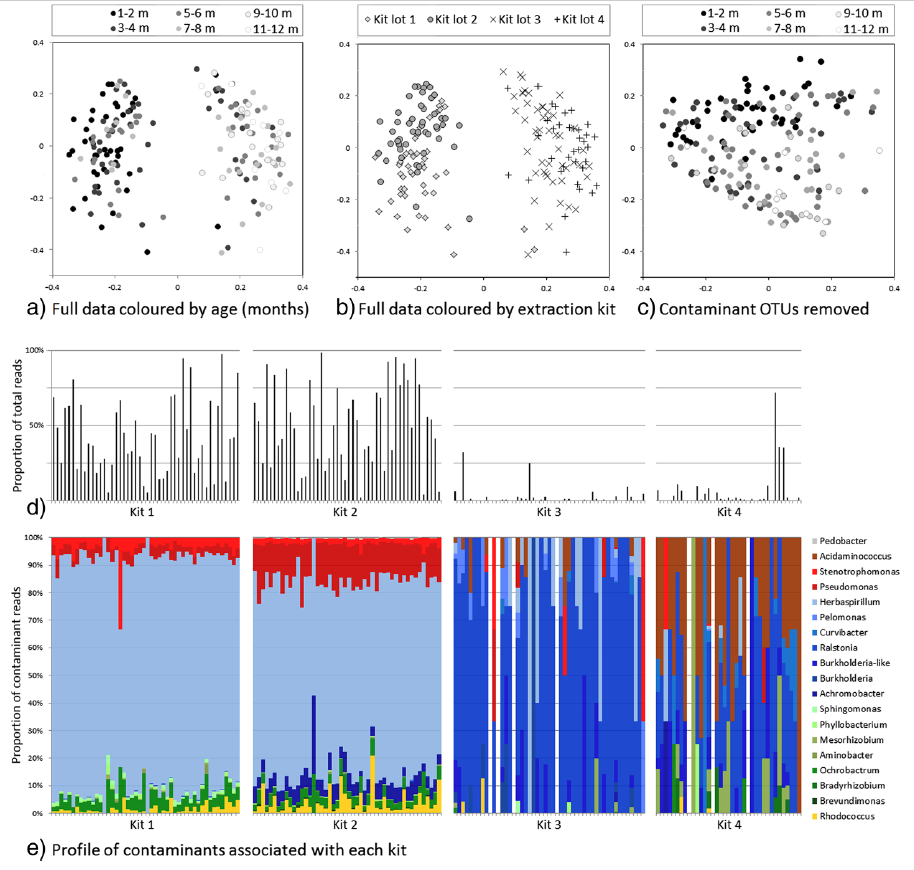
创建一个得分表 score
install.packages("dplyr")
library(dplyr)
install.packages("tibble")
library(tibble)
install.packages("stringr")
library(stringr)
score = tibble(ID=c("1222-1","2001-0","3321-1","4898-0","2782-0","1002-8","4211-0","1023-1","3325-1"),
gender=c("female","male","male","male","female","female","male","female","male") ,
chinese_mid_score=round(runif(9,80,90),digits = 0),
chinese_final_score=round(runif(9,80,90),digits = 0),
english_score=c(round(runif(8,80,90),digits = 0),NA),
match_score=round(runif(9,80,90),digits = 0),
musci_score=round(runif(9,80,90),digits = 0)
)
view(score)
其中
round(runif(9,80,90),digits = 0)
这段代码是在 R 语言中生成一个长度为 9 的随机数向量,向量中的每个元素都是在 80 到 90 之间的均匀分布的随机数,并使用 round 函数将这些随机数四舍五入为整数。其中,runif 函数用于生成均匀分布的随机数,digits 参数指定保留的小数位数,而 round 函数用于将随机数四舍五入为整数。因此,这段代码生成的向量中的每个元素都是 80 到 90 之间的整数。
c(round(runif(8,80,90),digits = 0),NA)
设置最后一个数据为缺失值,用 NA 表示
对 列 进行处理
contains
···当列数很多时,select 逐个输入想要的列太浪费时间,用contains筛选包含某关键词的列
score_column1 = score |>
select(contains("chinese")|contains("english"))
names(score_column1)

除了contains,还可以用 matches
matches
score_column4 = score |>
select(matches("mid|final"))
names(score_column4)
starts_with , ends_with
筛选以某字符串 开头starts_with 或 结尾ends_with 的列
score_column2 = score |>
select(starts_with("chinese"))
names(score_column2)
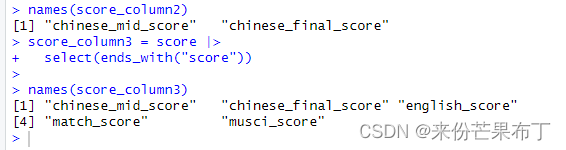
score_column3 = score |>
select(ends_with("score"))
names(score_column3)
对 行 进行处理
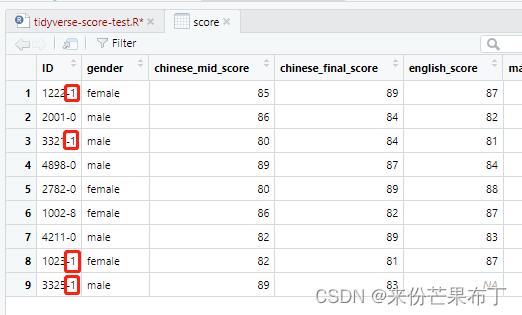
根据 ID 修改
str_detect(score$ID,"-1")

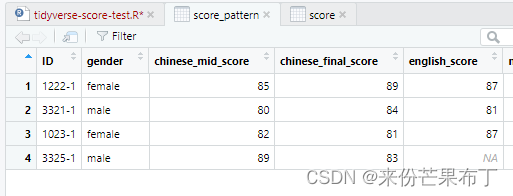
score_pattern = score |>
subset(str_detect(ID,"-1") == TRUE)
view(score_pattern)
strsplit("1222-0","-")
strsplit("1222-0","-")[[1]][1]
strsplit("1222-0","-")[[1]][2]

rowrise
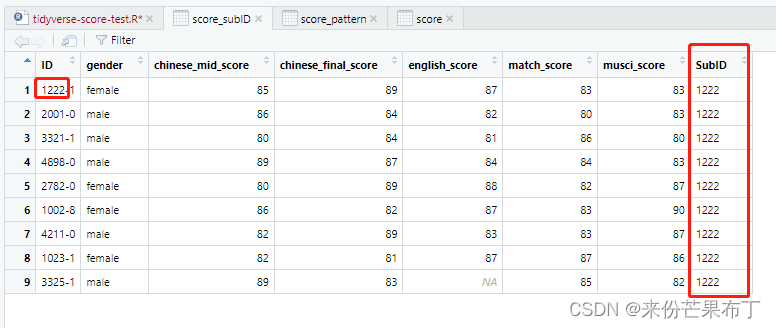
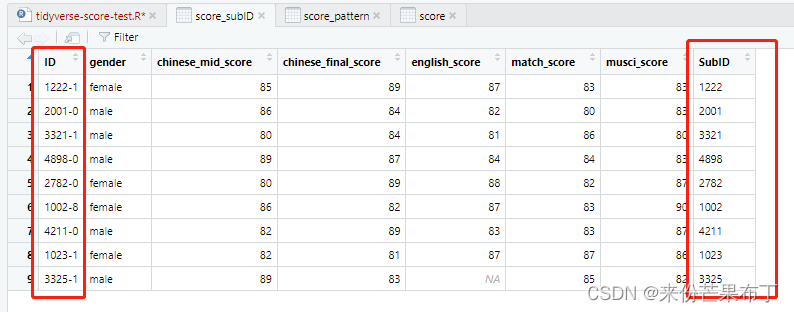
score_subID = score |>
mutate(SubID = strsplit(ID,"-")[[1]][1])
view(score_subID)
在mutate之前加上rowrise可以逐行处理
score_subID = score |>
rowwise() |>
mutate(SubID = strsplit(ID,"-")[[1]][1])
view(score_subID)
case_when
score_case_when = score |>
rowwise() |>
mutate(subID1 = strsplit(ID,"-")[[1]][1]) |>
mutate(subID2 = strsplit(ID,"-")[[1]][2]) |>
mutate(grade = case_when(
subID1>=4000 ~"forth",
subID1>=3000 ~"third",
subID1>=2000 ~"second",
subID1>=1000 ~"first"
))
view(score_case_when)
case_when最难满足的条件放在最前边,最容易满足的条件放在最后
这样计算出来的结果才精准
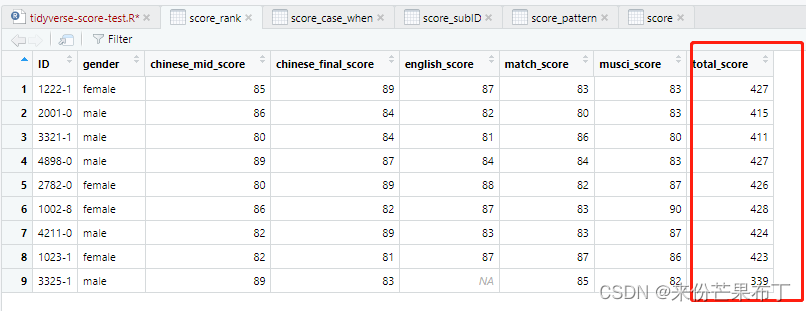
对 行 求和
rowwise()很重要,不加的话会出现计算问题
score_rank = score |>
rowwise() |>
mutate(total_score=sum(chinese_mid_score,chinese_final_score,english_score,match_score,musci_score,na.rm=TRUE))
view(score_rank)
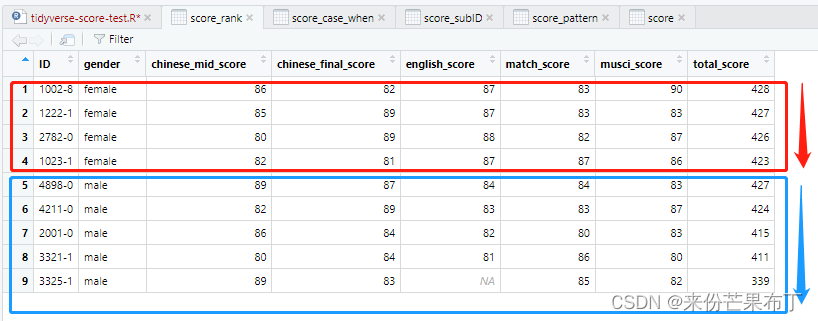
按性别,分数由高到低排序
score_rank = score |>
rowwise() |>
mutate(total_score=sum(chinese_mid_score,chinese_final_score,english_score,match_score,musci_score,na.rm=TRUE)) |>
arrange(gender,desc(total_score))
view(score_rank)
只保留男生女生的最高分,可以用distinct,也可以用slice_max
score_rank = score |>
rowwise() |>
mutate(total_score=sum(chinese_mid_score,chinese_final_score,english_score,match_score,musci_score,na.rm=TRUE)) |>
arrange(gender,desc(total_score)) |>
distinct(gender,.keep_all = TRUE)
view(score_rank)
score_rank = score |>
rowwise() |>
mutate(total_score=sum(chinese_mid_score,chinese_final_score,english_score,match_score,musci_score,na.rm=TRUE)) |>
group_by(gender) |>
slice_max(total_score, n=2)
view(score_rank)

n=2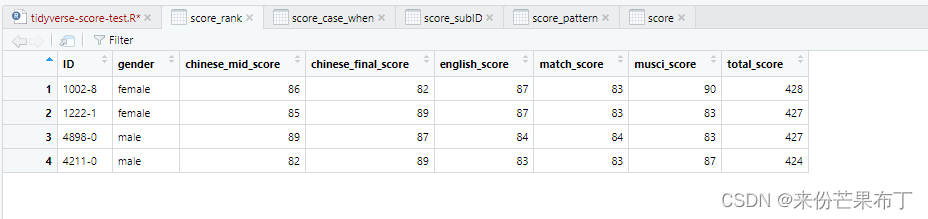
slice_max 有 n 这个参数,可以更灵活控制输出