1、总体介绍
大型语言模型的训练分为两个阶段:(1)从原始文本中进行无监督的预训练,以学习通用的表征;(2)大规模的指令学习和强化学习,以更好地适应最终任务和用户的偏好。
作者通过训练LIMA来衡量这两个阶段的相对重要性,LIMA是一个65B参数的LLaMa语言模型,仅在1000个精心策划的提示和回应上用标准的监督损失进行微调,没有任何强化学习或人类偏好建模。
LIMA表现出了非常强大的性能,从训练数据中仅有的几个例子中学习到了具体的反应格式,包括从规划旅行路线到猜测另一个历史的复杂查询。
此外,该模型倾向于对训练数据中没有出现过的任务进行良好的泛化。
在一项受控的人类研究中,来自LIMA的反应在43%的情况下与GPT-4相比更好;与Bard相比,这一统计数字高达58%,与DaVinci003相比,这一统计数字为65%,后者是用人类反馈进行训练的。
这些结果显著表明,大型语言模型中的几乎所有知识都是在预训练中学习的,只需要有限的指令学习数据就可以教会模型产生高质量的输出。
2. 关键方法
论文提出「表面对齐假设Superficial Alignment Hypothesis」:假设大模型的知识和能力主要是在预训练阶段学习到的,对齐只是教会模型在与用户交互时应该使用哪种格式的子分布。如果该假设正确,那么对齐在很大程度上是关于学习风格的,人们可以用一组相当小的样本便可充分调动激活预训练语言模型的能力。
MetaAI认为,前面说的两阶段的第二个阶段需要大量的人类标注的交互结果,非常的耗费时间和成本。但是,如果我们已经有了一个强大的预训练模型,那么应该可以有更简单的方法让模型拥有这样的能力。为此,MetaAI提出了LIMA,仅仅用1000个精心挑选的训练数据即可让模型激发强大的能力。
从社区论坛StackExchange和wikiHow筛选750例热门问题答案,样例筛选要保证质量和多样性。在质量和多样性方面,作者针对不同的论文数据做了大量筛选工作,包括不同主题、最佳回答、长度控制等,具体见文章章节Aligment Data。论文作者手动撰写了250个prompts和对应答案,同时保证了样例多样性和回答风格的一致性。
下图是LIMA使用的训练数据总结:
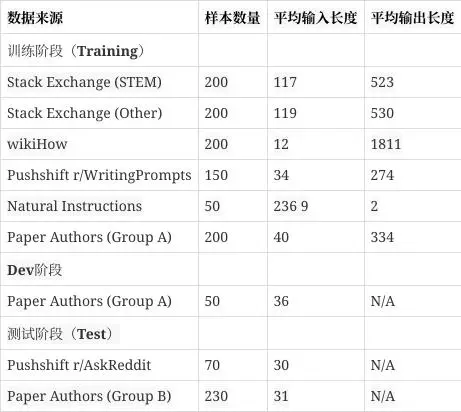
LIMA背后的核心思想是,对齐可以是一个简单的过程,可以是模型从与用户互动中学习相应的风格或格式,以展示在预训练期间已经获得的知识和能力。这种方法使LIMA能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。此外,该模型往往能很好地推广到未出现在训练数据中的未见任务。
3、结果分析
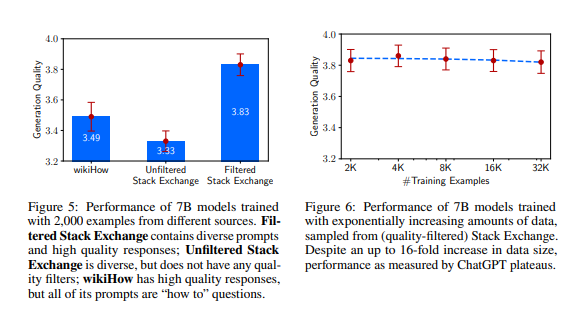
作者通过消融实验研究了微调训练数据的多样性、质量和数量对生成结果的影响。结论是微调样本的多样性和质量对结果具有可衡量的积极影响,而仅扩大微调样本数量可能并不会产生良性影响。
对未经筛选和经过筛选的Stack Exchange 2000样本数据,微调训练模型结果对比,在生成结果质量评估上二者相差0.5分。设置指数增长的训练集,当训练样本数量倍增时生成结果的质量并没有提升,这一结果表明对齐的比例定律(scaling laws)不仅取决于数量,而在于保证质量的同时提高prompt的多样性。
4、思考
大模型预训练阶段获得的能力决定了模型能力的上限,通常来说,在同级别海量语料和相同网络架构下,模型参数越多模型能力越强。在微调训练阶段,只是在进一步激活模型的潜在性能,通过本论文可以看到,微调样本量对生成结果质量并不是关键因素,在微调阶段,更应该关注于微调样本的多样性和数据质量。
基于GPT的生成式大语言模型,在预训练阶段通过对海量数据的无监督学习,得到语言生成能力和对世界知识的存储能力,这一步相当于是在「练内功」,预训练之后的微调和对齐训练是对语言模型能力的挖掘和激活,引入各种任务数据进行微调训练,相当于是「练招式」,只有内功强大,才能更好凸现武术招式的厉害。反过来,如果没有强大的内功再精彩的招式也是花拳绣腿,缺乏实战和落地能力。
chatGPT大模型的一些关键要点:
- 语言生成能力、基础世界知识、上下文学习能力来自于预训练语言模型(GPT3+)
- 存储大量知识的能力来自于千亿级的参数量
- 执行复杂推理的能力很可能来自于代码的训练
- 指令微调不会为模型注入新的能力
- 指令微调通过牺牲性能换取与人类的对齐(alignment tax)
- 生成中立、客观的能力,安全和翔实的答案来自与人类的对齐(RLHF)