目录
01背包:
完全背包:
多重背包:
分组背包:
01背包:
[NOIP2005 普及组] 采药 - 洛谷https://www.luogu.com.cn/problem/P1048
01背包背景
在一个小山上,有个n个黄金和一个容量为w的背包,每块黄金有体积和价值两种属性,我们想要选若干黄金装入背包,使背包中黄金的总价值最大且不超过背包容量。
闫式DP分析法: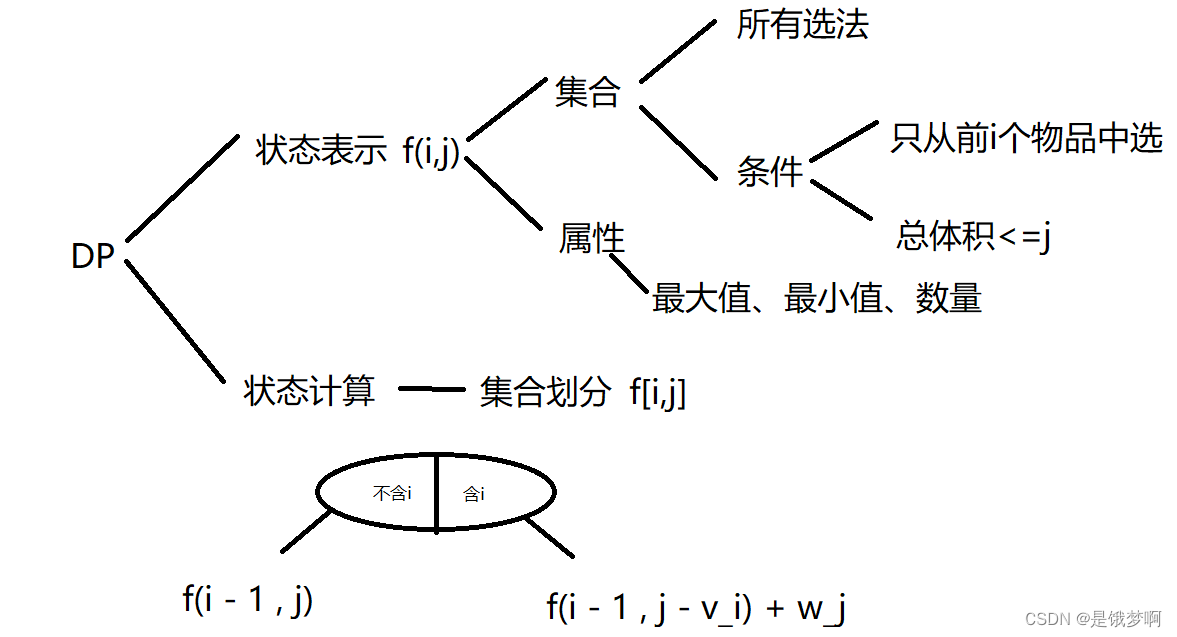
对于每个块黄金,我们都有两种选择,选或者不选。
在所有的选法中,对于第 i 块黄金,当我们不选择它时,
当我们选择它时,我们需要换一个思路考虑,在所有的选法中,我们都选择了这块黄金,我们在所有的选法中,都减去这个黄金的,也就是从前 块黄金中选,总体积不超过
,即
;最后在加上第i块黄金的价值。
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 1010;
int n,m;
int f[N][N];
int t[N],w[N];
int main()
{
scanf("%d%d",&m,&n);
for(int i =1 ; i <=n ;i ++) scanf("%d%d",&t[i],&w[i]);
for(int i = 1; i <= n ;i ++)
{
for(int j = 0 ; j<= m; j ++)
{
f[i][j] = f[i-1][j];
if(j>=t[i]) f[i][j] = max(f[i][j],f[i-1][j-t[i]] + w[i]);
}
}
printf("%d",f[n][m]);
return 0;
}
现在我们来思考一下优化:
中对于第
层的更新,我们只用到了第
层,没有用到
及之前的数据。于是我们可以使用一维来存储,更新的时候直接更新掉就行,反正以后也用不到了。我们直接删掉第一维,考虑是否正确。
for(int i = 1; i <= n ;i ++)
{
for(int j = t[i] ; j<= m; j ++)
{
f[j] = max(f[j],f[j-t[i]] + w[i]);
}
}
我们删掉第一维后,核心代码变成了这个样子,我们思考
是否等价于
答案是否定的,其应该等价于 ,当我们直接去掉第一维后,相当于所有的第一维都变成相同的了,但其实并不相同。
我们知道 ,我们更新
时其实用到的也只有
时的
。我们只要倒着遍历,这样,访问
时,其值还没有被更新也就还是第
层的数据。
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 1010;
int n,m;
int f[N];
int t[N],w[N];
int main()
{
scanf("%d%d",&m,&n);
for(int i =1 ; i <=n ;i ++) scanf("%d%d",&t[i],&w[i]);
for(int i = 1; i <= n ;i ++)
{
for(int j = m ; j>=t[i]; j --)
{
f[j] = max(f[j],f[j-t[i]] + w[i]);
}
}
printf("%d",f[m]);
return 0;
}
完全背包:
疯狂的采药 - 洛谷https://www.luogu.com.cn/problem/P1616
完全背包的背景:
完全背包和01背包的区别就在于,完全背包中,每个物品的数量都是无限的,可以取无限个,只要不超过背包容量。
闫式DP分析法:
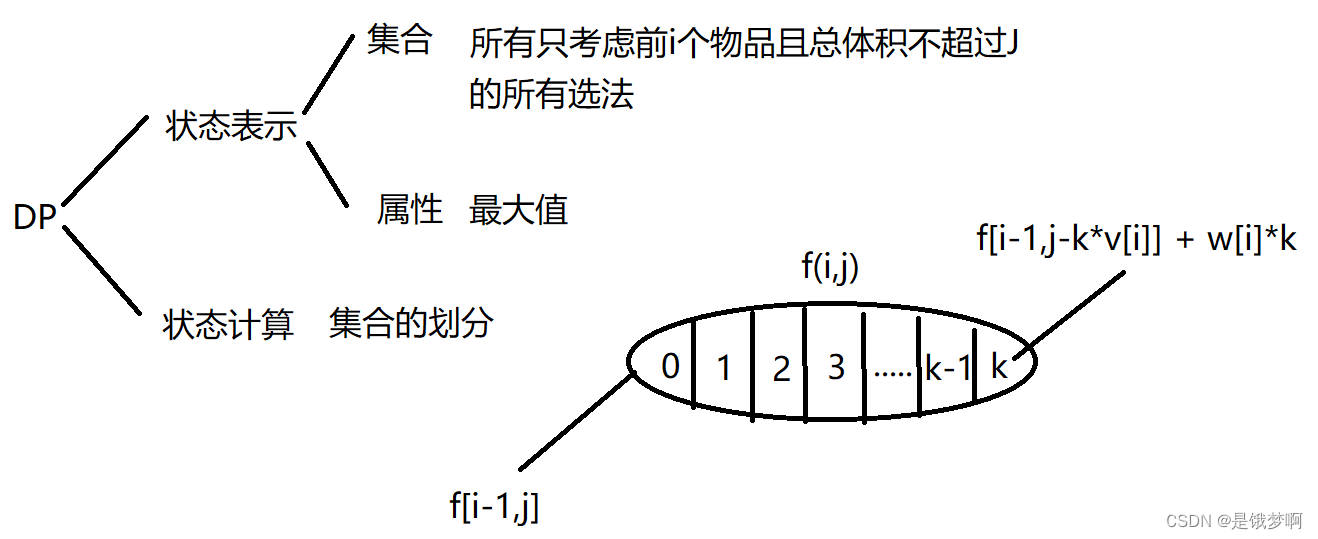
此次集合划分中,我们根据每个物品选取的数量进行划分;
当我们选取0个物品时,也就是第i个物品一个也不选,即:
当我们选取K个物品时,我们采取和之前01背包一样的解决策略,每个方案都选取了k个第i个物品,我们将所有方案都减去第i个物品,最后在加上第i个物品的价值,即:
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long LL;
typedef pair<int,int> PII;
const int N = 1010;
int n,m;
int f[N][N];
int t[N],w[N];
int main()
{
cin >> m >> n;
for(int i =1 ;i <= n ;i ++) cin >> t[i] >> w[i];
for(int i = 1 ;i <= n ;i ++)
{
for(int j =0 ;j <= m ;j ++)
{
for(int k = 0 ;k *t[i] <= j ; k ++)
f[i][j] = max(f[i][j],f[i-1][j-k*t[i]]+w[i]*k);
}
}
cout<<f[n][m];
return 0;
}
我们发现这个写法时间复杂度太高了,看看有没有优化的方法。
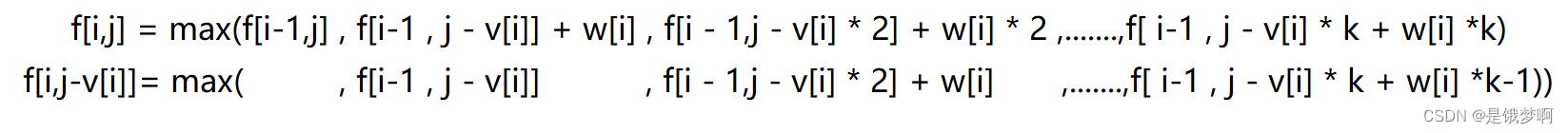
我们观察上式发现,和
的状态很像;
于是乎,我们的就可以利用
的状态进行优化,即
;
for(int i = 1 ;i <= n ;i ++)
{
for(int j =0 ;j <= m ;j ++)
{
f[i][j] = f[i-1][j];
if(j>=t[i]) f[i][j] = max(f[i][j],f[i][j-t[i]]+w[i]);
}
}接下来我们对比完全背包和01背包的状态转移方程:
01背包:
完全背包:
我们考虑将完全背包优化到一维(将第一维直接删掉):
for(int i = 1 ;i <= n ;i ++)
{
for(int j =t[i] ;j <= m ;j ++)
{
f[j] = max(f[j],f[j-t[i]]+w[i]);
}
}完全背包中,因为是第
层,所以没有01背包那个问题,可以直接删掉第一维。
//AC代码
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long LL;
typedef pair<int,int> PII;
const int N = 1e7+10;
int n,m;
LL f[N];
int t[N],w[N];
int main()
{
scanf("%d%d",&m,&n);
for(int i =1 ;i <= n ;i ++) scanf("%d%d",&t[i],&w[i]);
for(int i = 1 ;i <= n ;i ++)
{
for(int j =t[i] ;j <= m ;j ++)
{
f[j] = max(f[j],f[j-t[i]]+w[i]);
}
}
printf("%lld",f[m]);
return 0;
}
多重背包:
宝物筛选 - 洛谷https://www.luogu.com.cn/problem/P1776多重背包和完全背包的一个区别的,物品的数量不在是有无限个,而是有固定是
个;
那我们完全背包的朴素版本和完全背包就很类似了;
for(int i = 1 ;i <=n ;i ++)
{
for(int j = 0; j<= m ;j ++)
{
for(int k =0 ;k <= s[i] && k*v[i] <= j ; k ++)
{
f[i][j] = max(f[i][j],f[i-1][j-k*v[i]]+w[i]*k);
}
}
}这里我们只需要控制一下,每个物品可以选取的最大数量以及不要超过容量的上限即可。
但是这样的方法时间复杂度太高了,这是我们接受不了的。我们考虑有没有优化方式。
对于每个物品,我们考虑了选取1个、2个、..........等等。我们每次选取都做了很多重复性工作,我们考虑能不能将进行打包,以减少枚举次数。
这就是二进制分组优化方案:
举个例子:
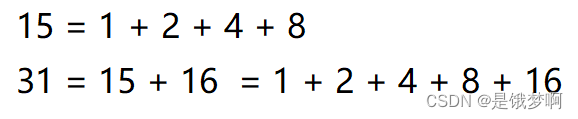
也就是说任何一个+1后是2的整数次幂的数都可以通过二进制进行拆分。
那如果是一个随便的数是否也可以凑呢
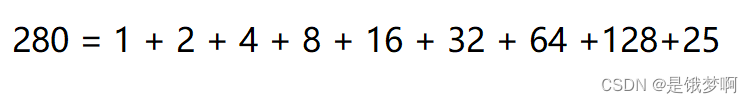
从1~128中,我们可以凑出1~255中的任何一个数,但是不够280;要是加上256就超出了280的范围。
我们最后加上280 - 255 = 25 的话,1~128可以凑出1~255中的任何一个数加上25,就可以凑出1~280中的任何一个数不重不漏。
时间复杂度就可以从优化到
;
//AC代码
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long LL;
typedef pair<int,int> PII;
const int N = 1000010;
int n,m;
int v[N],w[N];
int f[N];
int main()
{
cin >> n >> m;
int cnt = 0;
for(int i = 1; i<= n; i++)
{
int a,b,c;
cin >> a >> b >> c;
int k = 1;
while(k<= c)
{
cnt ++;
v[cnt] = a * k;
w[cnt] = b * k;
c -= k;
k *= 2;
}
if(c > 0)
{
cnt ++;
v[cnt] = a * c;
w[cnt] = b * c;
}
}
n = cnt;
for(int i =1 ;i <= n ;i ++)
{
for(int j = m ;j >= w[i] ;j --)
{
f[j] = max(f[j],f[j-w[i]]+v[i]);
}
}
cout<<f[m]<<endl;
return 0;
} 分组背包:
通天之分组背包 - 洛谷https://www.luogu.com.cn/problem/P1757
分组背包背景:
有 N 组物品和一个容量是 V 的背包。
每组物品有若干个,同一组内的物品最多只能选一个。
每件物品的体积是,价值是
,其中 i 是组号,j 是组内编号。
求解将哪些物品装入背包,可使物品总体积不超过背包容量,且总价值最大。
闫式DP分析法:
 我们这次是遍历第 i 组中第 k 个物品选或不选,最后也就转化为了01背包问题;
我们这次是遍历第 i 组中第 k 个物品选或不选,最后也就转化为了01背包问题;
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<vector>
using namespace std;
const int N = 10010,M = 110;
typedef long long LL;
typedef pair<int,int> PII;
int n,m;
vector<vector<int>> val,wei;
int cnt;
int st[N],f[N];
int main()
{
cin >> m >> n;
val.resize(M);
wei.resize(M);
for(int i =1;i <=n ;i ++)
{
int a,b,c;
cin >> a >> b >> c;
if(!st[c]) cnt++,st[c] = 1;
wei[c].push_back(a);
val[c].push_back(b);
}
for(int i = 1;i <= cnt ; i ++)
{
for(int j = m ;j >=0; j--)
{
for(int k = 0;k < wei[i].size() ;k ++ )
if(wei[i][k]<=j) f[j] = max(f[j],f[j-wei[i][k]]+val[i][k]);
}
}
cout<<f[m]<<endl;
return 0;
}