电商评论文本情感分类(中文文本分类+中文词云图)
第一部分
第二部分Bert部分
本项目包含:
1.中文文本处理
2.中文词云图绘制
3.中文词嵌入
4.基于textcnn的中文文本分类(Test_Acc=89.2000)
5.基于bert的中文文本分类(Test_Acc=0.91)
其他说明
完整代码获取
👉点击下方链接跳转,可以在线运行点击这里跳转
因为代码很长,部分Class做了隐藏处理,右上角fork后可展示全部,感觉对你有用的话可以点个赞~
👉本项目分为Bert和TextCNN,通过点击左侧Notebook列表中的Notebook进行不同模型实现的查看
👉textcnn使用cpu即可,Bert使用的是T4-GPU,运行时间:10个epoch大概100分钟
👉部分代码复用了参考文章中的,但是总是会有一些问题,做了部分修改
👉参数没有精调,精调后应该还会有提升
👉代码实在是太长,CSDN分为两个文章发布,第一篇为textcnn,第二篇为bert,建议点击上方链接,fork后也可以把notebook下载下来
往期文章和专栏
👉往期文章可以关注我的专栏
下巴同学的数据加油小站
会不定期分享数据挖掘、机器学习、风控模型、深度学习、NLP等方向的学习项目,关注不一定能学到你想学的东西,但是可以学到我想学和正在学的东西😀
代码
导入相关包
import torch
from torch.utils.data import random_split
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import re
import numpy as np
import pandas as pd
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from collections import defaultdict
import jieba
%matplotlib inline
前期准备
# 固定随机种子
RANDOM_SEED = 2022
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device
数据导入、清洗和检查
data = pd.read_csv('/home/mw/input/comment4cls4805/text2cls.csv')
data.drop('Unnamed: 0',axis=1,inplace=True)
data.head()

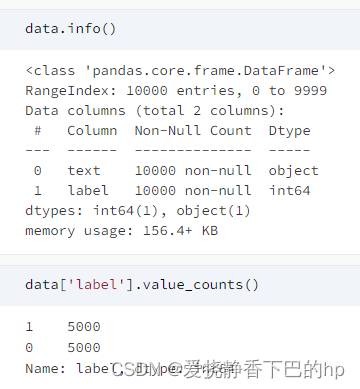
data['text_len']=data['text'].map(len)
data['text'].map(len).describe()
单击部分隐藏输出,双击全隐藏
count 10000.000000
mean 109.083700
std 126.177622
min 4.000000
25% 34.000000
50% 69.000000
75% 135.000000
max 1985.000000
Name: text, dtype: float64
文本清洗
#定义删除除字母,数字,汉字以外的所有符号的函数
def remove_pun(line):
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")
line = rule.sub('',line)
return line
##读取停用词表
stopwords = [line.strip() for line in open('/home/mw/input/stop6931/中文停用词库.txt', 'r', encoding='gbk').readlines()]
##字符清理
data['clean_text'] = data['text'].map(lambda x:remove_pun(x))
##结合停用词表进行分词
data['cut_text'] = data['clean_text'].apply(lambda x: " ".join(w for w in jieba.lcut(x) if w not in stopwords))
Building prefix dict from the default dictionary …
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.725 seconds.
Prefix dict has been built successfully.
词云图展示
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
from PIL import Image
# background_image = np.array(Image.open("/home/mw/project/p.jpg"))
fig,ax = plt.subplots(figsize=(12,8), dpi=100)
mytext = ''
for i in range(len(data)):
mytext += data['text'][i]
# wcloud = WordCloud(width=2400, height=1600,background_color="white",stopwords=stopwords,mask = background_image).generate(mytext)
wcloud = WordCloud(width=2400, height=1600,font_path=r'/home/mw/project/NotoSansHans-Black.otf').generate(mytext)
plt.imshow(wcloud)
plt.axis('off')

使用torchtext进行词嵌入
新学的,还不是很熟悉,研究了小半天才成功😀
import torchtext
from torchtext.data import Field,Example,Dataset
from torchtext import vocab
切分数据
df_train, df_test = train_test_split(data, test_size=0.2, random_state=RANDOM_SEED)
df_val, df_test = train_test_split(df_test, test_size=0.5, random_state=RANDOM_SEED)
df_train.shape, df_val.shape, df_test.shape
((8000, 5), (1000, 5), (1000, 5))
class DataFrameDataset(torchtext.data.Dataset):
def __init__(self, df, fields, is_test=True, **kwargs):
examples = []
for i, row in df.iterrows():
# label = row.label if not is_test else None
label = row.label
text = row.cut_text
examples.append(torchtext.data.Example.fromlist([text, label], fields))
super().__init__(examples, fields, **kwargs)
@staticmethod
def sort_key(ex):
return len(ex.text)
@classmethod
def splits(cls, fields, train_df, val_df=None, test_df=None, **kwargs):
train_data, val_data, test_data = (None, None, None)
data_field = fields
if train_df is not None:
train_data = cls(train_df.copy(), data_field, **kwargs)
if val_df is not None:
val_data = cls(val_df.copy(), data_field, **kwargs)
if test_df is not None:
test_data = cls(test_df.copy(), data_field, True, **kwargs)
return tuple(d for d in (train_data, val_data, test_data) if d is not None)
TEXT = Field(sequential=True, lower=True, fix_length=500,tokenize=str.split,batch_first=True)
LABEL = Field(sequential=False, use_vocab=False)
fields = [('text',TEXT), ('label',LABEL)]
train_ds, val_ds , test_ds= DataFrameDataset.splits(fields, train_df=df_train, val_df=df_val, test_df=df_test)
# 看一个随机的例子
print(vars(train_ds[666]))
# 检查类型
print(type(train_ds[666]))
{‘text’: [‘酒店’, ‘位置’, ‘没得说’, ‘静安寺’, ‘边上’, ‘房间’, ‘里’, ‘一股’, ‘子’, ‘怪味’, ‘窗上’, ‘纱窗’, ‘没有’, ‘一夜’, ‘下来’, ‘两臂’, ‘苍蝇’, ‘蚊子’, ‘叮出’, ‘大包’, ‘点着’, ‘蚊香’, ‘国营企业’, ‘德行’], ‘label’: 0}
<class ‘torchtext.data.example.Example’>
MAX_VOCAB_SIZE = 25000
pretrained_name = 'sgns.sogou.word' # 预训练词向量文件名
pretrained_path = '/home/mw/input/s_w2v2564/' #预训练词向量存放路径
vectors = torchtext.vocab.Vectors(name=pretrained_name, cache=pretrained_path)
TEXT.build_vocab(train_ds,
max_size = MAX_VOCAB_SIZE,
vectors = vectors,
unk_init = torch.Tensor.zero_)
0%| | 0/364990 [00:00<?, ?it/s]Skipping token b’364990’ with 1-dimensional vector [b’300’]; likely a header
100%|██████████| 364990/364990 [00:37<00:00, 9853.04it/s]
LABEL.build_vocab(train_ds)
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = torchtext.data.BucketIterator.splits(
(train_ds, val_ds, test_ds),
batch_size = BATCH_SIZE,
# sort_within_batch = False,
device = device)
模型构建、编译、训练
class TextCNN(nn.Module):
def __init__(self,
class_num, # 最后输出的种类数
filter_sizes, # 卷积核的长也就是滑动窗口的长
filter_num, # 卷积核的数量
vocabulary_size, # 词表的大小
embedding_dimension, # 词向量的维度
vectors, # 词向量
dropout): # dropout率
super(TextCNN, self).__init__() # 继承nn.Module
chanel_num = 1 # 通道数,也就是一篇文章一个样本只相当于一个feature map
self.embedding = nn.Embedding(vocabulary_size, embedding_dimension) # 嵌入层
self.embedding = self.embedding.from_pretrained(vectors) #嵌入层加载预训练词向量
self.convs = nn.ModuleList(
[nn.Conv2d(chanel_num, filter_num, (fsz, embedding_dimension)) for fsz in filter_sizes]) # 卷积层
self.dropout = nn.Dropout(dropout) # dropout
self.fc = nn.Linear(len(filter_sizes) * filter_num, class_num) #全连接层
def forward(self, x):
# x维度[句子长度,一个batch中所包含的样本数] 例:[3451,128]
x = self.embedding(x) # #经过嵌入层之后x的维度,[句子长度,一个batch中所包含的样本数,词向量维度] 例:[3451,128,300]
# print('1',x.shape)
# x = x.permute(1,0,2) # permute函数将样本数和句子长度换一下位置,[一个batch中所包含的样本数,句子长度,词向量维度] 例:[128,3451,300]
# print('2',x.shape)
x = x.unsqueeze(1) # # conv2d需要输入的是一个四维数据,所以新增一维feature map数 unsqueeze(1)表示在第一维处新增一维,[一个batch中所包含的样本数,一个样本中的feature map数,句子长度,词向量维度] 例:[128,1,3451,300]
x = [conv(x) for conv in self.convs] # 与卷积核进行卷积,输出是[一个batch中所包含的样本数,卷积核数,句子长度-卷积核size+1,1]维数据,因为有[3,4,5]三张size类型的卷积核所以用列表表达式 例:[[128,16,3459,1],[128,16,3458,1],[128,16,3457,1]]
x = [sub_x.squeeze(3) for sub_x in x]#squeeze(3)判断第三维是否是1,如果是则压缩,如不是则保持原样 例:[[128,16,3459],[128,16,3458],[128,16,3457]]
x = [F.relu(sub_x) for sub_x in x] # ReLU激活函数激活,不改变x维度
x = [F.max_pool1d(sub_x,sub_x.size(2)) for sub_x in x] # 池化层,根据之前说的原理,max_pool1d要取出每一个滑动窗口生成的矩阵的最大值,因此在第二维上取最大值 例:[[128,16,1],[128,16,1],[128,16,1]]
x = [sub_x.squeeze(2) for sub_x in x] # 判断第二维是否为1,若是则压缩 例:[[128,16],[128,16],[128,16]]
x = torch.cat(x, 1) # 进行拼接,例:[128,48]
x = self.dropout(x) # 去除掉一些神经元防止过拟合,注意dropout之后x的维度依旧是[128,48],并不是说我dropout的概率是0.5,去除了一半的神经元维度就变成了[128,24],而是把x中的一些神经元的数据根据概率全部变成了0,维度依旧是[128,48]
logits = self.fc(x) # 全接连层 例:输入x是[128,48] 输出logits是[128,10]
return logits
class_num = len(LABEL.vocab)-1 # 类别数目,会生成一个开头占位
filter_size = [2,3,4] # 卷积核种类数
filter_num=64 # 卷积核数量
vocab_size = len(TEXT.vocab) # 词表大小
embedding_dim = TEXT.vocab.vectors.size()[-1] # 词向量维度
vectors = TEXT.vocab.vectors # 词向量
dropout=0.5
learning_rate = 0.001 # 学习率
epochs = 5 # 迭代次数
save_dir = '/home/mw/project/' # 模型保存路径
steps_show = 20 # 每20步查看一次训练集loss和mini batch里的准确率
steps_eval = 100 # 每100步测试一下验证集的准确率
early_stopping = 1000 # 若发现当前验证集的准确率在1000步训练之后不再提高 一直小于best_acc,则提前停止训练
textcnn_model = TextCNN(class_num=class_num,
filter_sizes=filter_size,
filter_num=filter_num,
vocabulary_size=vocab_size,
embedding_dimension=embedding_dim,
vectors=vectors,
dropout=dropout)
def train(train_iter, dev_iter, model):
if torch.cuda.is_available(): # 判断是否有GPU
model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 梯度下降优化器,采用Adam
steps = 0
best_acc = 0
last_step = 0
model.train()
for epoch in range(1, epochs + 1):
for batch in train_iter:
feature, target = batch.text, batch.label
if torch.cuda.is_available(): # 如果有GPU将特征更新放在GPU上
feature,target = feature.cuda(),target.cuda()
optimizer.zero_grad() # 将梯度初始化为0,每个batch都是独立训练地,因为每训练一个batch都需要将梯度归零
logits = model(feature)
loss = F.cross_entropy(logits, target) # 计算损失函数 采用交叉熵损失函数
loss.backward() # 反向传播
optimizer.step() # 放在loss.backward()后进行参数的更新
steps += 1
if steps % steps_show == 0: # 每训练多少步计算一次准确率,我这边是1,可以自己修改
corrects = (torch.max(logits, 1)[1].view(target.size()).data == target.data).sum() # logits是[128,10],torch.max(logits, 1)也就是选出第一维中概率最大的值,输出为[128,1],torch.max(logits, 1)[1]相当于把每一个样本的预测输出取出来,然后通过view(target.size())平铺成和target一样的size (128,),然后把与target中相同的求和,统计预测正确的数量
train_acc = 100.0 * corrects / batch.batch_size # 计算每个mini batch中的准确率
print('steps:{} - loss: {:.6f} acc:{:.4f}'.format(
steps,
loss.item(),
train_acc))
if steps % steps_eval == 0: # 每训练100步进行一次验证
dev_acc = dev_eval(dev_iter,model)
if dev_acc > best_acc:
best_acc = dev_acc
last_step = steps
print('Saving best model, acc: {:.4f}%\n'.format(best_acc))
save(model,save_dir, steps)
else:
if steps - last_step >= early_stopping:
print('\n提前停止于 {} steps, acc: {:.4f}%'.format(last_step, best_acc))
raise KeyboardInterrupt
def dev_eval(dev_iter,model):
model.eval()
corrects, avg_loss = 0, 0
for batch in dev_iter:
feature, target = batch.text, batch.label
if torch.cuda.is_available():
feature, target = feature.cuda(), target.cuda()
logits = model(feature)
loss = F.cross_entropy(logits, target)
avg_loss += loss.item()
corrects += (torch.max(logits, 1)
[1].view(target.size()).data == target.data).sum()
size = len(dev_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects / size
print('\nEvaluation - loss: {:.6f} acc: {:.4f}%({}/{}) \n'.format(avg_loss,
accuracy,
corrects,
size))
return accuracy
# 定义模型保存函数
import os
def save(model, save_dir, steps):
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
save_path = 'bestmodel_steps{}.pt'.format(steps)
save_bestmodel_path = os.path.join(save_dir, save_path)
torch.save(model.state_dict(), save_bestmodel_path)
train(train_iterator,valid_iterator,textcnn_model)
steps:20 - loss: 0.529808 acc:80.4688
steps:40 - loss: 0.416786 acc:79.6875
steps:60 - loss: 0.314106 acc:89.0625
steps:80 - loss: 0.289211 acc:89.8438
steps:100 - loss: 0.296632 acc:89.8438
Evaluation - loss: 0.002373 acc: 88.3000%(883/1000)
Saving best model, acc: 88.3000%
steps:120 - loss: 0.226822 acc:89.8438
steps:140 - loss: 0.208629 acc:90.6250
steps:160 - loss: 0.213932 acc:92.1875
steps:180 - loss: 0.329256 acc:88.2812
steps:200 - loss: 0.153643 acc:96.8750
Evaluation - loss: 0.002091 acc: 90.5000%(905/1000)
Saving best model, acc: 90.5000%
steps:220 - loss: 0.200416 acc:92.9688
steps:240 - loss: 0.171485 acc:92.1875
steps:260 - loss: 0.155608 acc:95.3125
steps:280 - loss: 0.109367 acc:96.0938
steps:300 - loss: 0.098254 acc:97.6562
Evaluation - loss: 0.002013 acc: 90.4000%(904/1000)
查看测试集效果
dev_eval(test_iterator,textcnn_model)
Evaluation - loss: 0.002039 acc: 89.2000%(892/1000)
tensor(89.2000)
参考文章
1.Huggingface Transformers实战教程
2.kaggle-pytorch-text-classification-torchtext-lstm
3.中文文本分类
4.中文词向量
5.torchtext-Field详解



![[附源码]JAVA毕业设计酒店订房系统(系统+LW)](https://img-blog.csdnimg.cn/bfec98a533cc436d9431542d36227148.png)