两篇改进Transformer结构的论文:MAN(arXiv2022),ScalableViT(ECCV2022).
Multi-Scale Attention Network for Single Image Super-Resolution, arXiv2022
解读:【ARIXV2209】Multi-Scale Attention Network for Single Image Super-Resolution - 高峰OUC - 博客园 (cnblogs.com)
论文:https://arxiv.org/abs/2209.14145
代码:https://github.com/icandle/MAN
利用多尺度机制与大核注意机制结合,用于图像超分辨率。
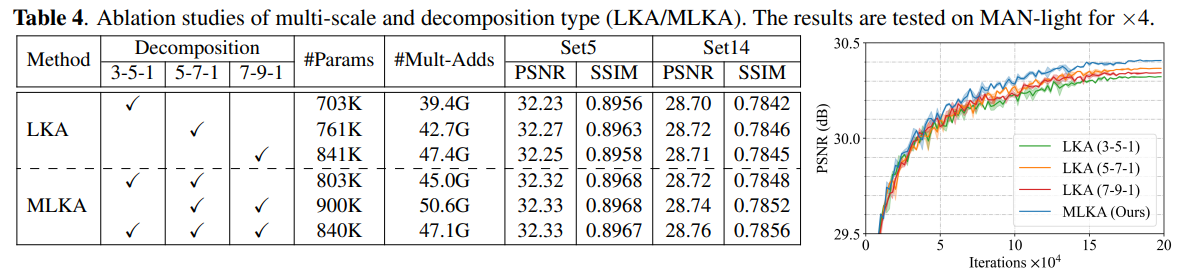
本文提出了一种基于CNN的多尺度注意力网络(MAN),该网络由多尺度大核注意力单元(MLKA)和门控空间注意力单元(GSAU)组成,以提高卷积SR网络的性能。
MLKA用多尺度和门方案校正LKA,以获得不同粒度级别的丰富注意力图,从而联合聚合全局和局部信息,避免潜在的阻塞伪影。GSAU将门机制和空间注意力相结合,以去除不必要的线性层并聚合信息空间上下文。
Visual Attention Network (VAN)提出将大核卷积划为:depth-wise conv,dilated conv,和 point-wise conv 的组合。VAN作者指出,图像超分任务中使用VAN,发现了一个很重要的问题:含膨胀的深度卷积会为超分任务带来“块状伪影(blocking artifacts),损害恢复性能”

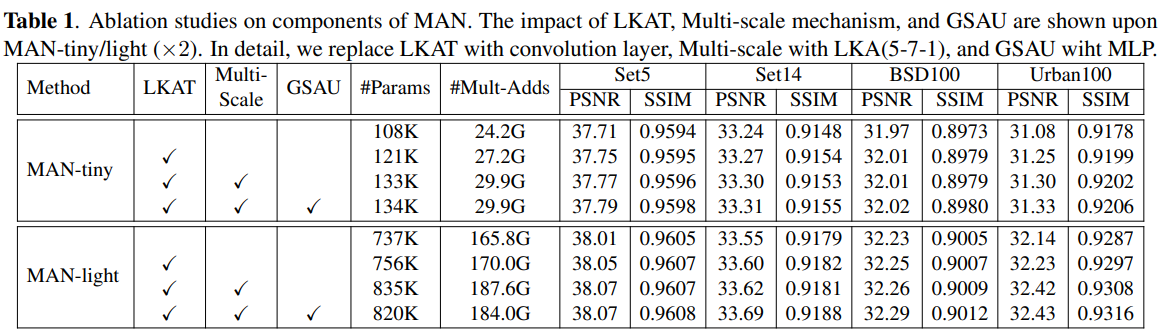
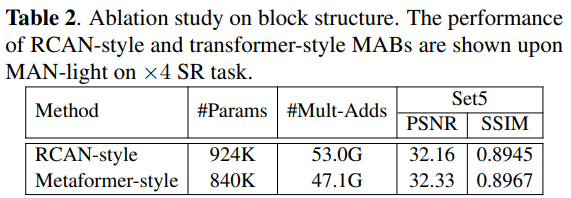
论文提出多尺度大核注意力(MLKA),它将多尺度机制和LKA相结合,以相对较少的计算构建各种范围相关性。为避免膨胀引起的潜在块伪影,采用门机制来自适应地重新校准生成的注意力图。并将其置于MetaFormer风格的结构上,以构建多注意力块(MAB)。构建一种简化的门控空间注意力单元(GSAU),通过应用空间注意力和门机制来减少计算并包括空间信息。在MLKA和GSAU的武装下,MAB被堆叠以构建用于SR任务的多尺度注意力网络(MAN)。
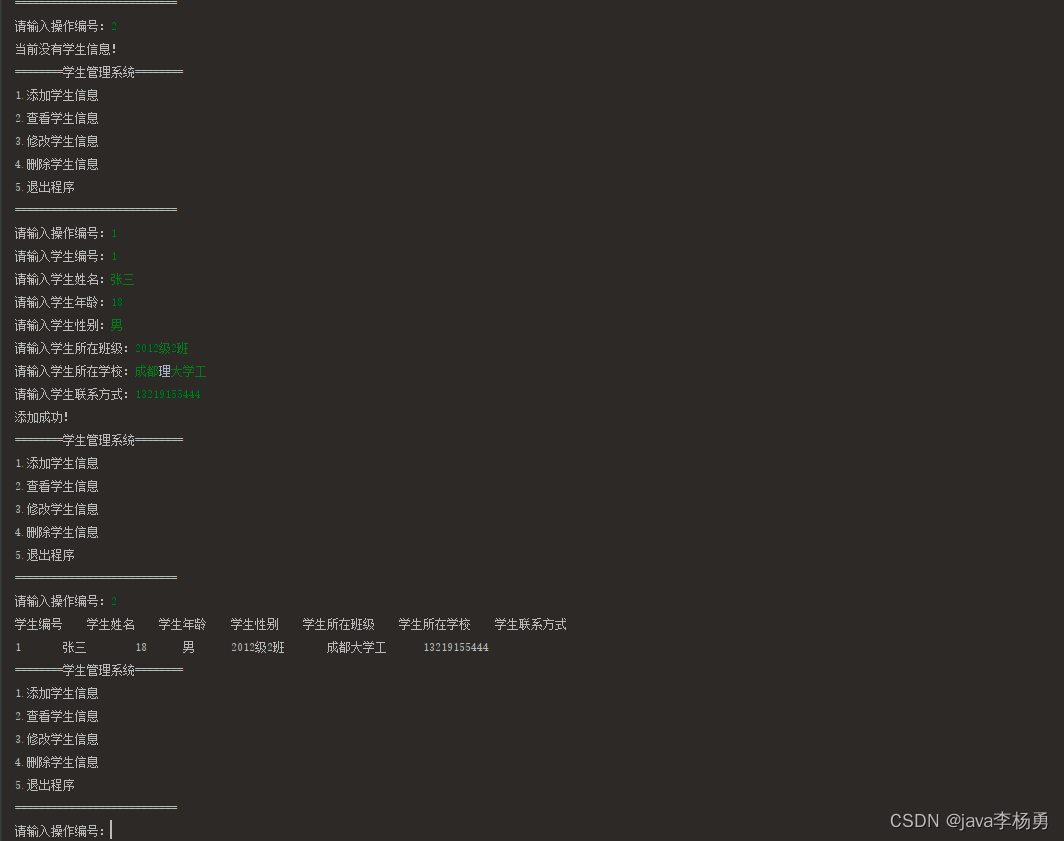
MAN网络(Multi-scale Attention Network)

MAN由三个部分组成:浅层特征提取模块(SF)、基于多尺度注意力块的深层特征提取模块 和高质量图像重建模块。
Multi-scale Attention Block (MAB)
MAB由两个组件组成:多尺度大核注意力(MLKA)模块和门空间注意力单元(GSAU)。
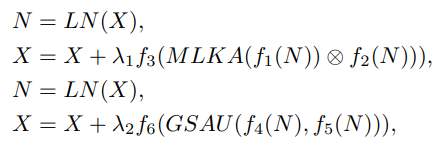
Multi-scale Large Kernel Attention (MLKA)
MLKA,结合大核分解和多尺度学习。它有三个主要部件,用于建立相互依赖性的大内核attens(LKA)、用于获得异构尺度相关性的多尺度机制以及用于动态重新校准的门控聚合。
MLKA首先使用 Point-wise conv 改变通道数,然后将特征 split 成三组,每个组都使用 VAN 里提出的大核卷积来处理(即depth-wise conv,dilated conv,和 point-wise conv 的组合)。三组分别使用不同尺寸的大核卷积(7×7、21×21、35×35),膨胀率分别设置为(2,3,4)。

使用深度膨胀卷积会带来“块状伪影”问题。因此在分组后,作者引入门控聚合来动态调整LKA的输出。即上图中最上面的DWConv。在对应组中,与下方深度卷积使用的核尺寸一致,并将该卷积的输出与对应组中LKA的输出做逐元素乘法。
Gated Spatial Attention Unit (GSAU)
在Transformer块中,前馈网络(FFN)是增强特征表示的重要组成部分。然而,具有宽中间通道的MLP对于SR来说太重了,尤其是对于大的图像输入。论文将简单空间注意力(SSA)和门控线性单元(GLU)集成到所提出的GSAU中,以实现自适应门控机制,并减少参数和计算。为了更有效地捕捉空间信息,采用单层深度卷积来对特征图进行加权。
普通的FFN是两个 point-wise conv 。为了进一步增强特征表示,作者引入了 spatial self-attention 和 gated linear unit (GLU) 的思路,具体如下图所示,上面分支加入了一个 dwconv 对结果加权,两个分支的特征进一步加强了特征表示。
Large Kernel Attention Tail (LKAT)
作者采用了以前超分方法的范式,将一个LKA用在网络尾部,以进一步从特征中总结出可用的信息,提升图像修复性能。
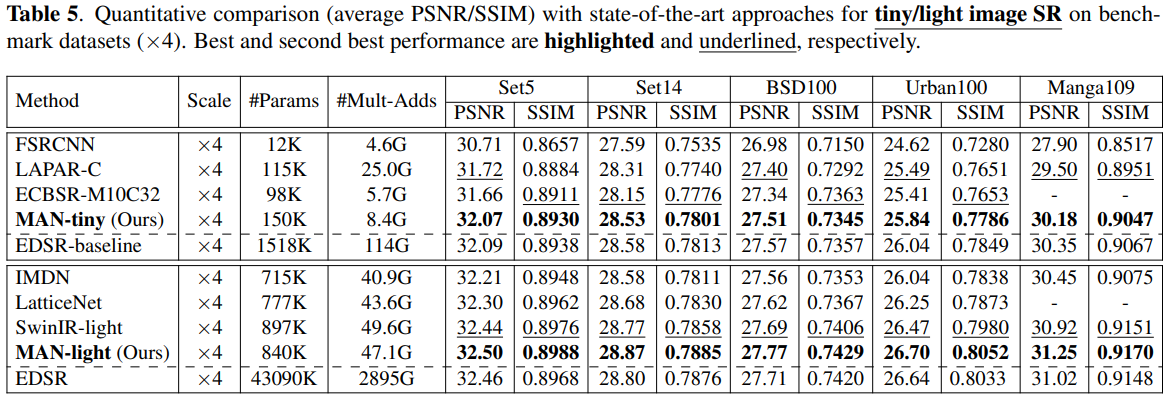
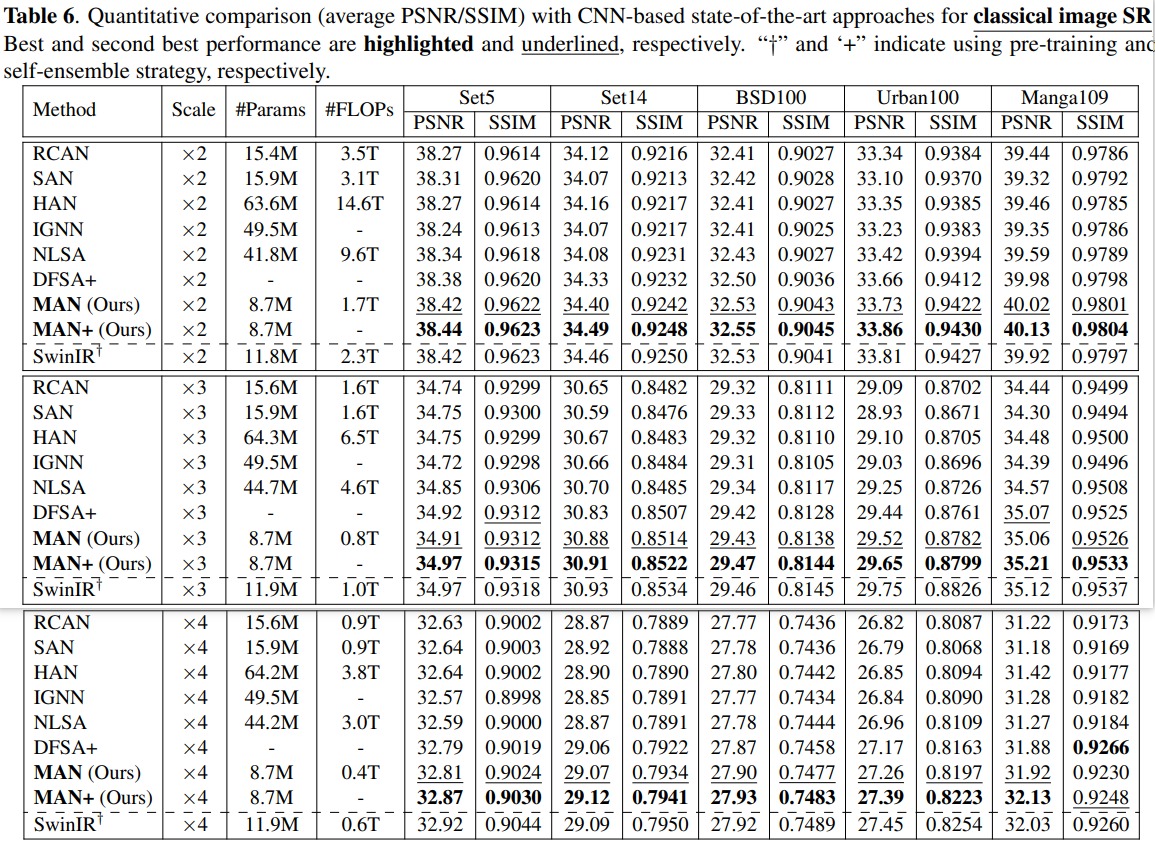
实验




ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer, ECCV2022
解读:【论文笔记】ScalableViT:可伸缩Transformer - 知乎 (zhihu.com)
ECCV 2022 | ScalableViT:重新思考视觉Transformer面向上下文的泛化 - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2203.10790
代码:https://github.com/yangr116/scalablevit
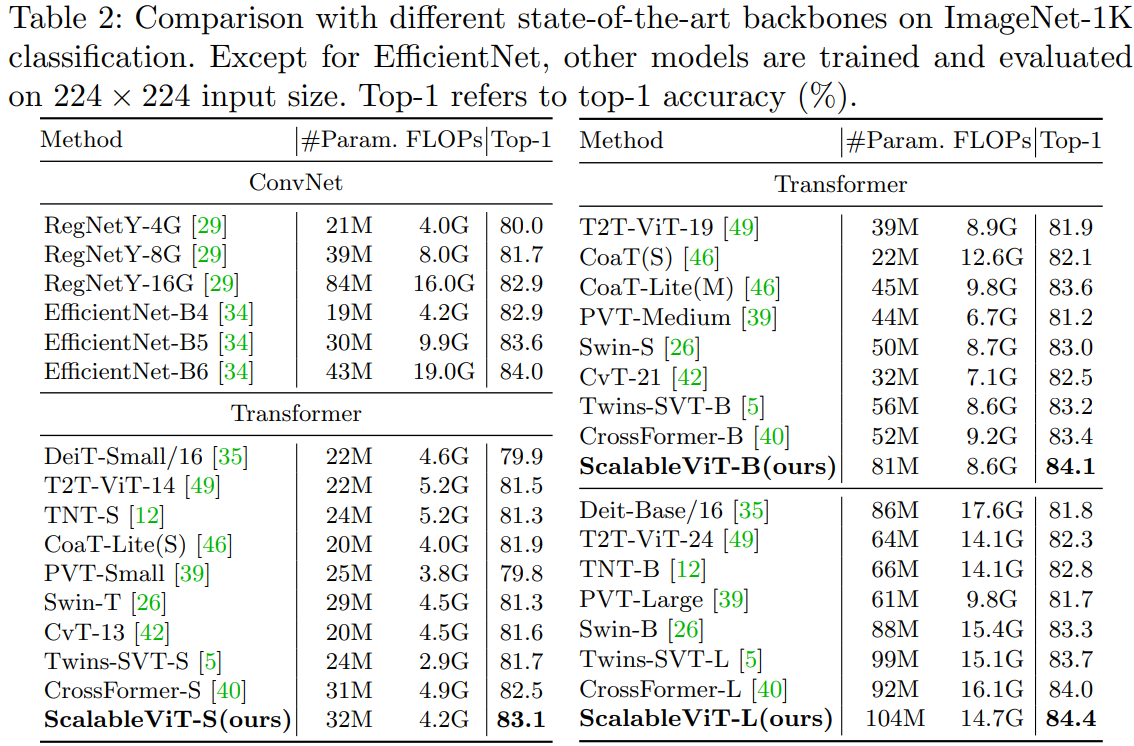
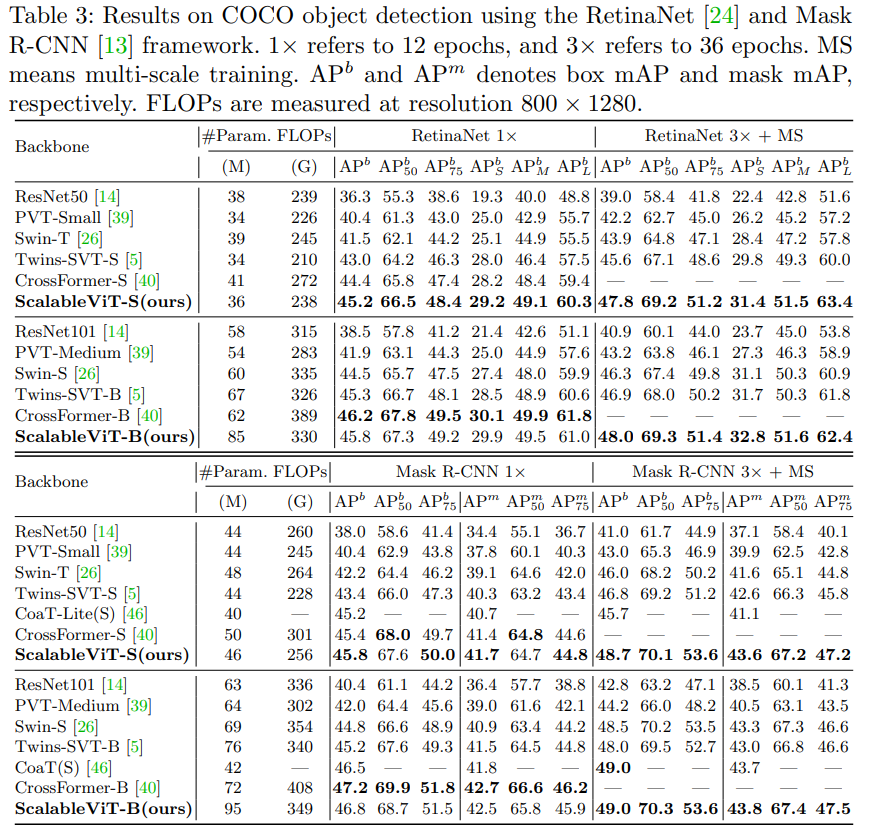
本文提出一种新的transformer模型ScalableViT。它提出一种可伸缩的自注意力机制SSA来解除QKV与输入维度的绑定,和一种基于交互窗口的自注意力IWSA来实现非重叠窗口的交互,取得SOTA性能。
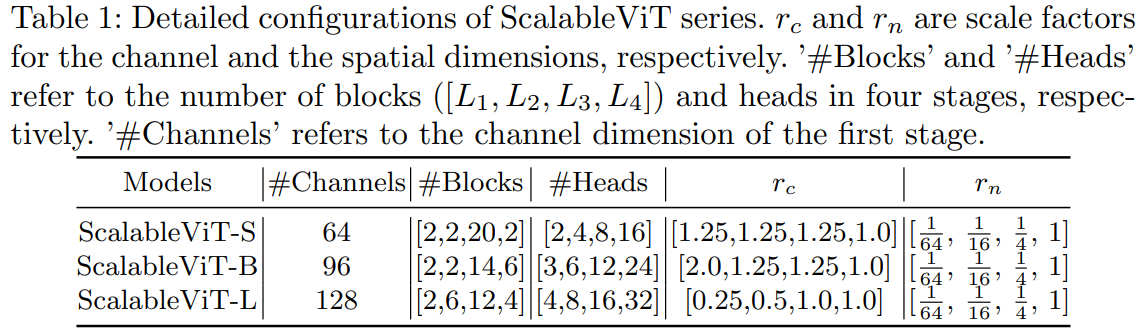
基础的自注意力本质上依赖于在预定义的固定维度上运算 ,这限制了它获得有上下文线索和全局表征的泛化能力。ScalableViT则提出可缩放自注意力SSA,通过两个在维度上的缩放系数来释放query,key,value矩阵维度与输入的绑定,来缓解这个问题。这种缩放能力获取到上下文泛化能力,增强了目标敏锐度,同时也让整个模型位于准确率和代价之间更经济的权衡状态。提出一种基于窗口的自注意力IWSA,通过重新合并独立的value块、聚合相邻窗口的空间信息来建立不重叠区域的交互。SSA和IWSA交替堆叠就得到ScalableViT。

WSA更倾向于部分而非整个对象,可能归咎于固定的维度限制了学习能力。SSA在通道和空间维度引入缩放系数,维度更加灵活,输入不再绑定;空间缩放能力也聚合了带有相似语义信息的冗余块更为紧凑;扩展通道维度以学习更多的图像表征。
ScalableViT架构
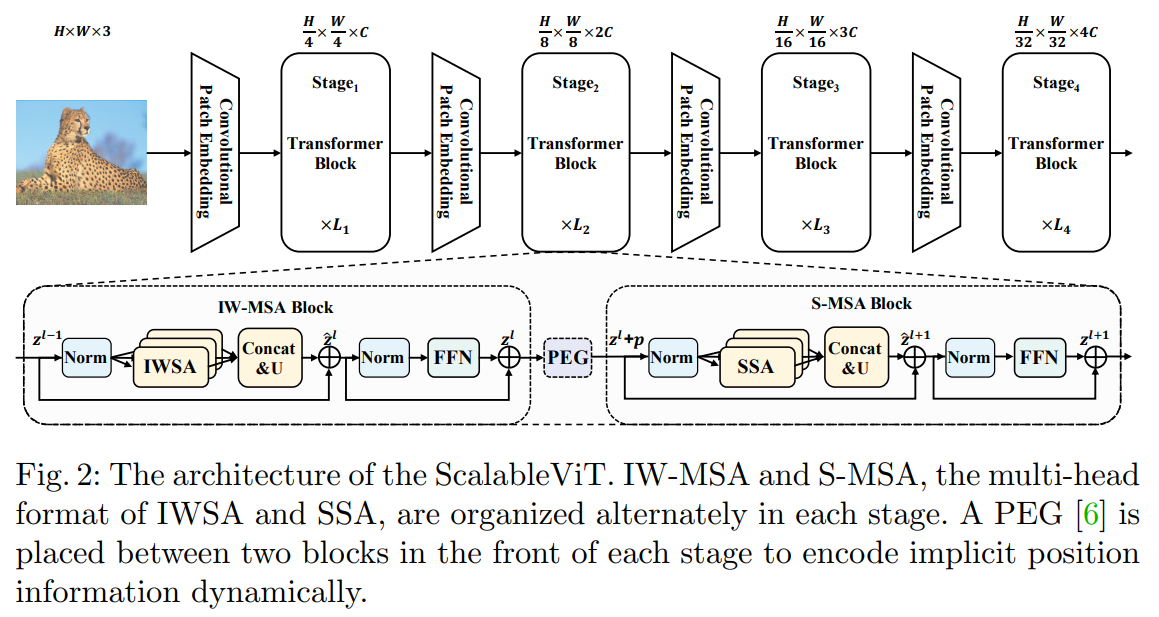
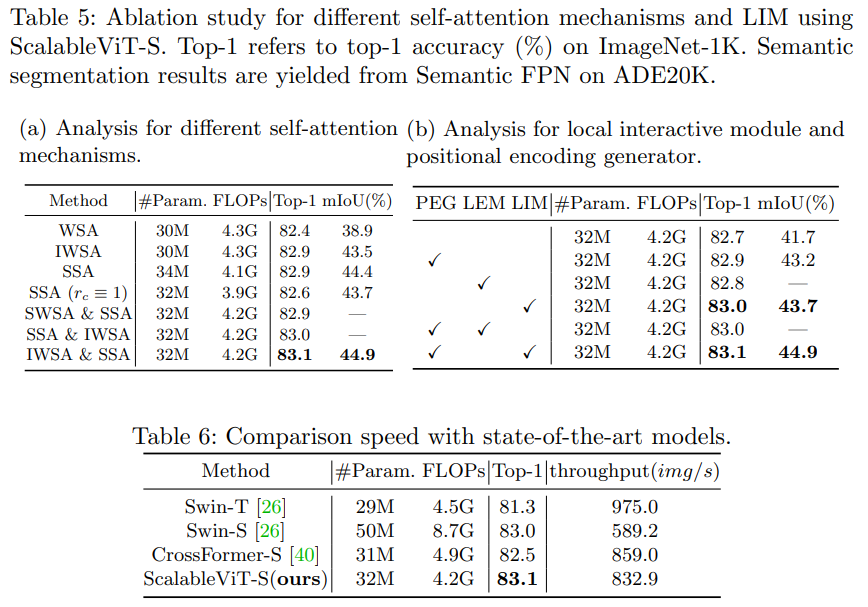
在每个阶段,设计了一种交替排列的IW-MSA和S-MSA块来组织拓扑结构。在每个阶段的前端,在两个Transformer块之间插入一个位置编码生成器(PEG),动态生成位置嵌入。
SSA同时在空间和通道维度中引入不同的尺度因子,以保持面向上下文的泛化,同时减少计算开销。IWSA通过聚集来自一组离散值标记的信息来增强局部自我注意的感受域。两者都具有线性计算复杂性,并且可以在单层中学习长程依赖关系。
Scalable Self-Attention

可伸缩的自我注意(SSA),其中两个缩放因子(rn和rc)分别引入到空间和通道维度,产生了比普通的一个更有效的中间计算。中间维度更有弹性,不再与输入x深度绑定。模型可以获得面向上下文的泛化,同时显著减少计算开销。
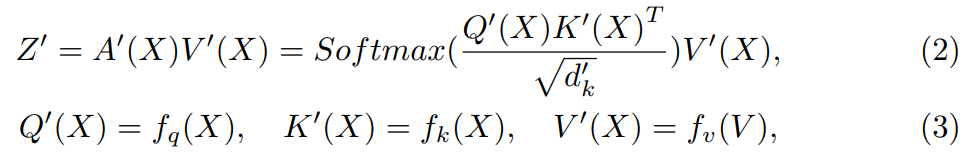
Interactive Window-based Self-Attention
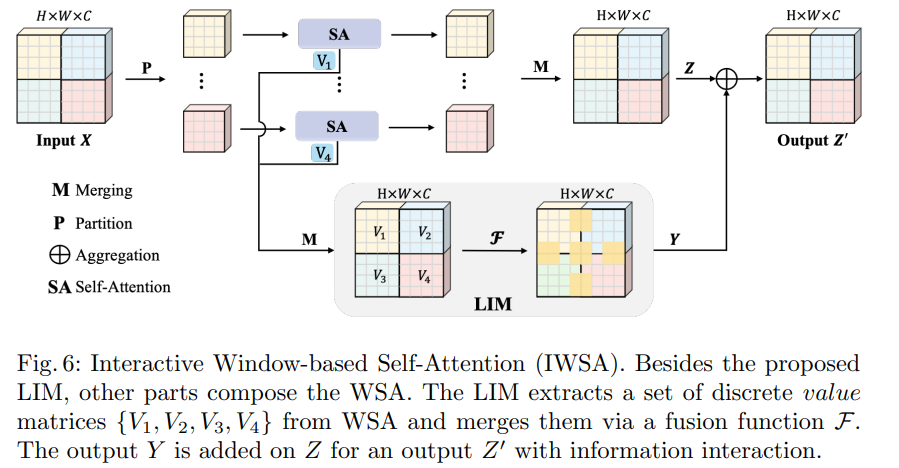
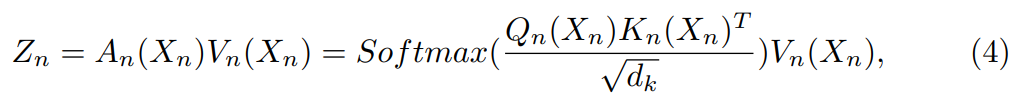
WSA的线性复杂度,它可以适用于各种需要高分辨率输入的视觉任务,但这种计算效率高的WSA产生了一个具有完整形状但孤立激活的特征图,这归因于在单一层中错过了全局感受野。于是,本文提出了基于交互式windows的自我注意(IWSA),该IWSA将一个本地交互模块(LIM)整合到WSA中。
输出的Y = F(V)是一个包含全局信息的综合特征图,这个特征图被添加到Z上作为最终输出Z '。在不丧失一般性的前提下,IWSA的计算公式为:
![]()
位置编码
除了LIM引入的位置信息外,作者还利用由固定权值的卷积层组成的位置编码生成器(PEG)来获取隐式的位置信息。如图2所示,它被插在两个连续的Transformer块之间,每个级的前面只有一个。在PEG之后,输入的tokens被发送到随后的块,位置偏差可以使Transformer实现输入排列。
实验