一、接前一天
前天学习了,数据流图,今天尝试在不同设备上(cpu或者gpu)来执行计算图。
本次使用cpu来执行,但是不涉及gpu。gpu放在后面学习,这里比较重要。
二、示例
1. 先看看自己的设备
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
可以通过上面代码实现。

这个代码执行后,只会显示一个cpu,TensorFlow会隐式的将代码分配到各个CPU上,因此默认情况下 CPU:0表示所有CPU都对TensorFlow有效。
2. 内部逻辑
TensorFlow使用多设备执行代码的原理是通过图分割和设备放置实现的。
-
首先,通过图分割将计算图中的操作划分为
不同的子图,每个子图表示为一个单独的计算设备。然后,通过设备放置将每个子图映射到对应的物理设备上进行计算。这可以通过手动指定设备放置来完成,也可以使用 TensorFlow 的默认设备放置策略(例如,在具有多个 GPU 的系统中将操作分配到可用的 GPU 上)。 -
在执行期间,TensorFlow会自动在各个设备之间
传输必要的数据,以便完成整个计算过程。这通常包括从CPU到GPU的输入数据传输、在更快的设备上执行操作并将结果传回到 CPU 等操作。 -
使用多设备执行可以加速模型训练和推断,特别是在大规模深度学习任务中。
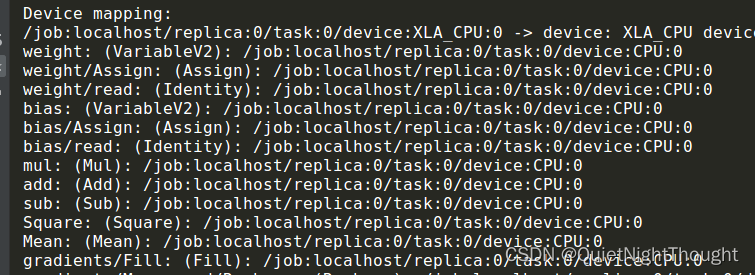
3. 通过tf.decice()将计算图放在特定的计算设备上
import tensorflow as tf
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
tf.reset_default_graph()
'''
代码是用于重置 TensorFlow 计算图中所有变量和状态的函数。它通
常在重新运行模型之前调用,以确保您使用的是新的、干净的计算
图。这可以帮助避免在多次运行模型时出现命名冲突或其他不必要的
错误。
cpu:个数 一般从 0,1,2,3.。。。代表不同设备
'''
with tf.device("/device:cpu:0"):
# create w and b init 0.0
w = tf.Variable(0.0, name='weight')
b = tf.Variable(0.0, name='bias')
# create input and out
x = tf.placeholder(dtype=tf.float32, shape=[None])
out = tf.placeholder(dtype=tf.float32, shape=[None])
# create loss and opt
y = w * x + b
loss = tf.reduce_mean(tf.square(y - out))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(loss)
config = tf.ConfigProto()
config.log_device_placement=True
# train model
with tf.Session(config=config) as sess:
tf.global_variables_initializer().run(session=sess)
for i in range(100000):
_, loss_val, w_val, b_val = sess.run(
[train_op, loss, w, b],
feed_dict={x: [1, 23, 4, 5, 7, 5, 7], out: [3, 5, 7, 9, 11, 13, 15]}
) #注意 输入的数据 形状要一致,避免输出与预测值得形状不一致问题
if i % 100 == 0:
print('Step {}: loss = {}, w = {}, b = {}'.format(i, loss_val, w_val, b_val))