CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors

标题:重建心灵之眼:fMRI-to-Image with Contrastive learning and Diffusion Priors
作者:Paul S. Scotti, Atmadeep Banerjee, Jimmie Goode, Stepan Shabalin, Alex Nguyen, Ethan Cohen, Aidan J. Dempster,
文章链接:https://arxiv.org/abs/2305.18274
项目代码:https://medarc-ai.github.io/mindeye-website/


摘要:
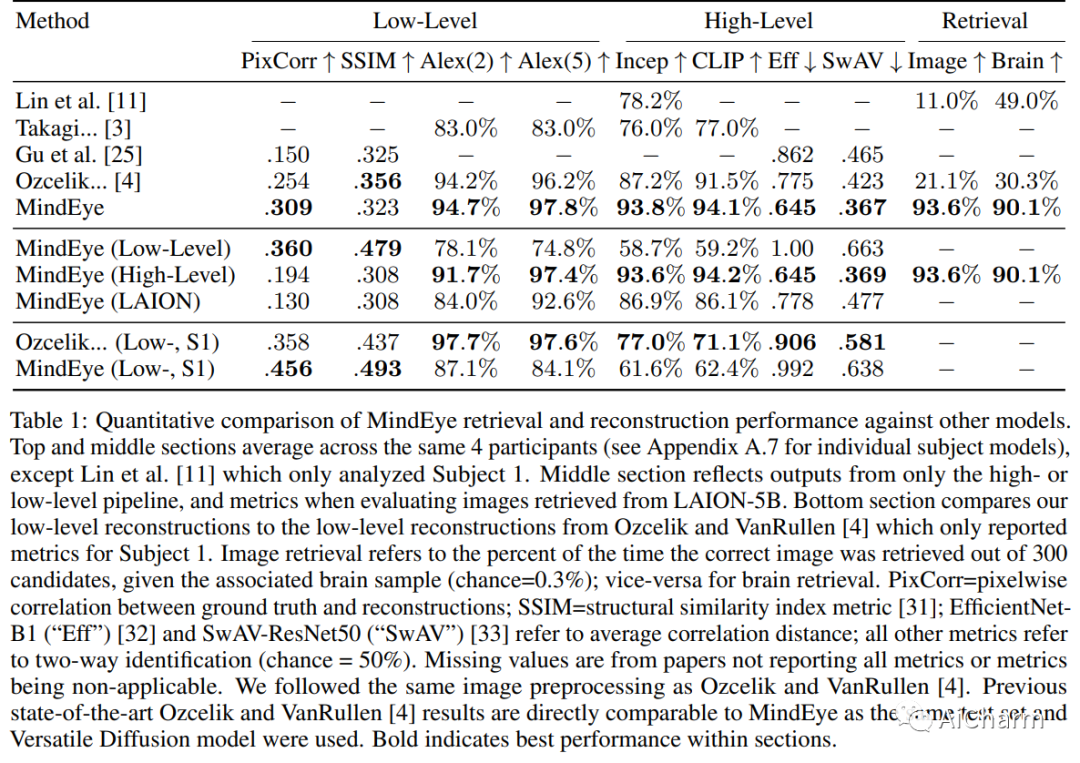
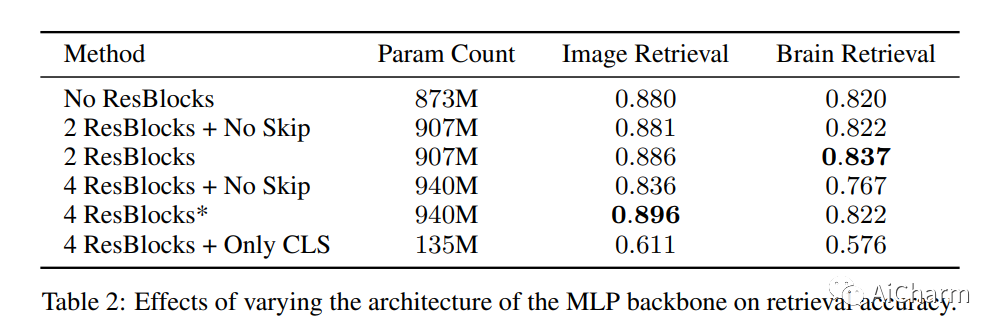
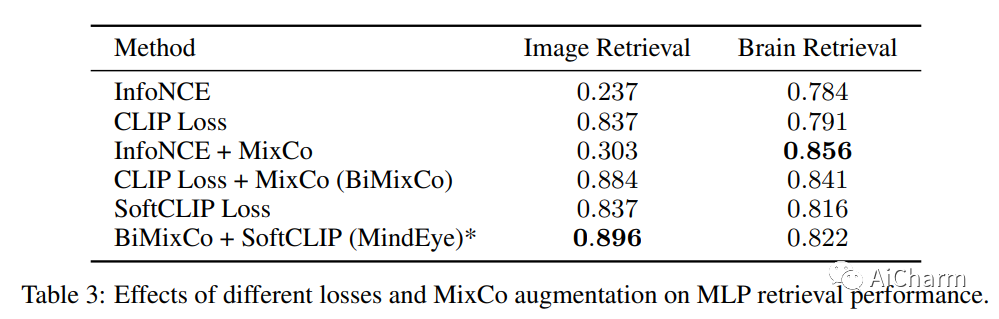
我们介绍了 MindEye,这是一种新颖的 fMRI 到图像的方法,可以从大脑活动中检索和重建观察到的图像。我们的模型包含两个并行子模块,专门用于检索(使用对比学习)和重建(使用扩散先验)。MindEye 可以将 fMRI 大脑活动映射到任何高维多模态潜在空间,如 CLIP 图像空间,从而使用接受来自该潜在空间的嵌入的生成模型实现图像重建。我们将我们的方法与其他现有方法进行全面比较,同时使用定性并排比较和定量评估,并表明 MindEye 在重建和检索任务中实现了最先进的性能。特别是,即使在高度相似的候选人中,MindEye 也可以检索到准确的原始图像,这表明其大脑嵌入保留了细粒度的图像特定信息。这使我们能够准确地从 LAION-5B 等大型数据库中检索图像。我们通过消融证明,MindEye 相对于以前方法的性能改进源于用于检索和重建的专门子模块、改进的训练技术以及具有更多数量级参数的训练模型。此外,我们表明 MindEye 可以通过使用 img2img 以及来自单独自动编码器的输出更好地保留重建中的低级图像特征。所有代码都可以在 GitHub 上找到。
2.RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths

标题:RAPHAEL:通过大量混合扩散路径生成文本到图像
作者:Zeyue Xue, Guanglu Song, Qiushan Guo, Boxiao Liu, Zhuofan Zong, Yu Liu, Ping Luo
文章链接:https://arxiv.org/abs/2305.18295
项目代码:https://raphael-painter.github.io
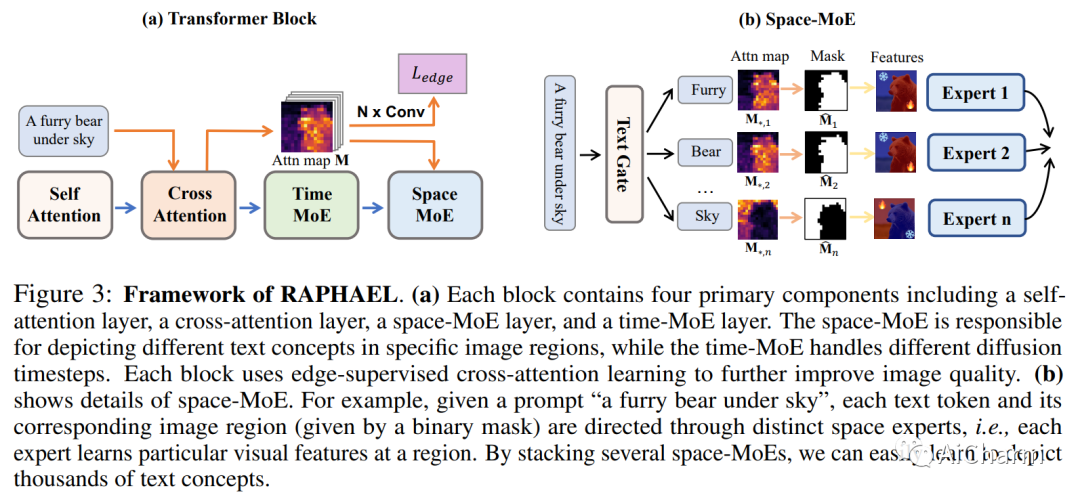
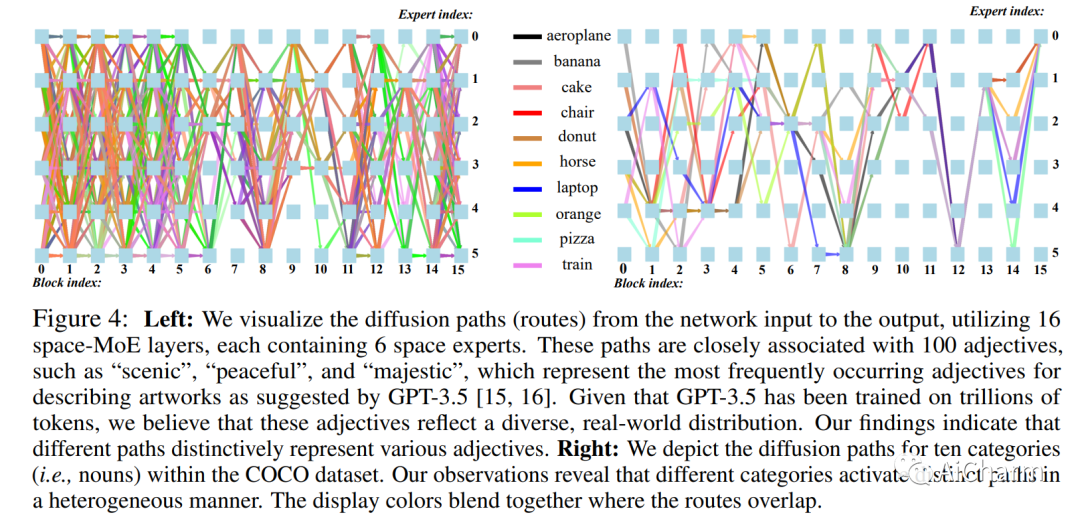
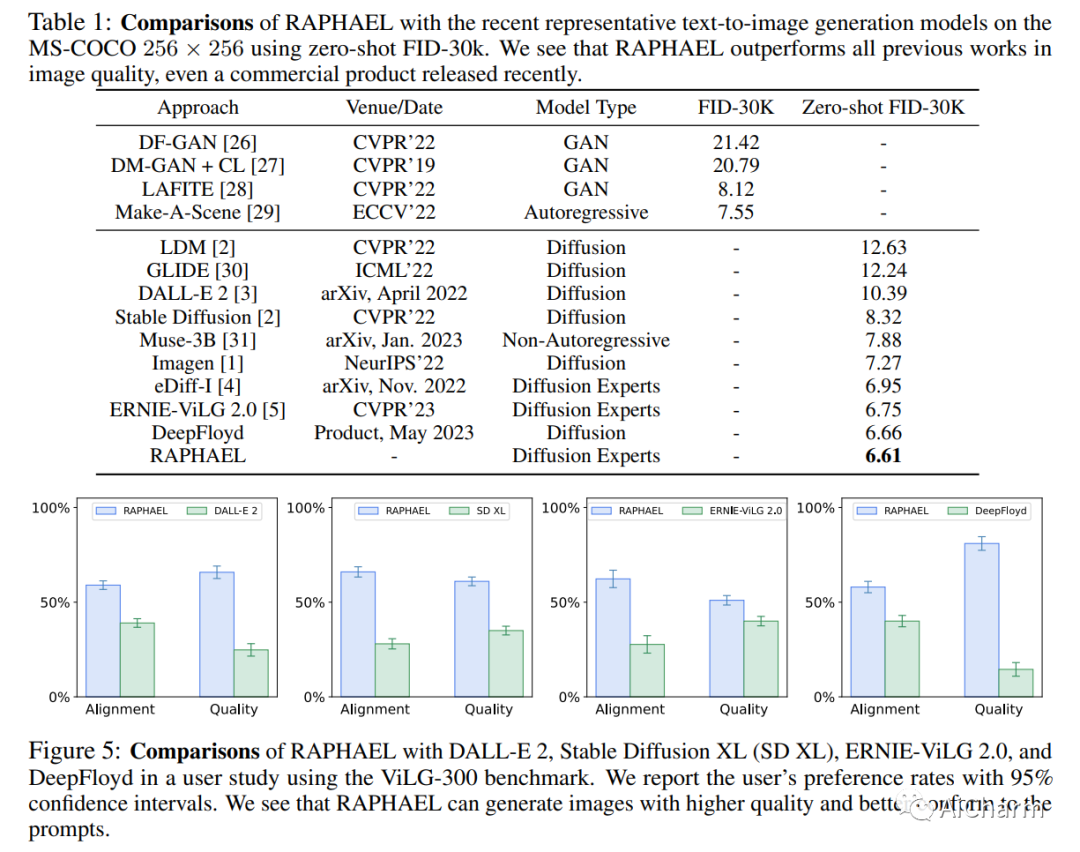
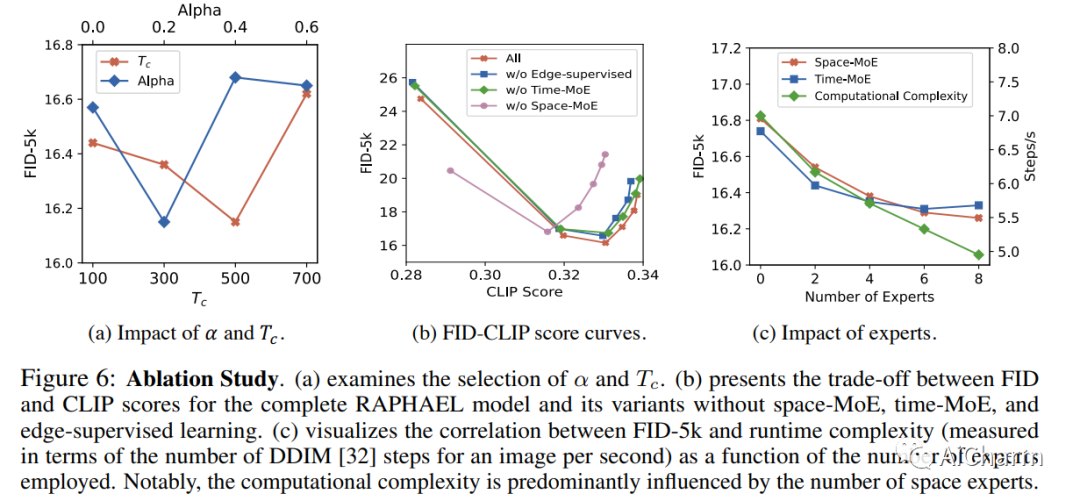
摘要:
文本到图像的生成最近取得了显著成就。我们引入了一种名为 RAPHAEL 的文本条件图像扩散模型,以生成高度艺术化的图像,这些图像准确地描绘了文本提示,包含多个名词、形容词和动词。这是通过堆叠数十个混合专家 (MoE) 层(即空间-MoE 和时间-MoE 层)实现的,从而实现从网络输入到输出的数十亿条扩散路径(路线)。每条路径直观地充当“画家”,用于在扩散时间步将特定的文本概念描绘到指定的图像区域上。综合实验表明,RAPHAEL 在图像质量和美学吸引力方面优于最近的前沿模型,如 Stable Diffusion、ERNIE-ViLG 2.0、DeepFloyd 和 DALL-E 2。首先,RAPHAEL在日漫、现实主义、赛博朋克、水墨插画等多种风格的图像切换方面表现出卓越的表现。其次,一个拥有 30 亿参数的单一模型,在 1,000 个 A100 GPU 上训练了两个月,在 COCO 数据集上获得了 6.61 的最先进的零样本 FID 分数。此外,RAPHAEL 在 ViLG-300 基准测试中的人工评估显着超过了其同行。我们相信 RAPHAEL 有潜力推动学术界和工业界图像生成研究的前沿,为这个快速发展领域的未来突破铺平道路。可以在项目网页上找到更多详细信息:此 https URL。
3.Generating Images with Multimodal Language Models

标题:使用多模态语言模型生成图像
作者:Jing Yu Koh, Daniel Fried, Ruslan Salakhutdinov
文章链接:https://arxiv.org/abs/2305.17216
项目代码:http://jykoh.com/gill
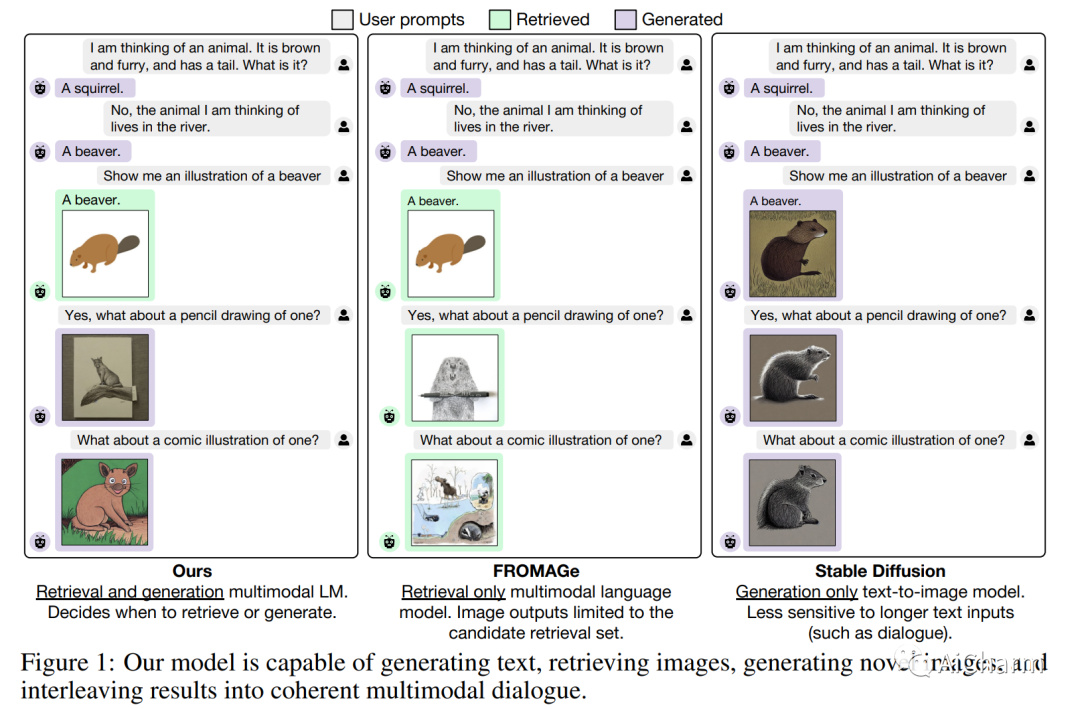
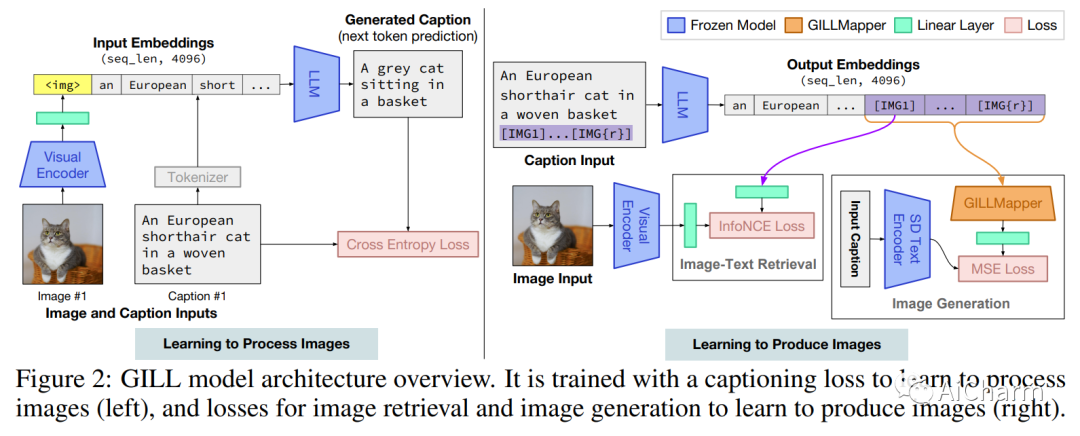
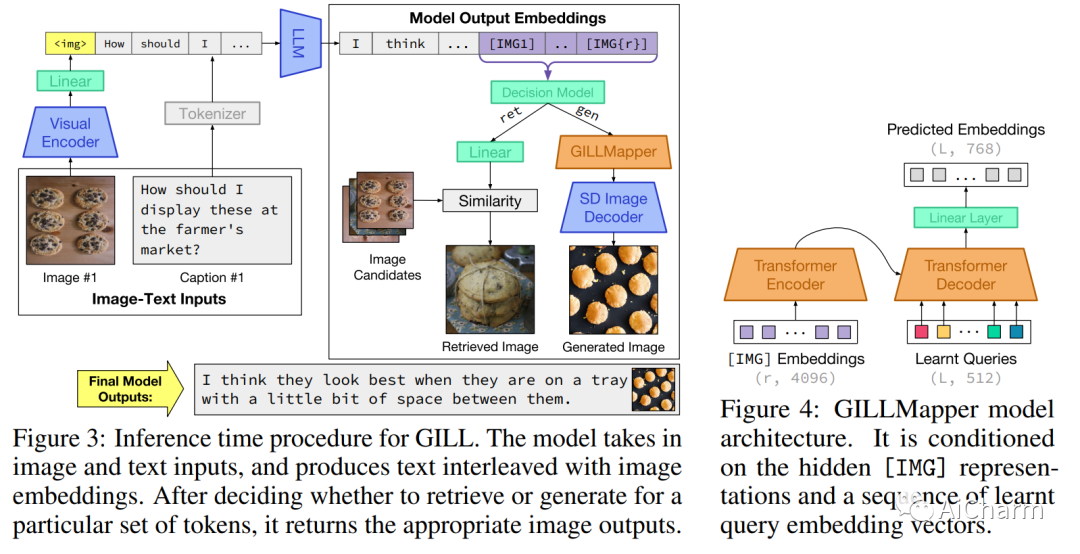

摘要:
我们提出了一种方法,通过嵌入空间之间的映射,将冻结的纯文本大型语言模型 (LLM) 与预训练的图像编码器和解码器模型融合在一起。我们的模型展示了一套广泛的多模式功能:图像检索、新图像生成和多模式对话。我们的方法是第一种能够对任意交错的图像和文本输入进行调节以生成连贯图像(和文本)输出的方法。为了在图像生成方面实现强大的性能,我们提出了一个高效的映射网络,将 LLM 建立在现成的文本到图像生成模型上。该映射网络将文本的隐藏表示转换为视觉模型的嵌入空间,使我们能够利用 LLM 的强文本表示进行视觉输出。我们的方法在使用更长、更复杂的语言的任务上优于基线生成模型。除了新颖的图像生成,我们的模型还能够从预先指定的数据集中检索图像,并在推理时决定是检索还是生成。这是通过学习决策模块完成的,该模块以 LLM 的隐藏表示为条件。与之前的多模态语言模型相比,我们的模型展示了更广泛的功能。它可以处理图像和文本输入,并生成检索到的图像、生成的图像和生成的文本——在多个测量上下文依赖性的文本到图像任务中,它的性能优于基于非 LLM 的生成模型。
更多Ai资讯:公主号AiCharm