大数据支持Split的目的是为了能并行处理任务,可以将文件拆分成多个文件块处理。如果不支持Split的话,只能用一个任务处理单个文件。
能否支持Split受到文件格式和压缩算法的双重限制,大部分文件的读取都是可以支持Split,极少数压缩算法支持Split。
Text,Parquet,Orc支持Split,仅BZip2支持Split。
文件格式
读取文件的源码:org.apache.spark.sql.execution.FileSourceScanExec
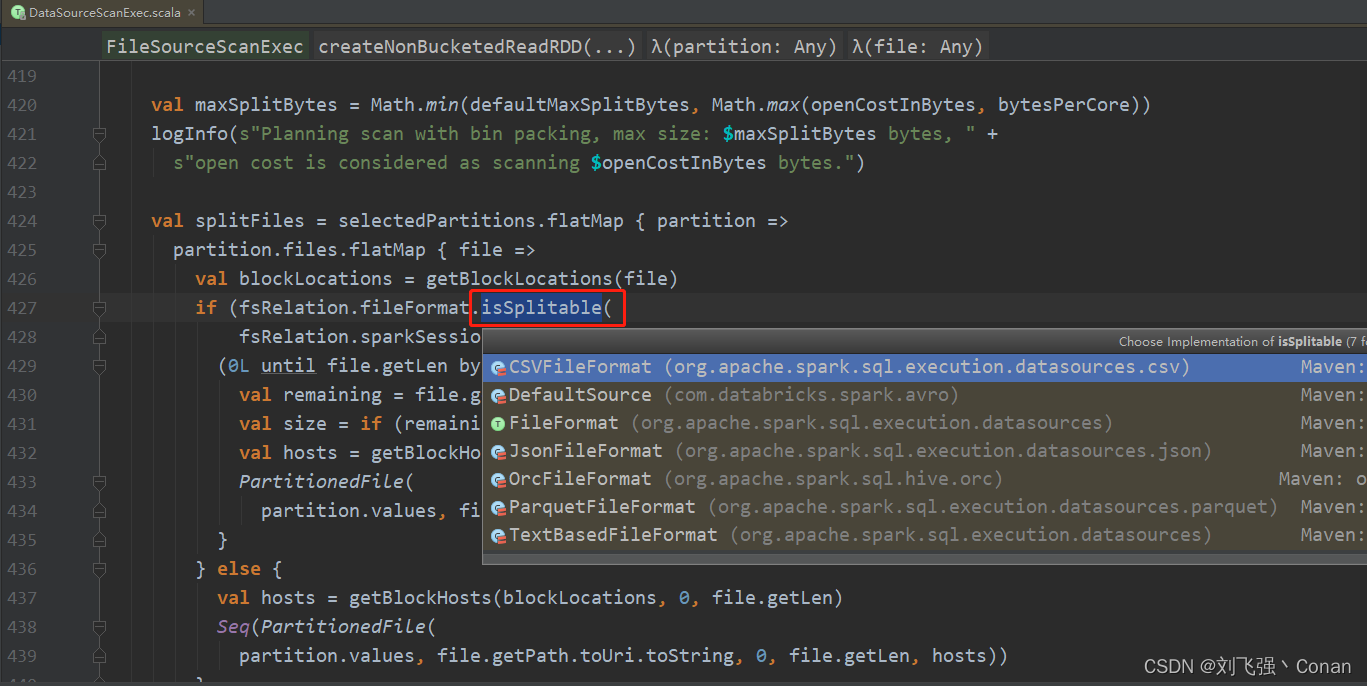
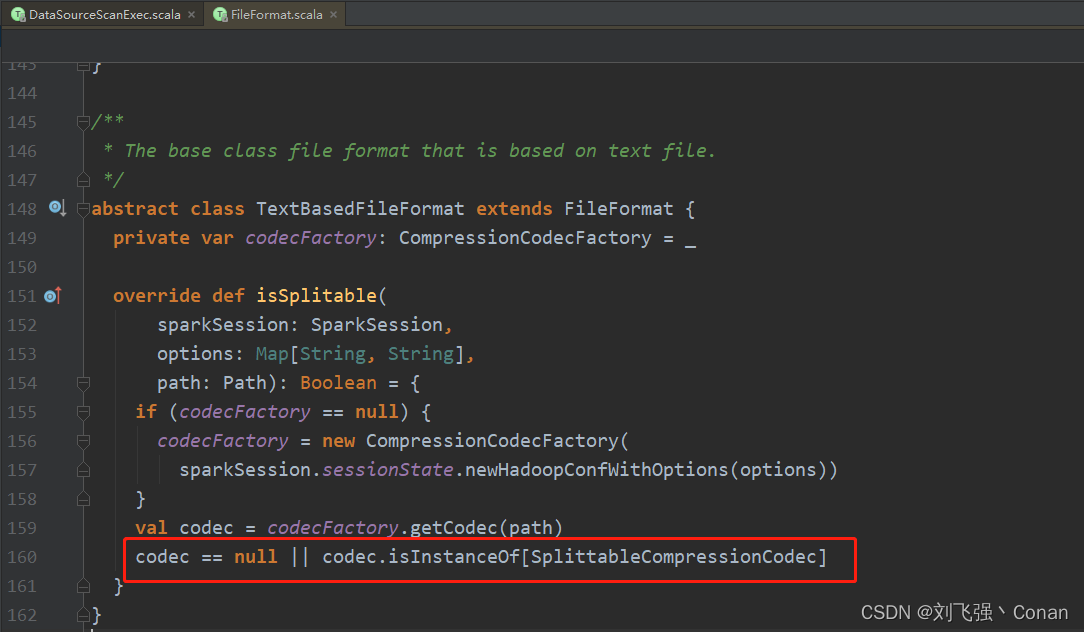
代码里对文件格式判断isSplitable,可以看到有6个类实现了该方法,重点关注下CSV,Orc,Parquet,Text
Orc:默认支持,直接返回true,所以只要是Orc的文件格式都可以Split,不用管是否有压缩。

Parquet:默认支持,直接返回true,所以只要是Parquet的文件格式都可以Split,不用管是否有压缩。
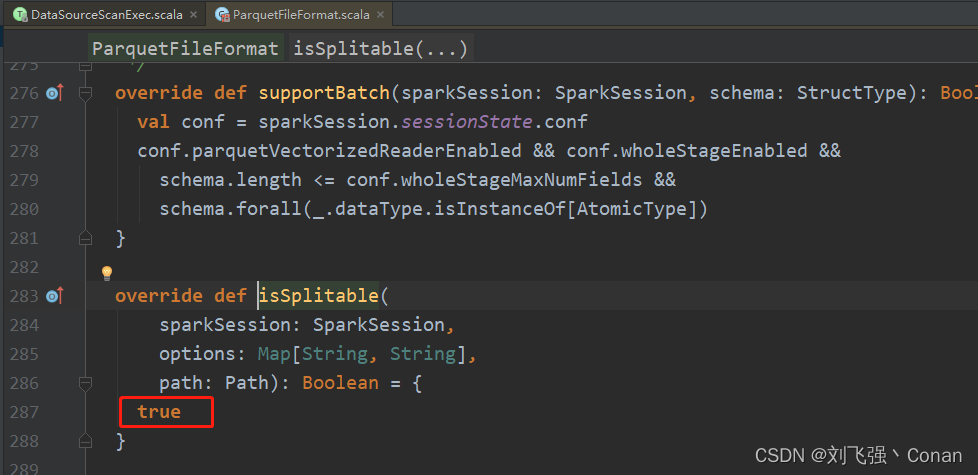
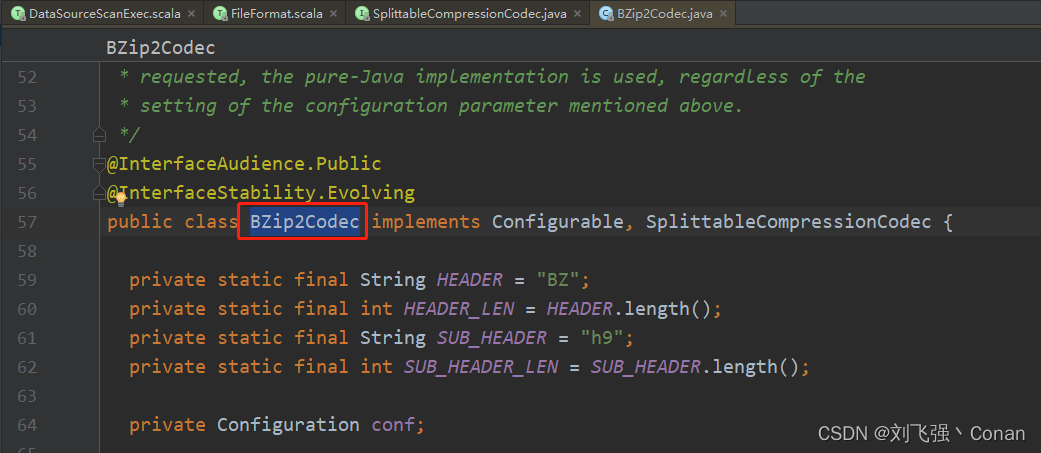
Text:先判断文本文件是否被压缩,如果没有压缩,则支持Split。 如果有压缩,还要判断压缩格式的类是否为org.apache.hadoop.io.compress.SplittableCompressionCodec的实现类。 查看实现类,仅仅只有一个org.apache.hadoop.io.compress.BZip2Codec。
总结:文件文件没有压缩,支持Split。用BZip2压缩也支持Split,其它压缩格式不支持Split
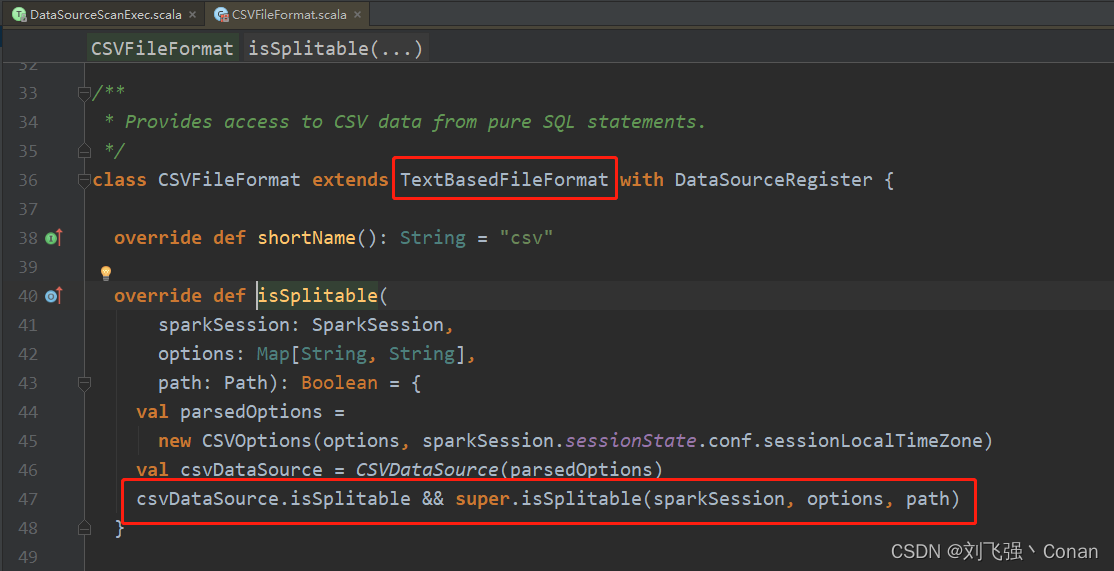
CSV:继承自org.apache.spark.sql.execution.datasources.TextBasedFileFormat,所以必须满足文本文件可分割的条件。除此之外还必须满足CSV文件支持Split,CSV实现了两种读取方式TextInputCSVDataSource和MultiLineCSVDataSource,第一种支持Split,第二种不支持,可以自行查看源码
压缩算法
压缩算法需要实现org.apache.hadoop.io.compress.CompressionCodec接口
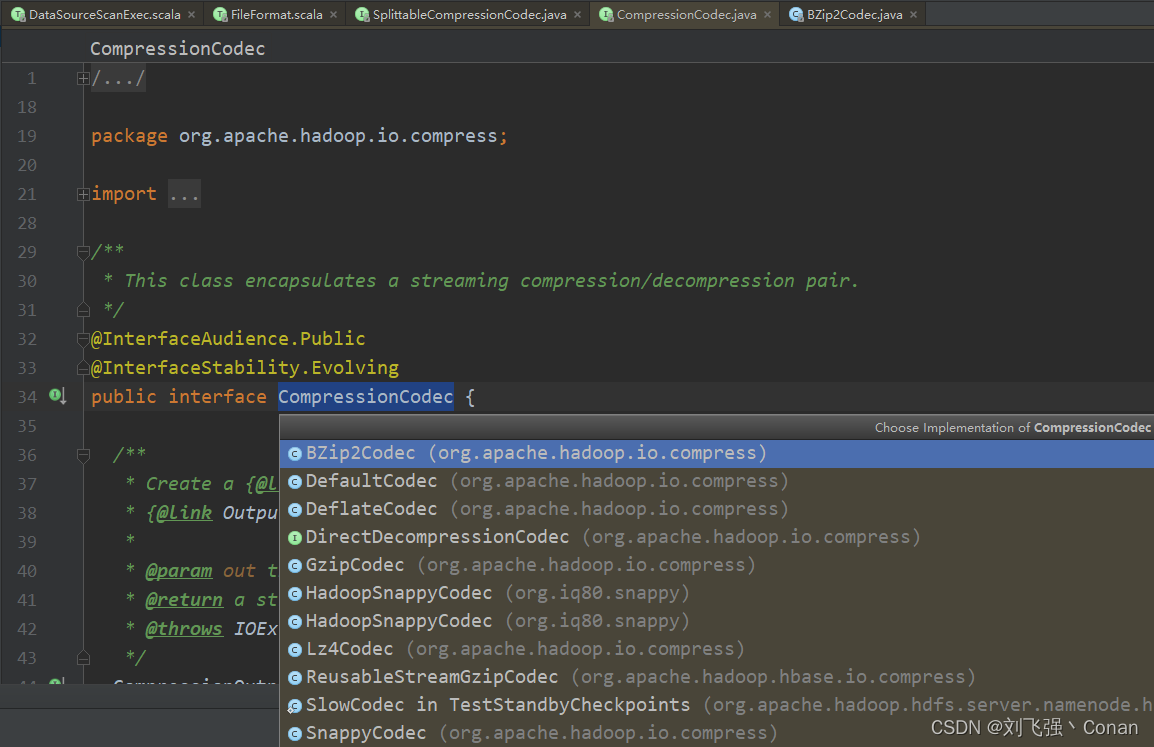
支持Split的压缩算法需要实现org.apache.hadoop.io.compress.SplittableCompressionCodec
实际操作
查看源码org.apache.spark.sql.internal.SQLConf里对ORC压缩的配置(该配置从spark2.3开始才有)
val ORC_COMPRESSION = buildConf("spark.sql.orc.compression.codec")
.doc("Sets the compression codec used when writing ORC files. If either `compression` or " +
"`orc.compress` is specified in the table-specific options/properties, the precedence " +
"would be `compression`, `orc.compress`, `spark.sql.orc.compression.codec`." +
"Acceptable values include: none, uncompressed, snappy, zlib, lzo.")
.version("2.3.0")
.stringConf
.transform(_.toLowerCase(Locale.ROOT))
.checkValues(Set("none", "uncompressed", "snappy", "zlib", "lzo"))
.createWithDefault("snappy")create table tab1 (
f1 string comment '测试'
)
comment '表注释'
partitioned by (dt string comment '分区注释')
stored as orc
tblproperties(
'orc.compress' = 'SNAPPY' -- 这里需要注意下大小写,很多文档是小写,我的报错,受到了Hive的限制,提示没有enum constant,改成大写
)不建议对数据量小的表进行压缩,ORC本身是压缩的自解析文件格式,加上后可能需要报错更多的压缩信息,使文件存储空间更大。