每周一期,纵览音视频技术领域的干货。
新闻投稿:contribute@livevideostack.com。

22字声明、近400名专家签署、AI教父Hinton与OpenAI CEO领头预警:AI可能灭绝人类!
这份声明一经发布,便迅速得到了多伦多大学计算机科学荣誉教授、“AI教父” Geoffrey Hinton,图灵奖得主 Yoshua Bengio,Google Deepmind CEO Demis Hassabis,OpenAI CEO Sam Altman,以及中国科学院自动化研究所类脑认知智能实验室主任、教授曾毅等近 400 位学术界、产业界、高校专家的支持。
Niantic发布首个混合现实AI虚拟助手体验Wol,用户能够和它进行有意义的对话
Wol是一个猫头鹰形象的AI助手,也正是具备了人工智能能力,Wol能够和玩家一起就虚拟场景中的植物、生物等其他内容进行有意义的对话。在某种意义上,这种体验也可以被看作是一种教育学习的场景。BTW,它是由Pokemon GO开发商Niantic推出的。
评估文生图的人类偏好
自动评估文生图内容的人类偏好,对于指导文生图模型的训练和微调有重大意义。
使用生成式AI改进极端多标签分类
极端多标签分类是指在一个问题中有大量的标签需要预测(例如新闻推荐和商品推荐)的场景。作者提出了一种生成式多标签分类模型(简称GMCL),该模型使用变分自编码器和贝叶斯逻辑回归相结合的方式进行标签预测。结果表明,在性能方面GMCL优于传统的机器学习算法,并且具有更好的泛化能力。
https://www.amazon.science/blog/using-generative-ai-to-improve-extreme-multilabel-classification
Nvidia定制化语音AI提高电信行业客户体验
文章介绍了Nvidia的定制化语音AI解决方案的特点和优势,包括高精度语音识别、多语言支持、高可靠性、快速部署等等。
https://developer.nvidia.com/blog/enhancing-customer-experience-in-telecom-with-nvidia-customized-speech-ai/

人人能打造类ChatGPT“对话搜索引擎”,Vectara获得2亿元融资
Vectara提供了类ChatGPT对话式服务,用户可以将PDF、Word、PPT、RTF等文件数据上传至Vectara平台中,构建数据搜索引擎。目前,Vectara已经全面开放,注册即可使用。
开源地址:https://github.com/vectara/vectara-answer
你可以用 Twilio 和 Langchain Prompt Templates 生成一个篮球短信聊天机器人
这个机器人可以回答用户关于篮球比赛的问题,并提供有关球员、比分和比赛时间等方面的信息。同时,你也可以跟它互动。
https://www.twilio.com/blog/basketball-sms-chatbot-with-langchain-prompt-templates

英伟达市值破万亿美元,GPU龙头的称霸之路
对于英伟达乃至整个芯片产业来说,5月30日都是一个值得被铭记的日子。因为乘着这波ChatGPT带来的芯片热潮,英伟达市值首度突破一万亿美元。
未来十年的芯片路线图

打造音视频极致消费体验
LiveVideoStackCon 2022北京站邀请到快手播放技术中心负责人苍鹏为我们分享快手如何打造极致的音视频消费体验。
哔哩哔哩视频云画质与窄带高清AI落地实践
LiveVideoStackCon 2022 北京站邀请了Bilibili云端多媒体平台的成超老师,为我们分享Bilibili在急速发展过程中基于视频业务上总结的一些先进的经验和想法 。
直播互动开放技术探索之路
本文主要介绍Bilibili直播技术团队在互动开放生态演进道路上的经验与思考。
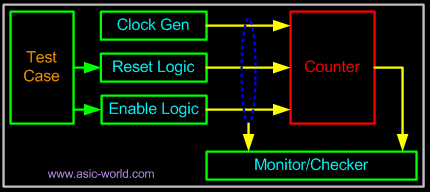
音视频问题汇总--SDP和编码参数

在声学仿真中如何简化边界条件设置
在开发新产品或新功能时,首先需要了解其功能特性。当借助数值仿真来预测性能时,必须非常详细地构建关键组件、设置测试和边界条件,才能保证预测的可靠性和准确性。然而,大多数工程师更倾向于将精力集中在关键组件,而不是“无关”的边界条件。COMSOL Multiphysics 声学模块中内置的阻抗边界条件可以帮助工程师实现这一点。
使用 Laravel Tall Stack 和 Twilio 可编程语音构建一个简单的呼叫中心
本文介绍了如何使用Twilio可编程语音API和Laravel TALL堆栈构建一个简单的呼叫中心。文章中详细介绍了如何使用Tailwind CSS和Alpine.js创建呼叫中心的前端部分。使用Livewire,可以在不刷新页面的情况下更新UI,并实现动态呼叫控制和状态显示等功能。
https://www.twilio.com/blog/build-simple-call-center-laravel-tall-stack-twilio-programmable-voice
扩散视频自编码器:通过解纠缠视频编码实现具有时序一致的人脸视频编辑
本文提出了一种基于扩散自编码器的新型人脸视频编辑框架,该框架可以成功地提取分解的特征:来自给定视频的身份(identity)和运动(motion)。这种建模允许通过简单地朝着希望的方向操纵时间不变的特征来编辑视频,同时保留时序上的一致性。

MR 眼镜的「曲面」设计,难倒了无所不能的苹果
为了探究第一代苹果头显难产的缘由,The information 作者 Wayne Ma 采访了多个前苹果头显团队成员、制造商和产业链人士,分析了当下苹果头显制造的主要难点。

6 月 6 日,WWDC23 码住你时间
本届活动将在北京时间 6 月 6 日凌晨 1 点开始,届时外界关注已久的苹果第一代头显设备即将发布。网友也在放出的活动预告中找到了「隐藏彩蛋」:「VR headset unveiled at WWDC」,翻译为「VR 头显将在 WWDC 揭晓」。

三维重建 3D reconstruction 有哪些实用算法?

Meta Quest 3:苹果头显的最大竞争对手
https://www.bloomberg.com/news/newsletters/2023-05-28/meta-quest-3-real-life-hands-on-how-it-compares-to-apple-mixed-reality-headset-li7h3suy
触觉反馈手环:打开虚拟现实感知的钥匙
科研人员提出了一种新颖的多感官方法,设计一种可穿戴的触觉手环,它在手腕周围提供连续的径向挤压力,加上分布式振动提示,以传达手和指尖预期的感觉、力和瞬变。与仅视觉反馈相比,在手腕处包含连续挤压提示有可能增强用户的触觉体验,带来更完整、沉浸的虚拟现实体验。
https://onlinelibrary.wiley.com/doi/10.1002/aisy.202200303

使用 Microvisor 架构实现面向未来的、无供应商锁定的 IoT 连接
作者认为,许多IoT设备在硬件和软件方面都存在锁定问题,这会带来一系列问题,例如缺乏灵活性、安全风险以及高昂的成本。因此,作者提出了使用微观处理器架构来解决这些问题的方法。
https://www.twilio.com/blog/achieving-no-iot-vendor-lockin-with-a-microvisor-architecture

Tambur:将 streaming codes 应用视频会议场景进行丢包恢复
突发丢包在实际中经常出现,可以通过一类新理论FEC方案称为 “流码”(streaming codes,是 convolutional codes 的一类)来更好地恢复丢包,该方案能够显著减少冗余来实现对突发丢包的恢复。

▲扫描图中二维码或点击“阅读原文” ▲
查看更多LiveVideoStackCon 2023上海站精彩话题