文章目录
- GeoHash可以解决什么问题?
- 基于网格划分的最近邻查询
- GeoHash
- 划分规则
- GeoHash的使用方式
- Redis GEOADD 命令
- 语法
- 示例
- Redis GEORADIUS 命令
- 语法
- 半径单位:
- 可选性参数:
- 示例
- Redis GEORADIUSBYMEMBER 命令
- 语法
- 示例
- Redis GEODIST 命令
- 语法
- 示例
GeoHash可以解决什么问题?
现在很多APP上都有依赖基于附近搜索的需求,也就是根据一组经纬度,检索其相邻范围内的经纬度,而GeoHash就是一种可以用来解决检索相邻区域的地理空间算法。
我们不妨先从最原始的需求开始分析,也就是根据某个经纬度获取其附近一定范围内的其他目标信息,我们可以先尝试通过使用像MySQL这样的关系型数据库来实现,比如表中记录了longitude表示经度,latitude 表示纬度。
现在有个用户当前处于的经纬度分别为X、Y,请查询其M范围内的相关信息。
根据经纬度距离计算公式可以写出如下SQL,即可按记录由近到远得到想要的目标信息。
SELECT *, ACOS(
COS(RADIANS(Y)) *
COS(RADIANS(latitude )) *
COS(RADIANS(longitude) - RADIANS(X)) +
SIN(RADIANS(Y)) *
SIN(RADIANS(latitude ))
) * 6378 as distance
FROM test ORDER BY distance;
如果请求量以及数据量都不是很大的情况下,使用这种方式完全就足够了,既简单又方便。
基于网格划分的最近邻查询
很明显,当数据量变多,查询量变大以后,如果还继续使用SQL查询的方式,是很难扛得住非常高频的请求的,因此就需要转变查询的方式,最容易想到的方式就是能不能把数据都存储在内存中,这样查询起来就快多了,不过内存容量相比磁盘小多了,所以我们还要想一种能够节约空间的存储方式,那么基于网格划分的最近邻查询算法就是目前比较常用的解法。
该算法将整个数据空间划分成大小相等、互不重叠的网格,目标信息就存放在这些网格中,只要网格大小合适,就能够获得足够精度的信息。
举个简单的例子
假设按照1万条数据一个方格来划分,一共划分出4*4的网格

当某个区域网格内数据增加时,还可以继续对其分裂,最终就像一颗多叉树一样,且在数据密集区域内网格一定会被划分的很小,而在数据稀疏区域网格则会非常的大,当然,如果网格大小划分不合适,则会导致树的深度太深,每次查找起来性能也不会太理想,不过一旦定位到某个网格之后,再查找邻近的信息就非常简单了,同一个网格内的一定是邻近的,当前网格的上下左右网格就是其次邻近的。
GeoHash
GeoHash是一种优化的网格算法,能够高效的对经纬度进行比较,也是Redis是所使用的算法,其原理就是将网格进行编码,然后根据编码进行Hash存储,且其网格的划分是采用二分区间的方式来完成的,目的就是为了将二维的经纬度转化为一维的二进制数字,这样就可以方便的对齐进行排序、比较了。
划分规则
经度的区间为[-180,180],纬度的区间为[-90,90],当经、纬度值落在左区间时,我们就用0表示,当经、纬度值落在右区间时,我们就用1表示。
最直接的4分区就表示为:00011011

举个例子,假设我们要记录的经度值为:109.05122,纬度值为:19.292939
经度值经过6次编码后,最终值为:110011

纬度值经过6次编码后,最终值为:100110

当经纬度编码值都计算出来以后,再进行合并,合并规则为,从第一位开始,奇数位取经度值,偶数位取纬度值,因此合并后最终的结果为:111000011110
好了,现在经过转换之后,111000011110就可以用来存储、比较了,Redis中对于比较可以使用Sorted Set,我们可以用member来记录数据ID,用score来记录转换后的经纬度,也就是111000011110
GeoHash的使用方式
Redis GEOADD 命令
将指定的地理空间位置(纬度、经度、名称)添加到指定的key中
语法
GEOADD key [NX | XX] [CH] longitude latitude member [longitude
latitude member ...]
示例
将指定经、纬度添加到指定的类型的集合中,比如:geoadd user:locations 109.05122 19.292939 1 103.05212 23.292939 2,就表示把id为1的用户且经纬度值:109.05122 19.292939和id为2的用户且经纬度值:103.05212 23.292939存放到user:locations集合中。
Redis GEORADIUS 命令
以给定的经纬度为中心, 找出某一半径内的元素
语法
GEORADIUS key longitude latitude radius <M | KM | FT | MI>
[WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC | DESC]
[STORE key] [STOREDIST key]
半径单位:
M 表示单位为米。
KM 表示单位为千米。
FT 表示单位为英尺。
MI 表示单位为英里。
可选性参数:
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
WITHCOORD: 将位置元素的经度和维度也一并返回。
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
命令默认返回未排序的位置元素。 通过以下两个参数, 用户可以指定被返回位置元素的排序方式:
ASC: 根据中心的位置, 按照从近到远的方式返回位置元素。
DESC: 根据中心的位置, 按照从远到近的方式返回位置元素。
在默认情况下, GEORADIUS 命令会返回所有匹配的位置元素。 虽然用户可以使用 COUNT 选项去获取前 N 个匹配元素, 但是因为命令在内部可能会需要对所有被匹配的元素进行处理, 所以在对一个非常大的区域进行搜索时, 即使只使用 COUNT 选项去获取少量元素, 命令的执行速度也可能会非常慢。 但是从另一方面来说, 使用 COUNT 选项去减少需要返回的元素数量, 对于减少带宽来说仍然是非常有用的。
示例
假设,我们现在需要根据给定经纬度,由近到远显示附近前10条1000KM范围内的信息,那么,可以这样写:georadius user:locations 110.05152 20.293939 1000 km withcoord withdist count 10 asc

Redis GEORADIUSBYMEMBER 命令
找出位于指定范围内的元素,中心点是由给定的位置元素决定
语法
GEORADIUSBYMEMBER key member radius <M | KM | FT | MI> [WITHCOORD]
[WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC | DESC] [STORE key]
[STOREDIST key]
此命令与GEORADIUS完全相同,唯一的区别是 将经度和纬度值作为要查询的区域的中心,它采用排序集表示的地理空间索引中已存在的成员的名称。
示例

Redis GEODIST 命令
返回两个给定位置之间的距离
语法
GEODIST key member1 member2 [M | KM | FT | MI]
示例
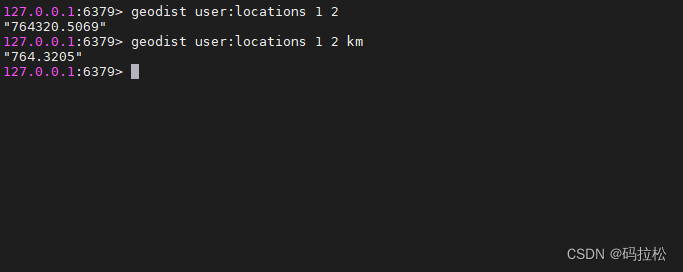
如果用户没有显式地指定单位参数, 那么 GEODIST 默认使用米作为单位。
GEODIST 命令在计算距离时会假设地球为完美的球形, 在极限情况下, 这一假设最大会造成 0.5% 的误差。



![[附源码]Python计算机毕业设计SSM教学团队管理系统(程序+LW)](https://img-blog.csdnimg.cn/1547dbbae0c54bcb8987a247f04fe261.png)



![[附源码]计算机毕业设计网上书城网站Springboot程序](https://img-blog.csdnimg.cn/3a552765766c4a679c0863015ece118d.png)