文章目录
- 不同路径
- 不同路径II
- 整数拆分
- 不同的二叉搜索树
动态规划解题五步走:
- 确定dp数组以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
不同路径
力扣传送门:
https://leetcode.cn/problems/unique-paths/description/
-
确定dp数组以及下标的含义:
在本题中dp是一个二维数组,因为这是一个二位的地图,使用dp[i][j]表示在地图原点到 (i,j)这个位置的路径数量。
因此我们到达终点的方案数就是dp[i][j]的值,即 (i,j)等于终点处的(i,j) -
确定递归公式
由题意得在地图上某个点,我们只能向右或者向下走一步,因此要想到达 (i,j)这个位置,我们可以从(i-1,j)即从上往下走,或者从(i,j-1)即从左往右走。这两种方案来到达,因此便可以推导出我们的递推公式:dp[i][j]=dp[i-1][j]+dp[i][j-1]。
注意我们的dp[i][j]存储的走到这个位置的方案数量,因此从上面来的方案数 + 从左边来的方案数 = 我们当前的点的方案数。
-
dp数组如何初始化
可以发现,我们的地图第一行或者第一列上的每一个点都只能有一种方案走到,即一直往右走,或者一直往下走,因此我们的 dp[0][j]应该初始化为1(只有一种方案),dp[i][0]同理也应该初始化为1。 -
确定遍历的顺序
我们要计算 (i,j)处的方案数,因此必须先求得它上面的和左边的方案数,它们两者之和即是(i,j)的方案数,因此要从左往右,从上往下计算。 -
举例推导dp数组
我们来用图描绘一下这个过程:
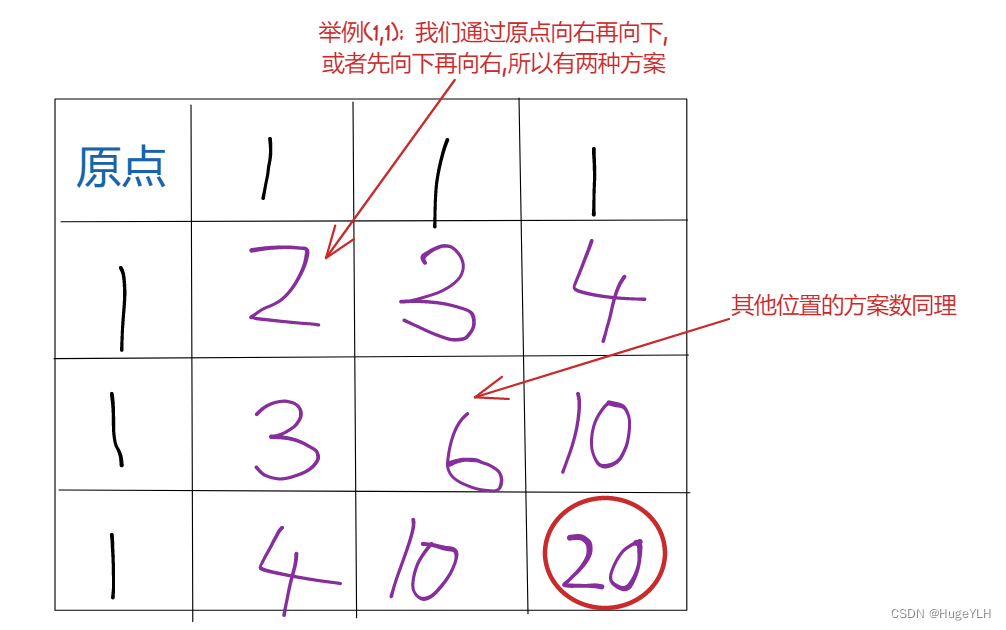
所以我们到达终点(i,j)的方案数就是(i-1,j)的方案数 + (i,j-1)的方案数。
代码如下:
class Solution {
public:
int uniquePaths(int m, int n) {
//dp数组创建
vector<vector<int>> dp(m,vector<int>(n));
for (int i=0;i<m;i++)
{
for (int j=0;j<n;j++)
{
//边界:第一列和第一行只能有一种方案
if (i==0 || j==0)
{
dp[i][j]=1;
}
//其他的位置可以有多种情况
else
{
dp[i][j]=dp[i-1][j]+dp[i][j-1];
}
}
}
//返回终点处的方案数
return dp[m-1][n-1];
}
};
不同路径II
力扣传送门:
https://leetcode.cn/problems/unique-paths-ii/description/
这道题相比第一题多了一个障碍物的概念。
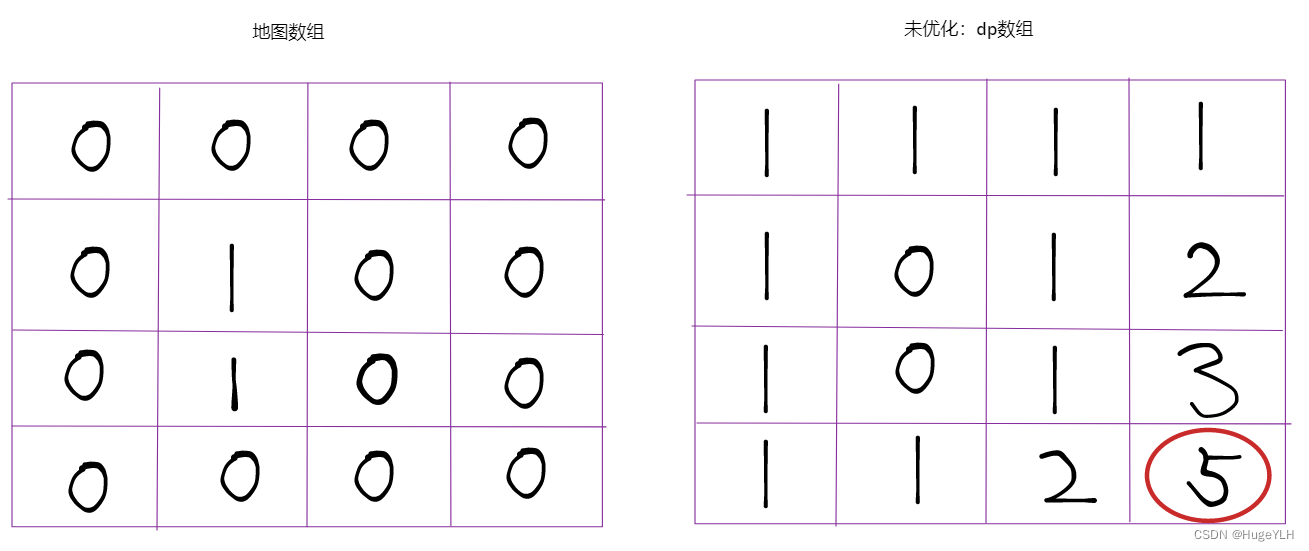
障碍物代表着什么?
如果(i,j)是一个障碍物,则表示在dp[i][j]中此位置的数值是0.
如果dp[i][j]的数值是0,则对于其下一个点来说,例如(i,j+1)就只能由(i-1,j+1)得到,因为(i,j)的dp数值是0,是一个障碍物。
如图: dp数组随着地图的变化依次计算每一位置的数值,最后的结果保存的就是dp数组的最后一个数据。
代码如下:
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m=obstacleGrid.size();
int n=obstacleGrid[0].size();
vector<vector<int>> dp(m,vector<int>(n));
for (int i=0;i<n && obstacleGrid[0][i]==0;i++)
{
dp[0][i]=1;
}
for (int i=0;i<m && obstacleGrid[i][0]==0;i++)
{
dp[i][0]=1;
}
for (int i=1;i<m;i++)
{
for (int j=1;j<n;j++)
{
if (obstacleGrid[i][j]==0)
{
dp[i][j]=dp[i-1][j]+dp[i][j-1];
}
else
{
dp[i][j]=0;
}
}
}
return dp[m-1][n-1];
}
};
时间复杂度:O(nm) 空间复杂度:O(n)
有人就说了,这和上面的那道题不是基本一致的吗,为何要重复在贴一遍呢。
这道题我之所以要在这里在写一遍,是为了引出动态规划的一个非常重要的优化思路:【滚动数组思想】
普通的动态规划是以大量的空间来换取时间的,但是有没有什么办法使得对空间的利用能够减小,而且又能利用动态规划的思想来解决问题呢?
使用优化的动态规划,可以让我们的空间复杂度达到O(1)。
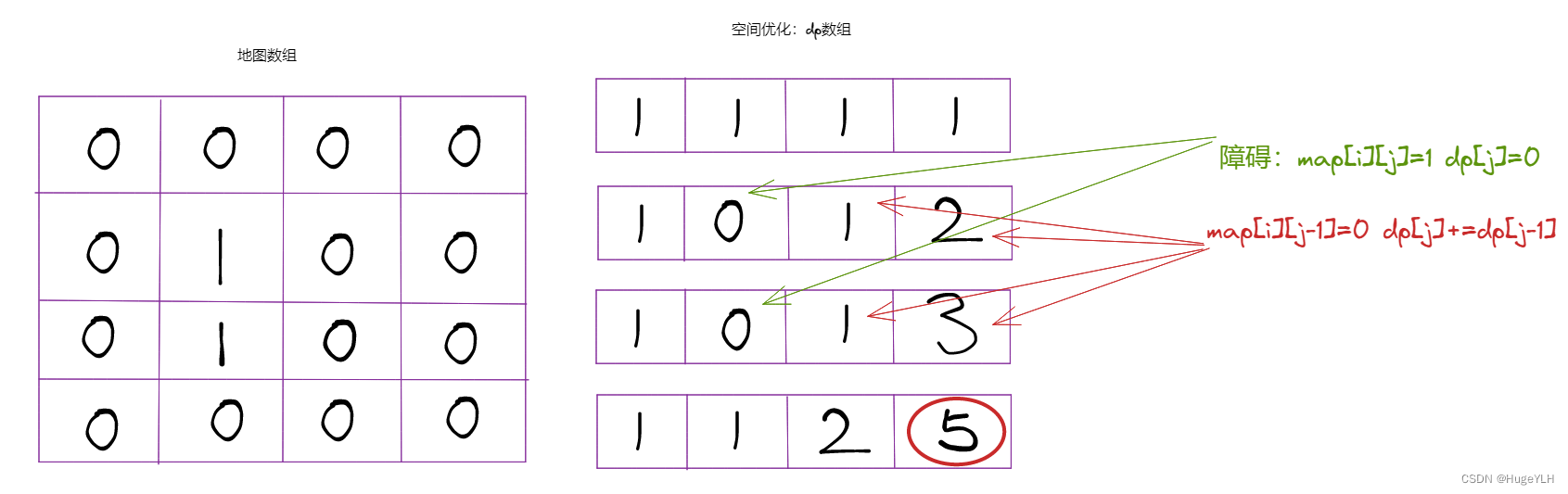
注意看这道题: 我们在dp计算地图的每一个点的数值的时候,我们没有必要创建一个和整个地图一样大的dp数组,而且我们的返回值只有(m-1,n-1)终点这一个dp数组的值,其他的值全部都是多余的,我们只需要一个一维保存当前的行的值即可,然后依次计算按每一行,进行dp数组的更新。
总结一句话就是:我们使用一个dp[j]保存每一行各列的计算结果,然后随着地图的行的更新,我们的dp数组也会更新为每一行数值,直到到达最后一行,最后一个数值即是我们的终点值。
图解:一维进行每一行的各列的计算,如果出现了障碍,则此点置0,否则就加上一个点的数据得到当前点的数据。
代码如下:
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m=obstacleGrid.size();
int n=obstacleGrid[0].size();
//只使用一个一维dp数组,保存的是每一行的值
vector<int> dp(n);
//dp数组首元素的初始化,第一个是不是正常的路
dp[0]=(obstacleGrid[0][0]==0);、
//遍历整个地图
for (int i=0;i<m;i++)
{
for (int j=0;j<n;j++)
{
//如果地图的值为1,则是障碍物,则把dp数组对应的此点置0,即无法通过
if (obstacleGrid[i][j]==1)
{
dp[j]=0;
//直接跳到下一列
continue;
}
//如果地图《上一个位置》的值为0,则表示此位置可以由上一个位置得到,加上左边的位置即可得到当前的位置
if (j-1>=0 && obstacleGrid[i][j-1]==0)
{
dp[j]+=dp[j-1];
}
}
}
//最后存储的即是终点。
return dp.back();
}
};
时间复杂度:O(nm) 空间复杂度:O(1)
整数拆分
力扣传送门:
https://leetcode.cn/problems/integer-break/
假设我们有一个数字:n(n>=2),那么这个n可以被拆分成 x,则另一半就是 n-x。此时我们面临两种选择:
- 我们不需要再分了, x * (n-x) 就是我们拆分的个数相乘的最大值 ,此时 k = 2
- 我们还可以再分: (n-x)还可以继续当作一个新的 n,然后再次回到一开始,把他拆分成x和(n-x)… 那么我们就可以推断出来。这一步的最大值就是我们之前进行相同的操作所得到的最大值,此时 k > 2
由此可见,寻找拆分的整数的最大值其实就是寻找之前的某个拆分的最大值,满足动态规划的思想。
我们按照动态规划五步来进行推理:
-
确定dp数组以及下标的含义。
创建dp[n]一维数组,dp[n]存储的是第n个数的拆分乘积最大值。 -
确定递推公式
经过我们刚才分析的两步可以得出:
当前拆分某一个数字的所有可能的情况:max( x * (n-x),x * dp[n-x] ),注意我们要取得这两种情况的最大值。
当前的数字拆分的最大值: dp[n] = max(dp[n],max( x * (n-x),x * dp[n-x])) -
dp数组如何初始化
由于题目规定了 n>= 2 ,因此我们的准确的初始化从下标为2开始,因为0 1在此题中无效,而且在实际上我们也不需要他们,因此我们只需要:dp[2] = 1,这是公认的,数字2只有一种情况。 -
确定遍历顺序
由于大数的最大值可以由小数的最大值得到,我们依次从小数到大数遍历。 -
推导dp数组:
依次拆分数字x: 1 2 3…一直到n的一半(因为后面的跟前面的是对称的),得到的另一半分别是: n-1 n-2 n-3,然后根据dp公式依次寻找他们的最大值。
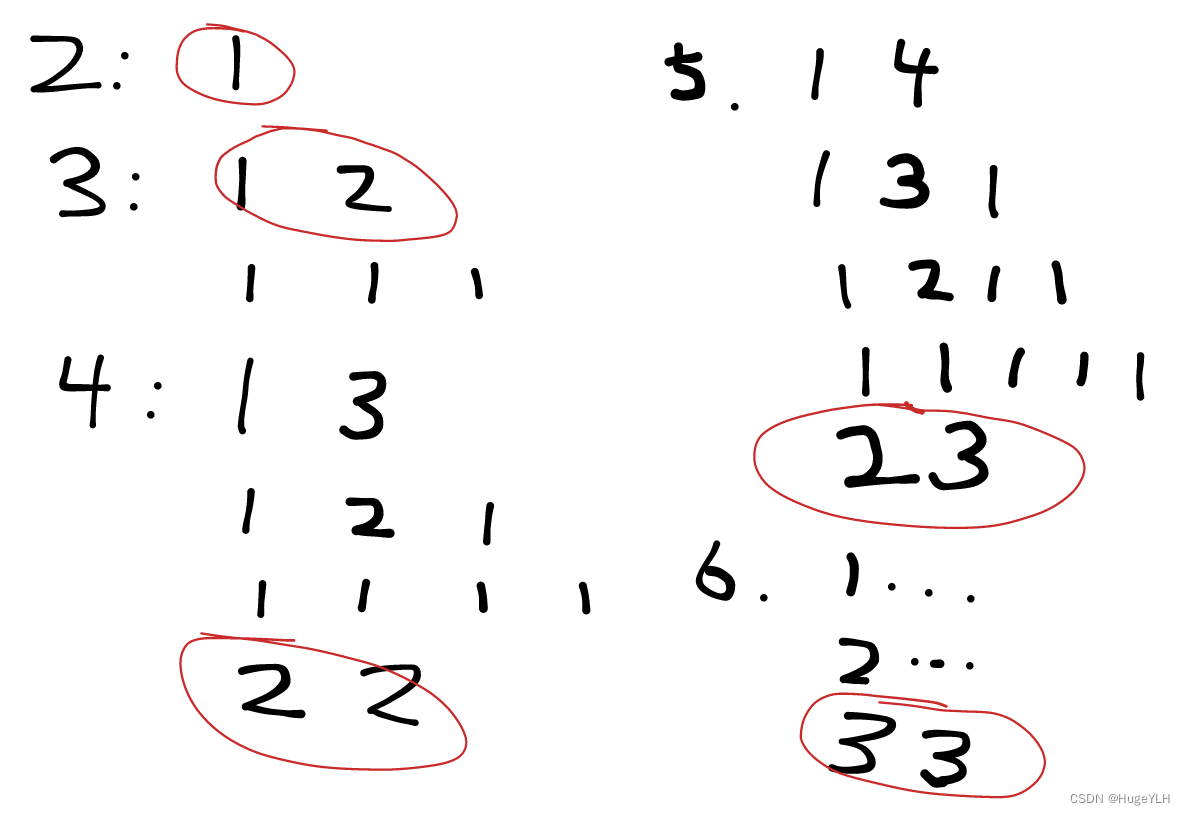
class Solution {
public:
int integerBreak(int n) {
vector<int> dp(n+1);
dp[2]=1;
// i 相等于我们公式的 n
for (int i=3;i<=n;i++)
{
// j 相等于我们公式的 x,另一半则是(i - j)
for (int j=1;j<=i/2;j++)
{
dp[i]=max(dp[i],max(j*(i-j),j*dp[i-j]));
}
}
//dp里存储的就是最大值
return dp[n];
}
};
时间复杂度:O(n^2)空间复杂度:O(n)
对于动态规划的优化,我们不再讨论。
不同的二叉搜索树
力扣传送门:
https://leetcode.cn/problems/unique-binary-search-trees/
这道题表面上没有什么特别的思路,我们可以从画图来找找动态规划的规律
节点为1的情况:只有一个二叉搜索树

节点为2的情况:可以有两种二叉搜索树。节点1为根节点,节点2为根节点
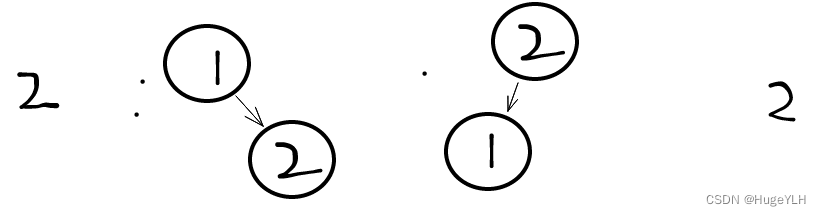
节点为3的情况:可以有五种二叉搜索树。节点1,节点2,节点3都可以为根节点
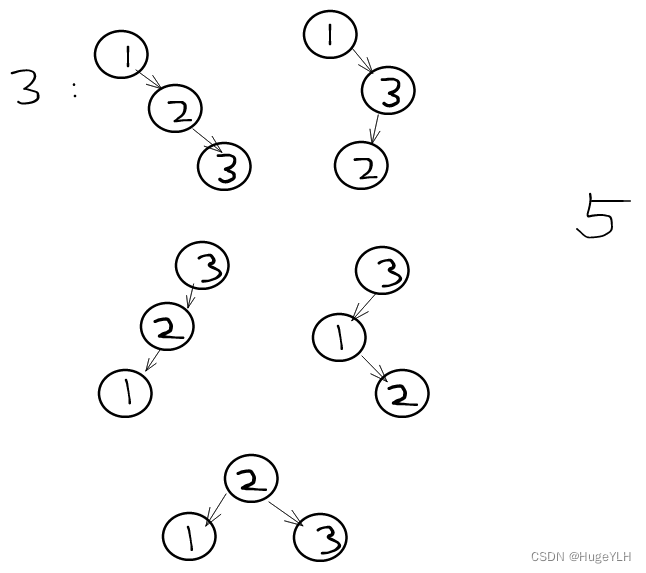
我们来观察n=3的情况:
节点1为根节点,与n=2的节点1为根节点的结构一致! 都是左子树为空,右子树不为空。
节点3为根节点,与n=2的节点2为根节点的结构一致! 都是左子树不为空,右子树不为空。
节点为2为根节点,与n=1的节点1为根节点的结构一致 都是左右子树为空,或者说同时具有左右子树,因为每一个节点又都是一颗新的树。
发现到这里,其实我们就找到了重叠子问题了,其实也就是发现可以通过dp[1] 和 dp[2] 来推导出来dp[3]的某种方式。
我们不妨大胆假设:
n=3时 生成的二叉搜索树的数量 = 节点1为根节点生成的二叉搜索树的数量 + 节点2为根节点生成的二叉搜索树的数量 + 节点3为根节点生成的二叉搜索树的数量
节点1为根节点生成的二叉搜索树的数量 = 左子树有0个元素的子树的数量 * 右子树有2个元素的子树的数量。
节点2为根节点生成的二叉搜索树的数量 = 左子树有1个元素的子树的数量 * 右子树有1个元素的子树的数量。
节点3为根节点生成的二叉搜索树的数量 = 左子树有2个元素的子树的数量 * 右子树有0个元素的子树的数量。
这是n=3的准确的情况,我们把这个数字变到 n试一下:
我们也许会发现规律:当 n=n时:
生成的二叉搜索树的数量 = 节点1为根节点生成的二叉搜索树的数量 + 节点2为根节点生成的二叉搜索树的数量 + 节点3为根节点生成的二叉搜索树的数量 + 节点4… +节点5 … + 节点n为根节点生成的二叉搜索树的数量
节点1为根节点生成的二叉搜索树的数量 = 左子树有0个元素的子树的数量 * 右子树有 n-1 个元素的子树的数量。
节点2为根节点生成的二叉搜索树的数量 = 左子树有1个元素的子树的数量 * 右子树有 n-2 个元素的子树的数量。
节点3为根节点生成的二叉搜索树的数量 = 左子树有2个元素的子树的数量 * 右子树有 n-3 个元素的子树的数量。
节点4为根节点生成的二叉搜索树的数量 = 左子树有3个元素的子树的数量 * 右子树有 n-4 个元素的子树的数量。
节点5为根节点生成的二叉搜索树的数量 = 左子树有4个元素的子树的数量 * 右子树有 n-5 个元素的子树的数量。
…
…
节点n为根节点生成的二叉搜索树的数量 = 左子树有 n-1 个元素的子树的数量 * 右子树有 0 个元素的子树的数量。
动态规划递推公式:dp[i] = dp[j-1] * dp[i-j]
由此,我们正式进入动态规划的总结阶段:
-
确定dp数组以及下标所表示的含义
dp[i]表示n == i时,生成的二叉搜索树的数量。 -
确定递推公式
dp[i]=dp[i-1] * dp[i-j] -
dp数组的初始化
我们初始化 dp[0] =1 ,因为我们首先要求得dp[1]=1 ;因此dp[1] = dp[0] * dp[0]它必须是1,因此dp[0]必须初始化为1. -
dp数组如何遍历
依次填充dp每一个数字为根节点的生成的二叉搜索树的个数,在其中再次求解子问题。 -
举例推导dp公式
代码示例:
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n+1);
//dp初始化为1
dp[0]=1;
//依次填充每一个dp[i]
for (int i=1;i<=n;i++)
{
//每一个dp[i]都是由 dp[j-1] * dp[i-j] 各自相加得到
for (int j=1;j<=i;j++)
{
dp[i]+=dp[j-1]*dp[i-j];
}
}
//第n个dp
return dp[n];
}
};
时间复杂度:O(n^2) 空间复杂度:O(n)
![[附源码]JAVA毕业设计酒店订房系统(系统+LW)](https://img-blog.csdnimg.cn/bfec98a533cc436d9431542d36227148.png)