深挖MYSQL大表加索引
起因是这样的,有一张表存在慢sql,查询耗时最多达到12s,定位问题后发现是由于全表扫描导致,需要对字段增加索引,但是表的数据量600多万有些大,网上很多都说对大表增加索引可能会导致锁表,查阅了一些资料,可以说网上说了很多,但是都很笼统,听别人说不如自己去验证,于是开启了验证之旅
首先新建一张表test_page1
CREATE TABLE `test_page1` (
`id` int(11) NULL,
`username` int(252) not NULL,
`password` int(252) NULL,
`create_time` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci not NULL ,
`update_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`create_time`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1000001 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
第二步,像表中干他个600w条数据 这一步网上有很多教程,有通过sql直接在mysql客户端插入数据,还有通过代码插入数据的,最初为了方便,我是想再mysql客户端直接通过存储过程插入数据,但是插入速度十分感人

果断放弃,毕竟600w条,不想等到猴年马月,于是就选择用代码的方式插入,其实就是多费了一些力气而已,上代码,开整

public class Connect {
// 导入驱动jar包或添加Maven依赖(这里使用的是Maven,Maven依赖代码附在文末)
static {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
// 获取数据库连接对象
public static Connection getConn() {
Connection conn = null;
try {
// rewriteBatchedStatements=true,一次插入多条数据,只插入一次
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/xxx?rewriteBatchedStatements=true", "root", "xxx");
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return conn;
}
// 释放资源
public static void closeAll(AutoCloseable... autoCloseables) {
for (AutoCloseable autoCloseable : autoCloseables) {
if (autoCloseable != null) {
try {
autoCloseable.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
public class InsertData {
private static ThreadPoolExecutor getDefaultThreadPool() {
ThreadPoolExecutor result = new ThreadPoolExecutor(0, 1000, 1, TimeUnit.SECONDS, new SynchronousQueue<>());
result.setThreadFactory(new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "deterministic runner thread");
}
});
return result;
}
/* 因为数据库的处理速度是非常惊人的 单次吞吐量很大 执行效率极高
addBatch()把若干sql语句装载到一起,然后一次送到数据库执行,执行需要很短的时间
而preparedStatement.executeUpdate() 是一条一条发往数据库执行的 时间都消耗在数据库连接的传输上面*/
public static void main(String[] args) {
for (int j = 0; j < 100; j++) {
long start = System.currentTimeMillis(); // 获取系统当前时间,方法开始执行前记录
Connection conn = Connect.getConn(); // 调用刚刚写好的用于获取连接数据库对象的静态工具类
String sql = "insert into test_page1 values(null,?,?,?,NOW())"; // 要执行的sql语句
PreparedStatement ps = null;
getDefaultThreadPool().execute(() -> {
try {
PreparedStatement finalPs = conn.prepareStatement(sql);
// 不断产生sql
for (int i = 0; i < 20000; i++) {
finalPs.setString(1, Math.ceil(Math.random() * 1000000) + "");
finalPs.setString(2, Math.ceil(Math.random() * 1000000) + "");
finalPs.setString(3, UUID.randomUUID().toString()); // UUID该类用于随机生成一串不会重复的字符串
finalPs.addBatch(); // 将一组参数添加到此 PreparedStatement 对象的批处理命令中。
}
int[] ints = new int[0];// 将一批命令提交给数据库来执行,如果全部命令执行成功,则返回更新计数组成的数组。
ints = finalPs.executeBatch();
// 如果数组长度不为0,则说明sql语句成功执行,即数据添加成功!
if (ints.length > 0) {
System.out.println("数据添加成功!!");
}
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
Connect.closeAll(conn, ps); // 调用刚刚写好的静态工具类释放资源
}
});
long end = System.currentTimeMillis(); // 再次获取系统时间
System.out.println("所用时长:" + (end - start) / 1000 + "秒"); // 两个时间相减即为方法执行所用时长
}
}
}
代码之所以快,很大的原因是由与代码开启了多线程,异步插入,但在实际执行过程中,也会出现问题,比如把插入的数据量搞太大导致了OOM,这个可以修改本地的JVM,另一种就是同时插入太多,数据库连接不够了,导致报错,但这都不是重点,因为我们的重点是大表加索引。 代码执行后20分钟内,插入了600w条数据。
这时候就开始我们的验证表演了。
首先,说一下网上描述的大表加索引会出现的问题
- 如果在执行事务的时候,如果存在目标表的慢sql,这时对目标表增加索引,会导致目标表被锁,进入Waiting for table metadata lock状态,进入Waiting for table metadata lock状态后不能读也不能写
- 加索引属于DDL操作,DDL操作执行的时候,会对表加锁
然后开始我的尝试 先对表加个索引,用时15.19s
alter table test_page1 add index create_time_index(create_time)
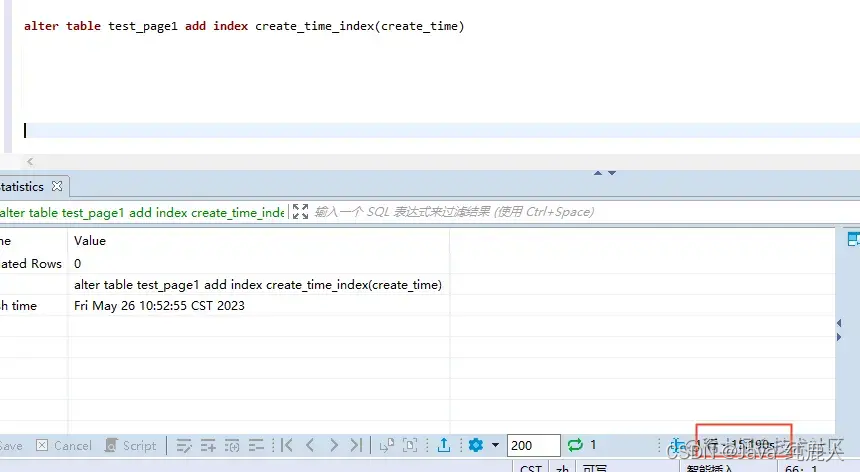
然后我们开启事务,并对该表执行个慢查询,并对表新建一个索引
BEGIN;
select * from test_page1 where username = 852;
alter table test_page1 add index create_time_index(create_time)
这个慢查询有8s,足够出现问题了,很有信心

然而,并没有出现期望的结果,凉凉,难道网上说的都是假的,本身不存在这种情况,苦思之下,似乎找到问题 我是通过dbveaer来执行的sql,同事执行两个sql是在两个tab页上执行,会不会是虽然在dbveaer的两个tab页同时执行,但是dbveaer还是一个一个排队执行的sql呢?我想大概率是这样
我又通过dbeaver新建一个数据库连接,让开启事务,并对该表执行个慢查询和对表增加索引在两个连接执行,这时执行show processlist命令,终于复现了
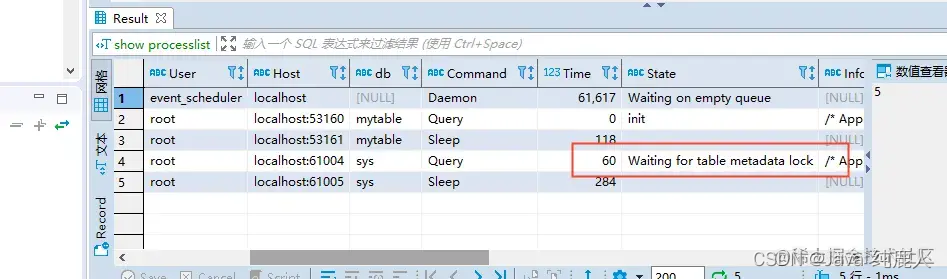
加索引命令的进程进入了Waiting for table metadata lock状态 网上说Waiting for table metadata lock状态后不能读也不能写,是不是这样呢?,来执行下查询,畅通无阻,所以说网上是错误的,是可以读的,那能不能写呢,我们执行下sql
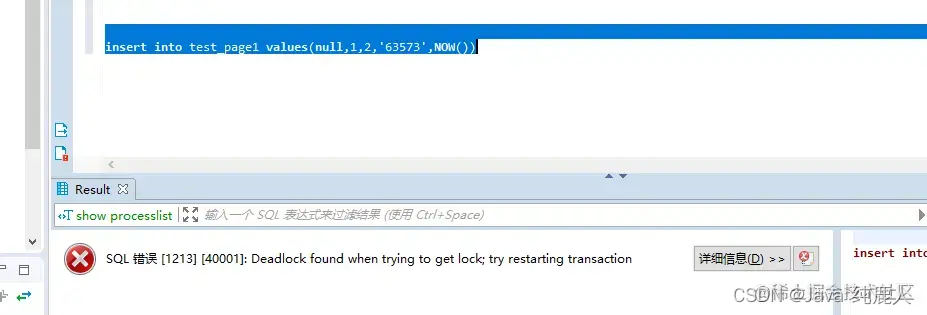
insert into test_page1(id,username,password,create_time,update_time) values(null,1,2,'6144423733',NOW());
报错了,死锁了Deadlock found when trying to get lock; try restarting transaction,这就验证了无法进行写操作
那Waiting for table metadata lock状态会持续到什么时候呢,在验证过程中,发现了两种方式 第一种,事务提交后,锁状态取消 第二种,这种比较神奇,就是刚刚操作过的,对表进行插入操作,这个时候会报错,但是报错后,mysql会自动杀掉事务进程并解锁(这真的很神奇),但是事实就是这样,很糟心。
还有另外一个点要验证就是加索引属于DDL操作,DDL操作执行的时候,会对表加锁,之前我理解错了,以为加锁是表锁,会锁表的数据,但是执行ddl操作时是不会组织数据的写入的,但是另一个连接去执行DDL操作会进入等待状态,这就是多,DDL操作的确会加锁,但是他锁的不是数据而是表结构。
经过一番蛮长的论证,终于验证了什么情况下加索引会锁表,为什么有时候加索引时间会很长,加字段时间会很长,所以,大家加索引最好选择选择在一个业务低峰期加,另外,要注意优化系统,减少系统中慢sql的出现,这样会降低锁表的可能性。
另外如果表被锁住,处于Waiting for table metadata lock状态,这时候我们也可以通过杀掉线程id的方式来解锁,执行show processlist命令,找到线程id,执行kill +id,也能完成解锁。
后记
通过自己实际验证,发现网上说的大部分是正确的,但是没有那么细致,比如解锁的条件是什么,怎么解锁,锁表是锁表结果还是锁数据,实际验证之后得到了很多收获,所以技术还是要深挖