theta_2,\theta_3,...,\theta_n
θ1,θ2,θ3,...,θn这组样本可以等价地看作从目标后验分布
π
(
θ
∣
x
)
\pi(\theta|x)
π(θ∣x)中生成的样本,因此,我们就可以通过这组样本计算后验分布的数字特征,包括但不限于以下所列:
- 后验期望: μ π ( θ ) = ∑ i = 1 n θ i n \mu^\pi(\theta)=\frac{\sum_{i=1}^n\theta_i}{n} μπ(θ)=n∑i=1nθi
- 后验方差: V π ( θ ) = ∑ i = 1 n [ θ i − μ π ( θ ) ] 2 n V^\pi(\theta)=\frac{\sum_{i=1}^n[\theta_i-\mu^\pi(\theta)]^2}{n} Vπ(θ)=n∑i=1n[θi−μπ(θ)]2
- 后验众数: 在生成的后验密度图中使得后验密度达到最大的点 θ m o d e \theta_{mode} θmode(不等于 m a x { θ 1 , θ 2 , θ 3 , . . . , θ n } max\{\theta_1,\theta_2,\theta_3,...,\theta_n\} max{θ1,θ2,θ3,...,θn}!!)
- 进一步地,如果我们要应用
M
C
M
C
MCMC
MCMC方法的采样结果解决其它问题,那么原理也是相同,下面提供一个一般化的使用
M
C
M
C
MCMC
MCMC方法解决贝叶斯预测推断问题的例子:
- 假设历史样本 X X X服从一个参数为 θ \theta θ的分布 f ( x ∣ θ ) f(x|\theta) f(x∣θ), θ \theta θ的先验分布为 π ( θ ) \pi(\theta) π(θ),现在要求随机变量 Z ∼ g ( z ∣ θ ) Z\sim g(z|\theta) Z∼g(z∣θ)的后验预测密度
- 按照贝叶斯预测推断的解题步骤,首先应该根据样本似然与先验分布求出后验分布,然后应用后验分布求出 Z Z Z的后验预测密度。 θ \theta θ的后验分布按照如下公式计算 π ( θ ∣ x ) = f ( x ∣ θ ) π ( θ ) ∫ θ f ( x ∣ θ ) π ( θ ) d θ \pi(\theta|x)=\frac{f(x|\theta)\pi(\theta)}{\int_\theta f(x|\theta)\pi(\theta)d\theta} π(θ∣x)=∫θf(x∣θ)π(θ)dθf(x∣θ)π(θ)则 Z Z Z的后验预测密度为 m ( z ) = ∫ θ g ( z ∣ θ ) π ( θ ∣ x ) d θ m(z)=\int_\theta g(z|\theta)\pi(\theta|x)d\theta m(z)=∫θg(z∣θ)π(θ∣x)dθ假设这是一个难以计算的积分,那么应用 M C M C MCMC MCMC方法,得到一组基于后验分布采样得到的随机样本 θ 1 , θ 2 , θ 3 , . . . , θ n \theta_1,\theta_2,\theta_3,...,\theta_n θ1,θ2,θ3,...,θn,此时就有 m ( z ) ≈ ∑ i = 1 n g ( z ∣ θ i ) n m(z)\approx\frac{\sum_{i=1}^ng(z|\theta_i)}{n} m(z)≈n∑i=1ng(z∣θi)
马氏链收敛性诊断
- 样本路径图: 根据马氏链的迭代次数对生成的样本值作图,如果所有的值都在一个区域里,且没有明显的周期性和趋势性,则认为收敛性已经达到
MCMC采样方法
- 由于一般情况下,随机构造的一个马尔科夫链状态转移矩阵 Q Q Q不满足细致平稳条件,即 π i Q i j ≠ π j Q j i \pi_iQ_{ij}\ne\pi_jQ_{ji} πiQij=πjQji因此 M C M C MCMC MCMC方法对上式做了一个改造,使得细致平稳条件恒成立,具体做法是引入了一个 α \alpha α,即 π i Q i j α ( i , j ) = π j Q j i α ( j , i ) \pi_iQ_{ij}\alpha(i,j)=\pi_jQ_{ji}\alpha(j,i) πiQijα(i,j)=πjQjiα(j,i)
- 问题是什么样的 α ( i , j ) α(i,j) α(i,j)可以使等式成立呢?其实很简单,只要满足下两式即可: { α ( i , j ) = π j Q j i α ( j , i ) = π i Q i j \left\{ \begin{array}{} α(i,j)=π_jQ_{ji}\\ α(j,i)=π_iQ_{ij}\\ \end{array}\right. {α(i,j)=πjQjiα(j,i)=πiQij这样我们就得到了转移矩阵 P P P P ( i , j ) = Q ( i , j ) α ( i , j ) P(i,j)=Q(i,j)α(i,j) P(i,j)=Q(i,j)α(i,j)也就是说,我们的目标矩阵 P P P可以通过任意一个马尔科夫链状态转移矩阵 Q Q Q乘以 α ( i , j ) α(i,j) α(i,j)得到。 α ( i , j ) α(i,j) α(i,j)我们一般称之为接受率,取值在 [ 0 , 1 ] [0,1] [0,1]之间,可以理解为一个概率值,即目标矩阵 P P P可以通过任意一个马尔科夫链状态转移矩阵 Q Q Q以一定的接受率 α \alpha α获得。
- 这个很像接受-拒绝采样,它是以一个提议分布的采样结果通过一定的接受-拒绝概率近似一个复杂分布的采样结果,这里是以一个常见的马尔科夫链状态转移矩阵 Q Q Q通过一定的接受-拒绝概率得到目标转移矩阵 P P P,两者的解决问题思路是类似的。
- 我们在MCMC采样方法中同样引入一个提议分布,用于近似转移矩阵的条件概率分布,即 g ( x ∗ ∣ x ) = Q ( x ∗ ∣ x ) g(x^*|x)=Q(x^*|x) g(x∗∣x)=Q(x∗∣x)用于在马氏链的前一个状态为 x x x的条件下,采样生成新的转移状态 x ∗ x^* x∗的概率分布
-
M
C
M
C
MCMC
MCMC采样步骤:
- 输入我们选定的提议分布 g ( x ∣ x t ) g(x|x_t) g(x∣xt),平稳分布 π ( x ) π(x) π(x),设定预烧期 B B B,迭代保持数 T T T
- 从任意简单概率分布采样得到初始值 x 0 x_0 x0
- for
t
=
0
t=0
t=0 to
B
+
T
−
1
B+T-1
B+T−1:
- 由提议分布 g ( x ∣ x t ) g(x|x_t) g(x∣xt)中采样得到样本 x ∗ x^∗ x∗
- 从均匀分布 U ( 0 , 1 ) U(0,1) U(0,1)采样得到 u 0 u_0 u0
- 如果 u 0 < α ( x t , x ∗ ) = π ( x ∗ ) g ( x ∗ ∣ x t ) u_0<\alpha(x_t,x^*)=\pi(x^*)g(x^*|x_t) u0<α(xt,x∗)=π(x∗)g(x∗∣xt),则接受转移,即 x t + 1 = x ∗ x_{t+1}=x^* xt+1=x∗,否则不接受转移,即 x t + 1 = x t x_{t+1}=x_t xt+1=xt
- 最终样本集 ( x B , x B + 1 , . . . , x B + T − 1 ) (x_{B},x_{B+1},...,x_{B+T-1}) (xB,xB+1,...,xB+T−1)便是我们所需要的从平稳分布中采集的样本。
- 上面这个过程基本上就是 M C M C MCMC MCMC采样的完整采样理论了,但是这个采样算法还是比较难在实际中应用,为什么呢?问题就出在上面的步骤3,由于 α ( x t , x ∗ ) α(x_t,x^∗) α(xt,x∗)可能非常的小,比如0.1,导致我们大部分的采样值都被拒绝转移,采样效率很低。有可能我们采样了上百万次马尔可夫链还没有收敛,怎么办呢?这时就轮到我们的 M − H M-H M−H采样出场了。
Metropolis-Hastings算法
- 我们回到
M
C
M
C
MCMC
MCMC采样的细致平稳条件:
π
i
Q
i
j
α
(
i
,
j
)
=
π
j
Q
j
i
α
(
j
,
i
)
\pi_iQ_{ij}\alpha(i,j)=\pi_jQ_{ji}\alpha(j,i)
πiQijα(i,j)=πjQjiα(j,i)我们采样效率低的原因是
α
(
i
,
j
)
α(i,j)
α(i,j)太小了,我们假设
α
(
i
,
j
)
α(i,j)
α(i,j)为0.1,而
α
(
j
,
i
)
α(j,i)
α(j,i)为0.2。即
π
i
Q
i
j
×
0.1
=
π
j
Q
j
i
×
0.2
π_iQ_{ij}×0.1=π_jQ_{ji}×0.2
πiQij×0.1=πjQji×0.2这时我们可以看到,如果两边同时扩大五倍,接受率提高到了0.5,细致平稳条件却仍然是满足的,即
π
i
Q
i
j
×
0.5
=
π
j
Q
j
i
×
1
π_iQ_{ij}×0.5=π_jQ_{ji}×1
πiQij×0.5=πjQji×1因此,我们可以通过类似的方式增大接受率,对接受率做如下改进,即
α
(
i
,
j
)
=
m
i
n
{
π
j
Q
j
i
π
i
Q
i
j
,
1
}
α(i,j)=min\{\frac{π_jQ_{ji}}{π_iQ_{ij}},1\}
α(i,j)=min{πiQijπjQji,1}
通过这个微小的改造,我们就得到了可以在实际应用中使用的 M e t r o p o l i s − H a s t i n g s Metropolis-Hastings Metropolis−Hastings算法. - 算法过程如下:
- 输入我们选定的提议分布 g ( x ∣ x t ) g(x|x_t) g(x∣xt),平稳分布 π ( x ) π(x) π(x),设定预烧期 B B B,迭代保持数 T T T
- 从任意简单概率分布采样得到初始值 x 0 x_0 x0
- for
t
=
0
t=0
t=0 to
B
+
T
−
1
B+T-1
B+T−1:
- 由提议分布 g ( x ∣ x t ) g(x|x_t) g(x∣xt)中采样得到样本 x ∗ x^∗ x∗,每次迭代将会根据上一状态 x t x_t xt对提议分布做出更新
- 从均匀分布 U ( 0 , 1 ) U(0,1) U(0,1)采样得到 u 0 u_0 u0
- 如果 u 0 < α ( x t , x ∗ ) = π ( x ∗ ) g ( x t ∣ x ∗ ) π ( x t ) g ( x ∗ ∣ x t ) u_0<\alpha(x_t,x^*)=\frac{π(x^*)g(x_t|x^*)}{π(x_t)g(x^*|x_t)} u0<α(xt,x∗)=π(xt)g(x∗∣xt)π(x∗)g(xt∣x∗)(由于 u 0 u_0 u0本身就采样自 U ( 0 , 1 ) U(0,1) U(0,1),因此一定小于1),则接受转移,即 x t + 1 = x ∗ x_{t+1}=x^* xt+1=x∗,否则不接受转移,即 x t + 1 = x t x_{t+1}=x_t xt+1=xt
- 最终样本集 ( x B , x B + 1 , . . . , x B + T − 1 ) (x_{B},x_{B+1},...,x_{B+T-1}) (xB,xB+1,...,xB+T−1)便是我们所需要的从平稳分布中采集的样本。
Metropolis抽样方法
-
M
e
t
r
o
p
o
l
i
s
−
H
a
s
t
i
n
g
s
Metropolis-Hastings
Metropolis−Hastings抽样方法是
M
e
t
r
o
p
o
l
i
s
Metropolis
Metropolis抽样方法的推广,
M
e
t
r
o
p
o
l
i
s
Metropolis
Metropolis抽样方法的不同之处主要还是在于接受率:
- 在 M e t r o p o l i s Metropolis Metropolis抽样方法中,我们假设提议分布 g ( x ∗ ∣ x ) g(x^*|x) g(x∗∣x)是对称的,即满足 g ( x ∣ x ∗ ) = g ( x ∗ ∣ x ) g(x|x^*)=g(x^*|x) g(x∣x∗)=g(x∗∣x),这时我们的接受率可以进一步简化为 α ( i , j ) = m i n { π j π i , 1 } α(i,j)=min\{\frac{π_j}{π_i},1\} α(i,j)=min{πiπj,1}
随机游动的Metropolis算法
- 随机游动的 M e t r o p o l i s Metropolis Metropolis算法又是 M e t r o p o l i s Metropolis Metropolis抽样方法的一个特例,随机游动的 M e t r o p o l i s Metropolis Metropolis算法的不同之处在于对马氏链生成新的状态的方式做出了改变
- 具体而言,随机游动的 M e t r o p o l i s Metropolis Metropolis算法的提议分布仍然满足对称性,即提议分布 g g g满足 g ( x ∣ x ∗ ) = g ( x ∗ ∣ x ) g(x|x^*)=g(x^*|x) g(x∣x∗)=g(x∗∣x)但我们生成 x ∗ x^* x∗的方式有所不同,我们引入了一个随机增量 Z Z Z, Z Z Z从原始的提议分布 g ( ⋅ ) g(·) g(⋅)产生,然后令 x ∗ = x t + Z x^*=x_t+Z x∗=xt+Z,这就要求提议分布满足 g ( x ∗ ∣ x ) = g ( x ∗ − x ∣ x ) = g ( Z ) g(x^*|x)=g(x^*-x|x)=g(Z) g(x∗∣x)=g(x∗−x∣x)=g(Z)显然,提议分布 g g g需要满足平移不变性
- 随机游动的
M
e
t
r
o
p
o
l
i
s
Metropolis
Metropolis算法具体步骤如下:
- 输入我们选定的提议分布 g ( ⋅ ) g(·) g(⋅),平稳分布 π ( x ) π(x) π(x),设定预烧期 B B B,迭代保持数 T T T
- 从任意简单概率分布采样得到初始值 x 0 x_0 x0
- for
t
=
0
t=0
t=0 to
B
+
T
−
1
B+T-1
B+T−1:
- 由提议分布 g ( ⋅ ) g(·) g(⋅)中采样得到随机增量 Z Z Z,令 x ∗ = x t + Z x^∗=x_t+Z x∗=xt+Z
- 从均匀分布 U ( 0 , 1 ) U(0,1) U(0,1)采样得到 u 0 u_0 u0
- 如果 u 0 < α ( x t , x ∗ ) = π ( x ∗ ) π ( x t ) u_0<\alpha(x_t,x^*)=\frac{π(x^*)}{π(x_t)} u0<α(xt,x∗)=π(xt)π(x∗)(由于 u 0 u_0 u0本身就采样自 U ( 0 , 1 ) U(0,1) U(0,1),因此一定小于1),则接受转移,即 x t + 1 = x ∗ x_{t+1}=x^* xt+1=x∗,否则不接受转移,即 x t + 1 = x t x_{t+1}=x_t xt+1=xt
- 最终样本集 ( x B , x B + 1 , . . . , x B + T − 1 ) (x_{B},x_{B+1},...,x_{B+T-1}) (xB,xB+1,...,xB+T−1)便是我们所需要的从平稳分布中采集的样本。
- 随机游动的
M
e
t
r
o
p
o
l
i
s
Metropolis
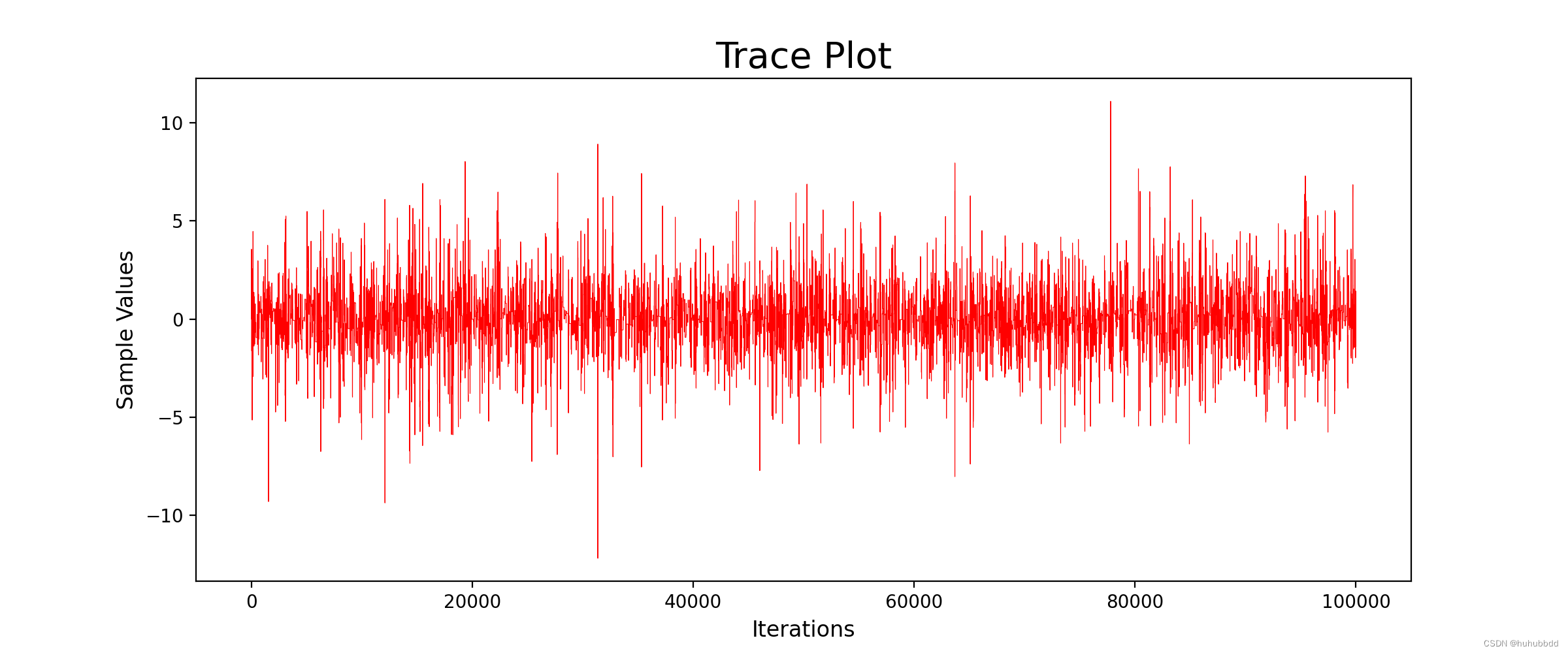
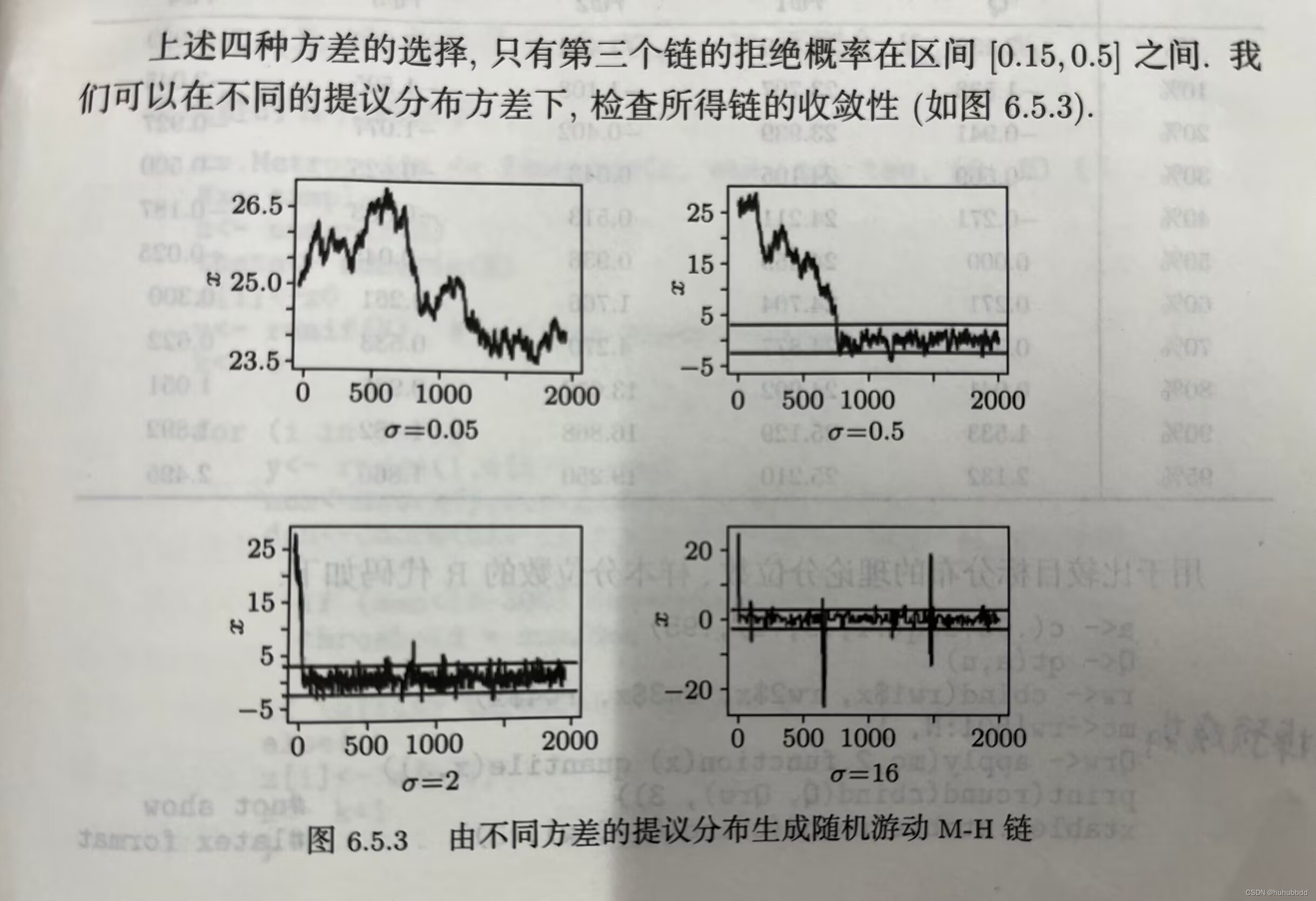
Metropolis算法对随机增量的方差比较敏感,当增量的方差太大时,大部分的候选点会被拒绝,而增量方差太小时,候选点就几乎都被接受。一种好的解决办法是监视拒绝概率,当拒绝概率在区间
[
0.15
,
0.5
]
[0.15,0.5]
[0.15,0.5]之内才可以保证得到的马氏链具备较好的性质,下面是一个示例,假设随机增量
Z
Z
Z从提议分布
N
(
0
,
σ
2
)
N(0,\sigma^2)
N(0,σ2)中产生,当
σ
\sigma
σ取值不同时,生成的马氏链如图
随机游动的 M e t r o p o l i s Metropolis Metropolis算法与 M e t r o p o l i s − H a s t i n g s Metropolis-Hastings Metropolis−Hastings算法在代码实现上的差异
-
M e t r o p o l i s − H a s t i n g s Metropolis-Hastings Metropolis−Hastings算法
for i in range(1,m): xt=x[i-1] g=gamma(xt,1) y=g.rvs() num=f.pdf(y)*gamma(y,1).pdf(xt) den=f.pdf(xt)*gamma(xt,1).pdf(y) if u[i-1]<=num/den: x[i]=y else: x[i]=x[i-1] k=k+1 -
随机游动的 M e t r o p o l i s Metropolis Metropolis算法
for i in range(1,m): xt=x[i-1] y=g.rvs()+xt num=f.pdf(y) den=f.pdf(xt) if u[i-1]<=num/den: x[i]=y else: x[i]=x[i-1] k+=1
G i b b s Gibbs Gibbs抽样方法
-
G i b b s Gibbs Gibbs抽样是 M e t r o p o l i s − H a s t i n g s Metropolis-Hastings Metropolis−Hastings算法的另一种特殊情形,它特别适合于目标分布是多元的情形,它将从多元目标分布中抽样转化为了从一元目标分布抽样,固定n−1个特征在某一个特征采样,这便是 G i b b s Gibbs Gibbs抽样的重要性所在
-
定义: 令 X = ( X 1 , X 2 , X 3 , . . . , X k ) X=(X_1,X_2,X_3,...,X_k) X=(X1,X2,X3,...,Xk)为 k k k维随机变量,其联合分布 π ( x ) = π ( x 1 , x 2 , x 3 , . . . , x k ) \pi(x)=\pi(x_1,x_2,x_3,...,x_k) π(x)=π(x1,x2,x3,...,xk)为目标抽样分布,定义 k − 1 k-1 k−1维随机变量 X − j = ( X 1 , . . . , X j − 1 , x j + 1 , . . . , X k ) X_{-j}=(X_1,...,X_{j-1},x_{j+1},...,X_k) X−j=(X1,...,Xj−1,xj+1,...,Xk)并记 X j ∣ X − j X_j|X_{-j} Xj∣X−j的满条件分布的概率密度为 π ( x ) = π ( x j ∣ x − j ) , j = 1 , 2 , 3 , . . . , k \pi(x)=\pi(x_j|x_{-j}),j=1,2,3,...,k π(x)=π(xj∣x−j),j=1,2,3,...,k,则 G i b b s Gibbs Gibbs抽样就是从这k个条件分布中产生候选点,以解决直接从 f f f中进行抽样的困难,该算法步骤如下:
- 输入平稳分布 π ( x 1 , x 2 , . . . , x n ) π(x_1,x_2,...,x_n) π(x1,x2,...,xn)或者对应的所有特征的条件概率分布,设定预烧期为 B B B,迭代保持数为 T T T
- 在 t = 0 t=0 t=0时,初始化 X i ( 0 ) ( i = 1 , 2 , . . . , k ) X^{(0)}_i(i=1,2,...,k) Xi(0)(i=1,2,...,k)(我们记 X i ( t ) X^{(t)}_i Xi(t)为 X i X_i Xi在第 t t t 次迭代下的情形)
- for
t
=
0
t=0
t=0 to
B
+
T
−
1
B+T−1
B+T−1:
- 从条件概率分布 P ( x 1 ∣ x 2 ( t ) , x 3 ( t ) , . . . , x k ( t ) ) P(x_1|x^{(t)}_2,x^{(t)}_3,...,x^{(t)}_k) P(x1∣x2(t),x3(t),...,xk(t))中采样得到样本 x 1 t + 1 x^{t+1}_1 x1t+1
- 从条件概率分布 P ( x 2 ∣ x 1 ( t + 1 ) , x 3 ( t ) , x 4 ( t ) , . . . , x k ( t ) ) P(x_2|x^{(t+1)}_1,x^{(t)}_3,x^{(t)}_4,...,x^{(t)}_k) P(x2∣x1(t+1),x3(t),x4(t),...,xk(t))中采样得到样本 x 2 t + 1 x^{t+1}_2 x2t+1
- …
- 从条件概率分布 P ( x k ∣ x 1 ( t + 1 ) , x 2 ( t + 1 ) , . . . , x k − 1 ( t + 1 ) ) P(x_k|x^{(t+1)}_1,x^{(t+1)}_2,...,x^{(t+1)}_{k−1}) P(xk∣x1(t+1),x2(t+1),...,xk−1(t+1))中采样得到样本 x k ( t + 1 ) x^{(t+1)}_k xk(t+1)
- 样本集 { ( x 1 ( B ) , x 2 ( B ) , . . . , x k ( B ) ) , . . . , ( x 1 ( B + T − 1 ) , x 2 ( B + T − 1 ) , . . . , x k ( B + T − 1 ) ) } \{(x^{(B)}_1,x^{(B)}_2,...,x^{(B)}_k),...,(x^{(B+T-1)}_1,x^{(B+T-1)}_2,...,x^{(B+T-1)}_k)\} {(x1(B),x2(B),...,xk(B)),...,(x1(B+T−1),x2(B+T−1),...,xk(B+T−1))}即为我们需要的平稳分布对应的样本集。
-
一个示例:

代码:import numpy as np from scipy.stats import uniform,binom,beta import matplotlib.pyplot as plt # 定义马氏链长度 m=10000 # 定义预烧期 burn=1000 # 初始化一条二维[xy]的马氏链 x=np.zeros((m,2)) n=50;a=1;b=1 # 由于二项分布取值在0-1之间,故在U(0,1)上随机产生一个数值 x[0,0]=uniform(0,1).rvs() # 由y|x的条件分布的期望值初始化x[0,1] x[0,1]=(x[0,0]+a)/(n+a+b) for i in range(1,m): x[i,]=x[i-1,] # print(x[i,] is x[i-1,]) # 计算新的x x[i,0]=binom(n,x[i,1]).rvs() # 计算新的y x[i,1]=beta(x[i,0]+a,n-x[i,0]+b).rvs() x=x[burn:,:]
References
- https://www.cnblogs.com/pinard/p/6638955.html
- https://zhuanlan.zhihu.com/p/37121528