编者按:大语言模型可以提供许多创意性内容,如写诗、写小说等。那么到底应该如何评估大语言模型生成的创意性内容的水平呢?
本文探讨了GPT-2到GPT-4的创造性,并分析了这些模型在不同创造性测试中的表现。作者使用了三种测试来衡量模型的创造性:Remote Associates Test、Alternate Uses Task和Divergent Association Task,并发现越新的模型在所有创造性任务中表现越来越好。
然而,也存在一些例外,在某些仅有一个“正确”答案的测试中,简单的GPT-2模型比最新的GPT-4模型表现更好。作者认为这些实验旨在衡量模型生成的创意性内容水平,而不是衡量模型本身的创造力。
以下是译文,Enjoy!
作者 | YENNIE JUN
编译 | 岳扬
最近一段时间,人们使用大语言模型(LLMs)创造了许多有创意的内容,比如书籍[1]、微型小说[2]、rap battles[3]和音乐和弦[4]等。但是,我们是否能更全面地衡量这些模型中的创意能力呢?
长期以来,人类的创造力一直是令许多心理学家和心理研究者着迷的领域。自上世纪50年代起[5],心理研究者们创造了一系列创造力测试,可以比较个体的创造力表现和潜力。虽然没有任何一个测试可以完全量化人类的创造力,但这些测试衡量了创造力的不同方面。
本文将分析从2019年至2023年GPT模型在能够衡量两种创造性的测试下的表现:收敛性(只存在单一的正确解决方案)和发散性(开放式的测试;可能存在多种解决方案) 。这些测试包括:
- 使用第四个词连接三个看似不相关的单词(Remote Associates Test[6])
- 为日常物品提供尽可能多的替代用途(Alternate Uses Task[7])
- 列举出尽可能相互之间差异最大的十个名词(Divergent Association Task[8])
通过对这些测试结果进行分析,我专注于早期的GPT-2模型到最新的GPT-4模型的表现变化。通过运用主观和客观的视角,来理解这些模型的行为。一般而言,后期的模型在所有创造性任务中的表现都会越来越好。但是我发现了几个例外,当测试中仅有一个“正确”答案时,简单的GPT-2模型比最新的GPT-4模型表现更好。同时,我将GPT模型与人类在同样的创造性测试上的表现进行了比较。
注:这些实验旨在衡量模型生成的创意性内容的水平,而不是衡量模型本身的创造力。我并不认为GPT模型或一般的LLMs像人类那样拥有创造性思维。相反,我的目的是展示这些模型如何对特定的创意性性测试进行响应。
GPT模型的发展历程
生成式预训练Transformer(GPT)是一种语言模型,其在互联网中大量的语料内容中进行训练,基于前一个token预测下一个token。尽管最近几个月ChatGPT引起了公众的关注,但OpenAI的GPT模型(以及模型背后的技术)已经存在几年了。
-
GPT-1(2018年,117M参数)。这是最原始的GPT模型。我使用了HuggingFace上的开源版本[9]。然而,输出结果不太妙,所以在本篇文章中我没有记录任何GPT-1的输出。
论文:Improving Language Understanding by Generative Pre-Training[10]
-
GPT-2(2019年,15B 参数)。我使用了HuggingFace上的开源版本[11]。对于一些实验, GPT-2的输出毫无意义,对于理解其行为没有用处,因此我在相应的分析中没有记录这些内容。
论文:Language Models are Unsupervised Multitask Learners[12]
-
GPT-3(2020年,175B 参数)。比GPT-2大100多倍。我使用了OpenAI APIs[13]上的text-davinci-002。
论文:Language Models are Few-Shot Learners[14]
-
GPT-3.5(2022年)。虽然有多个版本的GPT-3.5,但我使用了与最初ChatGPT[15]使用的模型相同的模型,该模型使用强化学习和人类反馈进行训练。我使用了OpenAI APIs上的gpt-3.5-turbo[16]。
-
GPT-4(2023年,约100T 参数)。我使用了OpenAI APIs上的gpt-4。
论文:GPT-4 Technical Report[17]
在本文的所有实验中,除非特别提到,否则针对每个唯一的Prompt,我调用每个GPT模型五次,这样主要考虑其生成内容具有的随机性。
01 远距离联想测验: 连接不相关的词
远距离联想测验(Remote Associates Test,RAT)是Martha Mednick于1962年开发的一种创造力测试。这个测试主要衡量收敛性思维,也就是说每个问题都只有一个“正确”的答案。
给定三个看似不相关的单词,参与者必须找到第四个单词来连接这三个单词。 例如,“dream”、“break”和“light”可以通过单词“day”(daydream,daybreak,daylight)进行连接。单词“sense”、“courtesy”和“place”可以通过单词“common”连接。
我从Remote Associates Test网站收集了许多单词三元组(triplets),总共有312个问题。每个问题的难度都评级在非常容易到非常困难的一个范围内。

Remote Associates Test网站上的远距离联想测验问题分类
对于每种模型和每个单词三元组,我都使用了以下Prompt模板。考虑到模型回答的随机性,我调用了每个模型5次。
You are given three words. Think of a fourth word that is somehow related to each of the first three words. First give the answer ("Answer") then explain your reasoning ("Reason").
Words: {Word1}, {Word2}, {Word3}
新GPT模型在远距离联想测验中得分更高
我计算了每个版本的GPT模型生成的答案正确率,能够发现较新版本的GPT模型生成的正确答案更多,这并不令人意外。
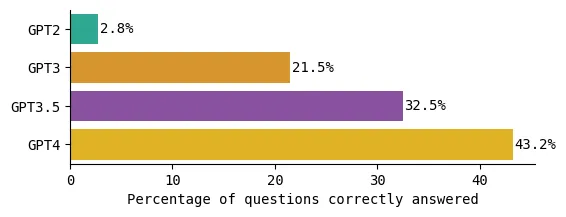
按问题的难度水平划分对模型性能进行分析表明,较新的GPT模型在每个难度区间上的表现都比旧模型更好。虽然较新的GPT模型在难度为困难的问题上表现优于之前版本的模型,但是对处理困难问题的改进程度比处理容易的问题小得多。这意味着即使是GPT-4也会在难度为困难的问题上遇到困难。

根据Remote Associates Test网站描述,“一般人可以解决大多数难度为容易的题目,大约一半的中等难度题目,很少有难题。”该网站没有公布正式的统计数据,但快速浏览可以发现,GPT-4确实解决了大约一半的“medium”难度题目和一些难度为“hard”的题目,成为唯一与人类水平接近的模型。其他GPT模型的表现都不如人类。
几种例外情况:GPT-2回复正确而GPT-4回复错误
虽然发生频率不高,但有一些问题,2019年的GPT-2模型能够生成正确答案,而2023年的GPT-4模型无法解决。在我们的测试中有8个这样的问题(完整列表附在文章结尾的附录中)。
An easy question
Words: cottage / brick / cake
GPT-2: “cheese” [correct answer]
GPT-4: “layer”
A medium question
Words: cat / number / phone
GPT-2: “call”
GPT-4: “dial”
A hard question
Words: through / disk / way
GPT-2: “drive” [correct]
GPT-4: “circle”
A very hard question
Words: land / hand / house
GPT-2: “farm” [correct]
GPT-4: “property”
请注意,对于这些问题,GPT-4的答案都并非是不合理的。事实上,在不知道正确答案的情况下,你可能会认为GPT-4的答案有可能与这三个单词具有联系。如果你这么想,你并没有错。我将在下一节中介绍这个问题。
GPT-4是回答错了还是只是在跳出框架思考?
GPT-4回答了一半以上的问题,可能都有充分的理由。我要求GPT-4解释其每个答案。然后,我看到了一些难度为“Very Hard”的问题的解释是错误的。
Words: artist / hatch / route
- 正确答案: “escape”
- GPT-4 的回答: “map”
The word "artist" might bring to mind the idea of creating something, perhaps even a visual representation of something. Maps are a common form of visual representation that require a degree of artistic skill to create.
The word "hatch" could refer to the act of opening something or bringing something into existence. A map is a type of blueprint or plan, often used to navigate new territory or chart out a course of action.
The word "route" is related to direction and movement, which can be plotted and tracked on a map. A map can help you determine the best route to take when traveling, and can also provide information about the routes others have taken in the past.
All in all, "Map" seems to be a word that fits well with each of the three initial words, as it encapsulates the ideas of artistic creation, planning and direction, and movement and navigation.
GPT-4解释为什么“map”与“artist / hatch / route”联系紧密的原因是能够令我赞同的。
以下是另一个例子:
Words: fork / dark / man
- 正确答案: “pitch”
- GPT-4 的回答: “shadow”
The word "fork" can be associated with division or branching, such as a fork in the road. Shadows can also be seen as a type of division, as they represent the absence of light.
The word "dark" refers to the absence of light. Shadows are created when light is blocked by an object, and can often appear darker than the surrounding area.
The word "man" can be associated with the concept of identity or individuality. Shadows can also be used to represent the identity of a person, as they can provide clues about their shape and size.
Therefore, "Shadow" seems to be a word that fits well with each of the initial three words, as it encapsulates the ideas of division, absence, and identity.
这些例子表现了Remote Associates Test以及其他一般的收敛性创造力测试的缺陷,即 “正确”答案可能不是唯一的“正确”答案。在这些案例中,GPT-4生成了一个“错误”的答案,但只是因为它没有符合所谓的“正确”答案。
事实上,如果我要求GPT-4为三个单词组想出多个第四个单词的答案,它能够给我多个答案,并且似乎都是可行的。

对于任意生成的三个单词组,GPT-4会如何回答
GPT模型有可能在训练数据中见过上述远距离联想测验(Remote Associates Test,RAT)的问题。那么,如果给出任意生成的三个单词,GPT-4会如何回答呢?在本节中,我构建了自己的“remote association”测试并主观地评估输出。
我列出了最常用的《英语单词10000词》清单[18]。然后我随机从这份清单中选取三个单词,让GPT-4提供将这些单词联系在一起的第四个单词。有些三个单词的组合非常奇怪且不相关,但是GPT-4总能找到将它们联系在一起的方法。建议读者在阅读GPT-4生成的结果之前先尝试这些例子!
在看完接下来的几个例子后,你应该可以做出判断——GPT-4是跳出框架思考?还是只是敷衍了事地回答?(本文末尾的附录中展示了更长的例子列表)
⛑️ Health
这个回答听起来相当令人信服。但有趣的是,“健康监测(health surveillance)”的定义几乎照搬自CDC网站关于公共卫生监测介绍的内容[19]。
Public health surveillance is “the ongoing, systematic collection, analysis, and interpretation of health-related data essential to planning, implementation, and evaluation of public health practice.” — Field Epidemiology
(from the CDC website)
Words: dietary / surveillance / born
Answer: Health
Reason:
1. Dietary - A person's diet is directly related to their health, as it can affect their overall well-being, energy levels, and risk for certain diseases.
2. Surveillance - Health surveillance is the ongoing, systematic collection, analysis, and interpretation of data essential to the planning, implementation, and evaluation of health practice.
3. Born - When a person is born, their health is of utmost importance, as it can have long-lasting effects on their development, growth, and overall quality of life.
🍀 Clovers
一开始我被GPT-4的回答所说服——事实上,GPT-4听起来非常聪明。但是,当我进行谷歌搜索,发现Trifolium duodecim这种说法并不存在的时候,我就不那么确信了。这可能是大模型的一个“幻觉”例子,即LLM会编造一个不准确的答案。
Words: lucky / field / twelve
Answer: Clover
Reason:
1. Lucky - A four-leaf clover is considered a symbol of good luck.
2. Field - Clovers are plants that can be commonly found growing in fields.
3. Twelve - There is a variety of clover known as "Trifolium duodecim" (Twelve-leaf clover), which has 12 leaflets.
☕️ Starbucks
这个例子是我最喜欢的,尽管它有跳出思维定势的感觉,但仍有点牵强附会。甚至有点好笑(特别是关于Patrick的那部分)。
Words: grande / cognitive / patrick
Answer: Starbucks
Reason:
1. Grande: Starbucks uses the term "grande" to refer to one of its medium-sized drinks.
2. Cognitive: Starbucks is a popular place for people to go to relax, study, and work, which are all activities that require cognitive function.
3. Patrick: Patrick Dempsey, the actor who played Dr. Derek Shepherd on the television show Grey's Anatomy, is known for his love of coffee and was nicknamed "McDreamy." Starbucks is a well-known coffee shop, so it's possible that his character would have frequented Starbucks.
这些例子和案例分析说明,仅有一个正确答案的创造力测试可能存在限制。在本文的下一部分中,将会探讨其他不受此限制的测试。
02 替代用途任务测试: 发掘普通物品的其他用途
另一种常用的测试创造力的方法是选择替代用途任务(Alternative Uses Task,AUT)测试。该测试目的是让人们发掘日常物品的更多使用方式,以此评估他们的创造力。该测试由J·P·吉尔福德(J. P. Guilford)于1967年创建,与“远距离联想测验”不同,它测量的是发散性思维,也就是说没有正确答案。
测试参与者需要尽可能多地提出日常物品的用途,例如,“laptop(笔记本电脑)”可以用作“plate(盘子)”,用作“body shield(身体护盾)”,或者用作“wall art(墙面艺术)”。这些回答的原创性和思路的灵活性将被用来衡量创造力水平,计算方式包含的指标如原创性(用途的差异程度)和灵活性(思路的多样性)。 测试的目的是挖掘出那些普通物品隐藏的更多潜在用途。
然而,由于人工智能的资源和能力有限,难以取代人类智慧,所以即使是使用人工智能进行选择替代用途任务(Alternative Uses Task,AUT)测试,仍须借助人工干预才可得出更加精准的结果。因此,我使用了创造力的替代物(proxy for creativity),阿姆斯特丹大学(University of Amsterdam)的研究人员在Putting GPT-3’s Creativity to the (Alternative Uses) Test [20]中也使用了这个替代物。
在这篇论文中,研究人员要求人类和GPT-3(davinci-002)为以下常见的物体想出其他的用途:叉子、铁罐和书(fork, tin can, and book)。作为衡量创造力的替代品,他们测量了这些物体和生成的用途之间的语义距离(semantic distance)——也就是说,生成的用途与这些物体之间有多大区别?
我从该论文的项目网站[21]上获取了人类的回答,以便与人类的表现进行比较。我在GPT模型中使用了以下Prompt(基于论文中使用的类似prompt)。
Come up with 10 creative uses for the following item that might strike people as clever, unusual, interesting, uncommon, humorous, innovative, or different: {item}
基于嵌入余弦距离的创造力评判替代物
在自然语言处理中,语义距离(或语义相似度 [22] )被用作衡量两个单词相关性的指标,它基于这些单词在相似上下文中一起使用的频率。 例如,“电脑(computer)”和“屏幕(screen)”这两个词可能具有更短的语义距离,因为它们经常在相同的上下文中同时使用,而“电脑(computer)”和“扁豆(lentils)”这两个词之间的语义距离可能更大,因为它们不常在相同的上下文中同时出现。
为了计算两个单词之间的语义距离,我采用了上述研究论文中所使用的方法[23]。通过使用Spacy(en_core_web_lg)这个自然语言处理库,来计算对象(例如,“笔记本电脑(laptop)”)和用途词(例如,“盘子”)的词嵌入。然后,我使用了两个词嵌入间的余弦距离来计算它们之间的语义距离。
对于替代用途任务(Alternative Uses Task,AUT)测试,较大的语义距离意味着更具“创造性”的物品用途。研究结果表明,在三个物品(叉子、易拉罐和书)中,与人类表现相比,GPT-3生成的余弦距离较低(因此人类的表现具有更高的语义差异性) 。然而,在某些情况下,GPT-3.5或GPT-4的创造力语义距离分数可以匹敌或超越人类表现。

尽管人类倾向于提出比GPT-3提出的更具创造性的物品用途(使用余弦距离所计算的语义距离来替代创造力),但GPT-4的表现已经接近于人类水平。也就是说,GPT-4的回复与原始项(original item)之间的语义距离较大,而其表现与人类表现相似。然而,如果没有人类对主观类别(subjective categories)如原创性、灵活性和实用性进行注释和决定,则使用余弦距离进行的量化仅能测量GPT模型创造性产出的一小部分,因此受到限制。
你能区分由人类还是AI生成的物品用途吗?
其中一个列表显示了人类给出的易拉罐(tin can)替代用途,另一个列表则给出了GPT-4生成的替代用途。你能发现区别吗?答案在下面。
List 1: Uses for tin can(易拉罐的替代用途)
- as a mirror(镜子)
- to create toys(制作玩具)
- as art(艺术品)
- as a reminder of Andy Warhol(安迪·沃霍尔风格的产品)
- as a key ring with the clip from the can(用罐子的夹子当钥匙圈)
- as jewelry(饰品)
List 2: Uses for tin can(易拉罐的替代用途)
- miniature drum set 迷你鼓套装
- quirky plant pot 古怪的植物盆
- impromptu cookie cutter 临时的饼干切割器
- homemade camp stove 自制露营炉
- whimsical wind chimes 异想天开的风铃
- miniature herb garden 微型植物园
下一节的测试也是测量发散性思维。
03 发散联想任务: 生成十个没有联系的词
第三个创造力测试是发散联想任务(DAT),是由研究人员在2021年创建的。这个测试,正如其名是发散性的,也没有正确答案。
在这个网站上有一个测试的版本。它只需要几分钟的时间,因为其涉及到尽可能不相关的十个名词的列表。这是我在该网站上的测试结果:

DAT分数 The DAT Score
有读者会疑问该分数是如何计算的,作者在此处描述了他们的分数计算过程。 DAT分数是使用嵌入(embeddings)和余弦距离(cosine distance)进行计算的。 我改编了计算分数的过程:
- 计算每个词的GloVe嵌入
- 计算每对单词之间的余弦距离
- 取这个值的平均值
这个过程类似于计算替代用途任务(Alternative Uses Task,AUT)中的创造力评判替代物得分的方法,唯一的区别是使用的词嵌入模型。
比较模型之间的差异性
下面的Prompt用于GPT模型,它是从DAT网站[24]上获取的。
Please enter 10 words that are as different from each other as possible, in all meanings and uses of the words.
Rules
- Only single words in English.
- Only nouns (e.g., things, objects, concepts).
- No proper nouns (e.g., no specific people or places).
- No specialized vocabulary (e.g., no technical terms).
- Think of the words on your own (e.g., do not just look at objects in your surroundings).
下面的结果没有包含GPT-2,因为GPT-2输出的内容是胡言乱语。 (可以在文章末尾的附录中看到这个例子)
结果显示,越新模型的DAT得分越高。 这意味着更新的模型在完成生成不同语义的10个单词任务时做得更好。

例如,由GPT-3生成的以下单词列表的DAT得分是0.36:
dusk, night, day, dawn, morning, afternoon, evening, midnight, twilight
另一方面,由GPT-4生成的以下单词列表的得分是0.95:
elephant, microscope, sandcastle, galaxy, harmony, spatula, glacier, philosophy, tambourine, drought
根据介绍DAT测试的论文,得分通常在65到90之间,平均分在75到80之间。95分被认为是非常高的分数。
需要注意的是上图中GPT-4的误差条(error bars)比GPT-3小得多。这一点在下一个实验中将变得更加明显,因为我会通过调整“temperature”参数来改变每种GPT模型生成回复中的随机性。
“temperature”是介于0和1之间的值,接近0的值最容易预测,而1则是最随机的。 我尝试了0.5到0.9之间以0.1为增量的temperature值(在之前的实验中,我将“temperature”保持在默认值0.7)。我预计“temperature”越高变化越大,而“temperature”越低则会越稳定。
然而,结果表明,相较于语义距离(semantic distance)的差异方面,“temperature”并不像模型那样重要。 对于GPT-3,尽管“temperature”不同,每个由10个单词组成的单词列表的DAT分数差别很大。而对于GPT-4,尽管“temperature”不同,DAT分数仍在一个小范围内保持紧密一致,变化非常小。
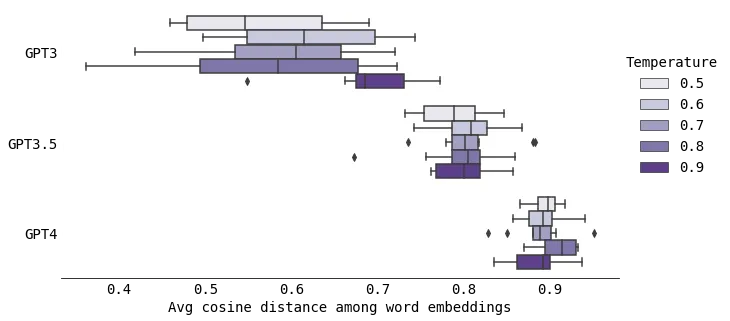
当我看到这三个版本的GPT模型生成的文本内容时,这一点变得更加清晰。相较于GPT-3,GPT-4生成的文本变化要小得多。在某种程度上,感觉GPT-4已经知道了一个本来应该没有正确答案的任务的“正确答案”。
针对所有“temperature”分数的反应,我让每个版本的GPT模型生成50次由10个单词组成的列表,然后查看不同单词在所有50次运行中出现的频率。需要注意的是,GPT-3最常生成的单词是book,在50次中出现了19次,即38%。而另一方面,GPT-4最常生成的单词是microscope,在50次中出现了48次,即96%。

这验证了GPT-3在生成单词方面实际上更具有可变性,而GPT-4则通过预测大量它知道会在“多样化单词(diverse words)”任务中得分高的相同单词——比如microscope、volcano、elephant和galaxy等单词,来保证回复的安全、可靠。
这一发现说明GPT-4似乎已经“破解”了生成它所认为的多样化词汇的密码。如果是这样的话,我不确定能否自信地说GPT-4是在发挥创造力,而不是在“如何最好地玩这个生成多样化词汇的游戏”方面达到了局部优化。
04 Conclusion 结论
“We can imagine a future in which GPT-3 and other generative LLMs responses cannot be distinguished from humans, although the creative process will be different.”
“我们可以想象,在未来GPT-3和其他生成性LLMs的回复几乎会和人类很相似,尽管创作过程会有所不同。”
— from Putting GPT-3’s Creativity to the (Alternative Uses) Test
使用一套有限的基于文本的测试来准确测量像创造力这样复杂和多面的东西是十分具有挑战性的。尽管 Visual Remote Associates Test 试图通过引入视觉元素来解决这个问题,但这种评估仍然存在固有的局限性。收敛性测试(如Remote Associates Test)有一个“正确答案(right answer)”,可能这个“right answer”并不总是最有创造力或最正确的解决方案。另一方面,发散性测试(如Divergent Association Test))没有特定的正确答案,依赖于不完美的词嵌入(word embeddings), 可能包含偏见。
此外,GPT模型在这些测试中的表现可能会受到其在训练过程中所接触到的任务的影响,可能导致数据交叠(data overlap)。例如,GPT-4在Divergence Association Test上的表现展示出了奇怪的单词重复,这表明其可能先前已经知道了正确的答案。现在开发其他替代的测试方法至关重要,因为有传言称GPT-4在测试数据上进行了训练,特别是在代码编写任务中。
尽管存在这些限制,创造力测试仍然可以作为比较和跟踪(comparing and tracking)大语言模型性能的基准(benchmarks)。未来可以在其他语言中重复本文的实验测试,以此来评估GPT模型在不同语言领域的创造力。 通过这样做,我们可以更全面地了解AI生成的内容,并进一步探索这些高级语言模型的能力和局限性。
05 附录
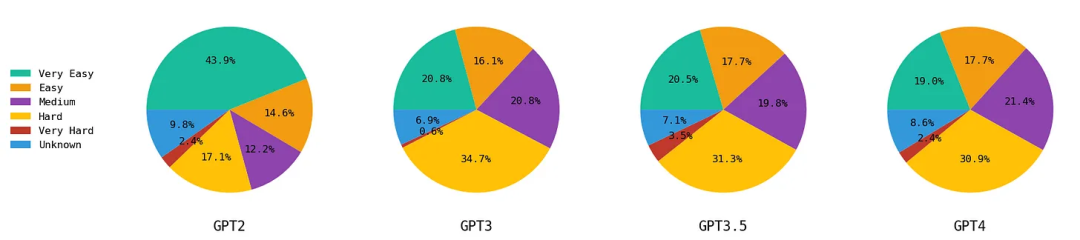
Remote Association Test:GPT模型正确回答问题的情况比较
我们可以查看每个模型能够正确回答的问题难度水平的分布情况。我们可以看到,GPT3、GPT3.5和GPT4在回答困难问题的能力比例上相似。
在Remote Association Test中GPT-2回答正确,而GPT-4回答错误的情况
Words: cat / number / phone
Level: Medium
Answer: call
GPT2: call
GPT4: dial
Words: land / hand / house
Level: Very Hard
Answer: farm
GPT2: farm
GPT4: property
Words: water / pen / soda
Level: Unknown
Answer: fountain
GPT2: fountain
GPT4: liquid
Words: measure / worm / video
Level: Very Easy
Answer: tape
GPT2: tape
GPT4: length
Words: cottage / brick / cake
Level: Very Easy
Answer: cheese
GPT2: cheese
GPT4: layer
Words: through / disk / way
Level: Hard
Answer: drive
GPT2: drive
GPT4: circle
Words: skunk / kings / boiled
Level: Very Easy
Answer: cabbage
GPT2: cabbage
GPT4: smell
Words: jump / kill / bliss
Level: Hard
Answer: joy
GPT2: joy
GPT4: height
GPT-4对随机生成的 Remote Association Test 问题的回答
下面是GPT-4对一些随机产生的 Remote Association Test 问题的回答。
Rings(戒指)
这一个回答让人感觉有点牵强附会。如果你对你的爱情生活或其他事情感到超级厌倦,我可以接受戒指是 "复杂的象征,特别是在某一段关系中 "这一部分,但最后一部分感觉很勉强。
Words: complications | saturn | drops
Answer: Rings
Reason:
1. Complications: Rings can be a symbol of complications, especially in relationships, as they represent commitment and the complexities that come with it.
2. Saturn: Saturn is famously known for its beautiful and prominent rings, made primarily of ice particles and some rocky debris.
3. Drops: A ring can be seen as a drop or loop of material, such as metal or plastic, that forms a complete circle.
Revolution(革命)
Monte Cassino[26]的确是一个真实的地方,它在二战期间的确被轰炸过。
Words: belfast | movement | monte
Answer: Revolution
Reason:
1. Belfast is a city in Northern Ireland that has experienced significant political and social changes due to the Irish Republican movement.
2. Movement is a general term that can describe political and social changes, often caused by revolutions.
3. Monte is likely referring to Monte Cassino, a historic site in Italy where a significant battle occurred during World War II, which was a time of global revolution and change.
Therefore, the word "revolution" is related to each of the first three words as it represents significant change and upheaval.
Help(帮助)
通过帮助中心(help centers)将 "Southampton"城市与 "帮助(help)"联系起来的一种有趣的方式…
Words: ensures | assistant | southampton
Answer: Help
Reason:
1. Ensures: "Help" is related to "ensures" as it is an action that can ensure the success or completion of a task.
2. Assistant: "Help" is related to "assistant" because an assistant provides help in various tasks and activities.
3. Southampton: "Help" is related to "Southampton" as Southampton is a city in England which has various help centers and services, such as the Southampton Voluntary Services, providing assistance to the community.
Internet
我想它的观点是非常正确的。
Words: uruguay | accessible | requirement
Answer: Internet
Reason: Uruguay has a government initiative called Plan Ceibal, which aims to make the Internet accessible to all its citizens, fulfilling a requirement for digital inclusion and reducing the digital divide.
Language
也许有点笼统,但我想它是有效的。
Words: compensation | atlas | prefix
Answer: Language
Reason:
1. Compensation - In linguistics, compensation is a phenomenon where a sound change in one part of a word is "compensated" by a change in another part of the word to maintain the overall structure of the word.
2. Atlas - An atlas is a collection of maps, which often include labels and descriptions in a specific language.
3. Prefix - A prefix is a morpheme or a linguistic element that is added to the beginning of a word to create a new word with a different meaning, which is a concept in language and grammar.
Health
health surveillance部分有点dark,但我想它的回答是有效的。
Words: dietary | surveillance | born
Answer: Health
Reason:
1. Dietary - A person's diet is directly related to their health, as it can affect their overall well-being, energy levels, and risk for certain diseases.
2. Surveillance - Health surveillance is the ongoing, systematic collection, analysis, and interpretation of data essential to the planning, implementation, and evaluation of health practice.
3. Born - When a person is born, their health is of utmost importance, as it can have long-lasting effects on their development, growth, and overall quality of life.
ERIC
这个回答其实很有趣。
Words: eric | figures | purchasing
Answer: accountant
Reason: An accountant is a professional who can be named Eric, works with figures (numbers), and is often involved in purchasing decisions for businesses.
Divergent Association Test 中GPT-2的输出
我在发散性测试的分析中排除了GPT-2,因为它的输出完全是无意义的。即使我尽可能地简化Prompt,它的输出也没有什么意义。我在这里提供一个样例,因为我认为它们实际上还是非常有趣的。
List 10 words that are as different from each other as possible:
"Merry Christmas"
"I'm not a robot, we're the robots"
"It's a good thing we're all robots"
"I'm just a robot"
"I'm just a robot"
"I'm just a robot"
"I'm just a robot"
"I'm not a robot"
"I'm just a robot"
"I'm just a robot"
END
参考资料
1.https://www.reuters.com/technology/chatgpt-launches-boom-ai-written-e-books-amazon-2023-02-21/
2.https://blog.yenniejun.com/p/creative-writing-with-gpt-3-from
3.https://twitter.com/mehran__jalali/status/1639846978850021377?lang=en
4.https://towardsdatascience.com/using-chatgpt-as-a-creative-writing-partner-part-2-music-d2fd7501c268
5.https://www.ideatovalue.com/podc/nickskillicorn/2021/04/the-1950-speech-that-started-creativity-research/
6.https://en.wikipedia.org/wiki/Remote_Associates_Test
7.https://en.wikipedia.org/wiki/Guilford's_Alternate_Uses
8.https://en.wikipedia.org/wiki/Divergent_Association_Task
9.https://huggingface.co/openai-gpt
10.https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
11.https://huggingface.co/gpt2
12.https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
13.https://platform.openai.com/docs/models/gpt-3-5
14.https://arxiv.org/pdf/2005.14165.pdf
15.https://en.wikipedia.org/wiki/ChatGPT
16.https://platform.openai.com/docs/models/gpt-3-5
17.https://arxiv.org/pdf/2303.08774.pdf
18.https://github.com/first20hours/google-10000-english
19.https://www.cdc.gov/training/publichealth101/surveillance.html#anchor_available_materials
20.https://arxiv.org/pdf/2206.08932.pdf
21.https://osf.io/vmk3c/?view_only=
22.https://en.wikipedia.org/wiki/Semantic_similarity
23.https://arxiv.org/pdf/2206.08932.pdf
24.https://www.datcreativity.com/task
25.https://www.pnas.org/doi/10.1073/pnas.2022340118
26.https://en.wikipedia.org/wiki/Monte_Cassino
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://blog.yenniejun.com/p/exploring-creativity-in-large-language