【编译和链接三】编译器——语法分析、词法分析、语义分析、编译器后端
- 内容总结
- 一、词法分析(Lexical Analysis)
- 二、语法分析 (Syntactic Analysis, or Parsing)
- 三、语义分析(Semantic Analysis)
- 四、编译器的后端实现技术
内容总结
- 词法分析是把程序分割成一个个 Token 的过程。
- 语法分析是把程序的结构识别出来,并形成一棵便于由计算机处理的抽象语法树。
- 语义分析是消除语义模糊,给这棵树生成一些属性信息.
- 编译器后端是把这棵树生成汇编代码。
一、词法分析(Lexical Analysis)
通常,编译器的第一项工作叫做词法分析。就像阅读文章一样,文章是由一个个的中文单词组成的。程序处理也一样,只不过这里不叫单词,而是叫做“词法记号”,英文叫 Token。

举个例子,看看下面这段代码,如果我们要读懂它,首先要怎么做呢?

-
我们会识别出 if、else、int 这样的关键字,main、printf、age 这样的标识符,+、-、= 这样的操作符号,还有花括号、圆括号、分号这样的符号,以及数字字面量、字符串字面量等。这些都是 Token。
-
那么,如何写一个程序来识别 Token 呢?可以看到,英文内容中通常用空格和标点把单词分开,方便读者阅读和理解。但在计算机程序中,仅仅用空格和标点分割是不行的。比如“age >= 45”应该分成“age”“>=”和“45”这三个 Token,但在代码里它们可以是连在一起的,中间不用非得有空格。
-
这和汉语有点儿像,汉语里每个词之间也是没有空格的。但我们会下意识地把句子里的词语正确地拆解出来。比如把“我学习编程”这个句子拆解成“我”“学习”“编程”,这个过程叫做“分词”
-
其实,我们可以通过制定一些规则来区分每个不同的 Token,我举了几个例子,你可以看一下。
- 识别 age 这样的标识符。它以字母开头,后面可以是字母或数字,直到遇到第一个既不是字母又不是数字的字符时结束。
- 识别 >= 这样的操作符。 当扫描到一个 > 字符的时候,就要注意,它可能是一个 GT(Greater Than,大于)操作符。但由于 GE(Greater Equal,大于等于)也是以 > 开头的,所以再往下再看一位,如果是 =,那么这个 Token 就是 GE,否则就是 GT。
- 识别 45 这样的数字字面量。当扫描到一个数字字符的时候,就开始把它看做数字,直到遇到非数字的字符。
-
有限自动机(Finite-state Automaton,FSA,or Finite Automaton)”。
有限自动机是有限个状态的自动机器。我们可以拿抽水马桶举例,它分为两个状态:“注水”和“水满”。摁下冲马桶的按钮,它转到“注水”的状态,而浮球上升到一定高度,就会把注水阀门关闭,它转到“水满”状态。
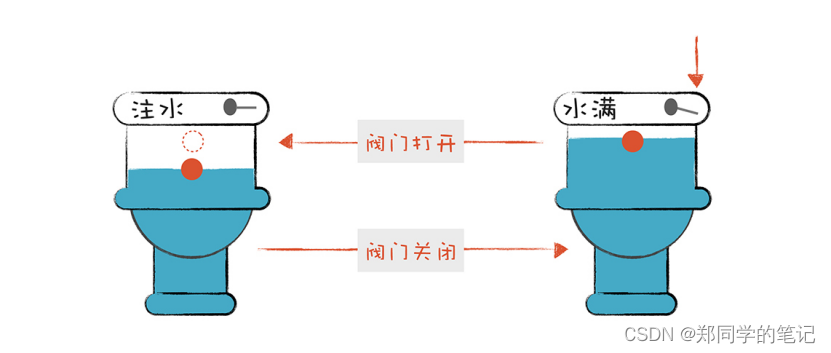
-
词法分析器也是一样,它分析整个程序的字符串,当遇到不同的字符时,会驱使它迁移到不同的状态。例如,词法分析程序在扫描 age 的时候,处于“标识符”状态,等它遇到一个 > 符号,就切换到“比较操作符”的状态。词法分析过程,就是这样一个个状态迁移的过程。
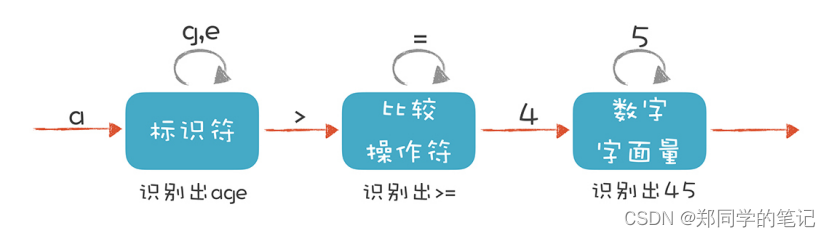
有一个叫做lex的程序可以实现词法扫描,它会按照用户之前描述好的词法规则将输入的字符串分割成一个个记号。因为这样一个程序的存在,编译器的开发者就无须为每个编译器开发一个独立的词法扫描器,而是根据需要改变词法规则就可以了。

另外对于一些有预处理的语言,比如C语言,它的宏替换和文件包含等工作一般不归入编译器的范围而交给一个独立的预处理器。
二、语法分析 (Syntactic Analysis, or Parsing)
- 接下来语法分析器(Grammar Parser)将对由扫描器产生的记号进行语法分析,从而产生语法树(Syntax Tree)。
整个分析过程采用了上下文无关语法(Context-free Grammar)的分析手段,如果你对上下文无关语
法及下推自动机很熟悉,那么应该很好理解。否则,可以参考一些计算理论的资料,一般都会有很详细的介绍。此处不再赘述。
- 简单地讲,由语法分析器生成的语法树就是以表达式(Expression)为节点的树。我们知道,C语言的一个语句是一个表达式,而复杂的语句是很多表达式的组合。上面例子中的语句就是一个由赋值表达式、加法表达式、乘法表达式、数组表达式、括号表达式组成的复杂语句。
array[index] = (index + 4) * (2 + 6)
上面代码,它在经过语法分析器以后形成如图2-3所示的语法树
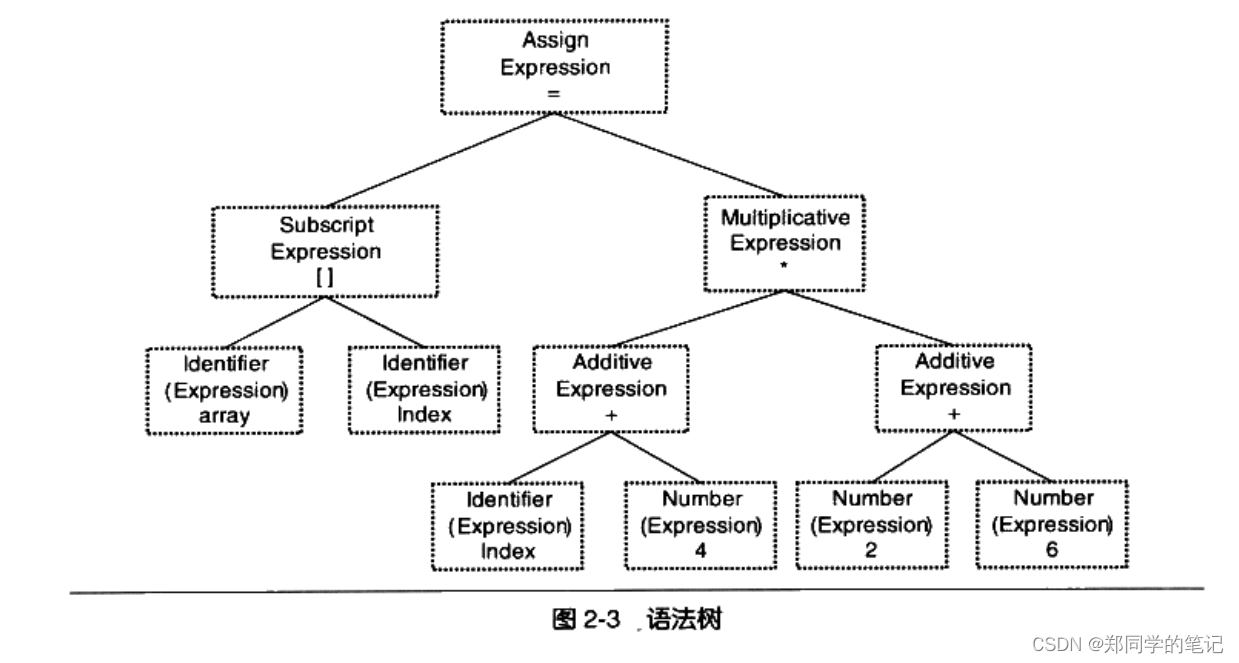
从图2-3中我们可以看到,整个语句被看作是一个赋值表达式;赋值表达式的左边是一个数组表达式,它的右边是一个乘法表达式;数组表达式又由两个符号表达式组成,等等。
- 程序也有定义良好的语法结构,它的语法分析过程,就是构造这么一棵树。一个程序就是一棵树,这棵树叫做抽象语法树(Abstract Syntax Tree,AST)。树的每个节点(子树)是一个语法单元,这个单元的构成规则就叫“语法”。每个节点还可以有下级节点。层层嵌套的树状结构,是我们对计算机程序的直观理解。计算机语言总是一个结构套着另一个结构,大的程序套着子程序,子程序又可以包含子程序。
正如前面词法分析有lex一样,语法分析也有一个现成的工具叫做yacc(Yet Another Compiler Compiler)。它也像lex一样,可以根据用户给定的语法规则对输入的记号序列进行解析,从而构建出一棵语法树。对于不同的编程语言,编译器的开发者只须改变语法规则,而无须为每个编译器编写一个语法分析器,所以它又被称为“编译器编译器(Compiler Compiler)”。

三、语义分析(Semantic Analysis)
- 接下来进行的是语义分析,由语义分析器(Semantic Analyzer)来完成。语法分析仅仅是完成了对表达式的语法层面的分析,但是它并不了解这个语句是否真正有意义。
比如C语言里面两个指针做乘法运算是没有意义的,但是这个语句在语法上是合法的;比如同样一个指针和一个浮点数做乘法运算是否合法等。
- 编译器所能分析的语义是静态语义(Static Semantic),所谓静态语义是指在编译期可以确定的语义,与之对应的动态语义(Dynamic Semantic)就是只有在运行期才能确定的语义。
静态语义通常包括声明和类型的匹配,类型的转换。比如当一个浮点型的表达式赋值给一个整型的表达式时,其中隐含了一个浮点型到整型转换的过程,语义分析过程中需要完成这个步骤。比如将一个浮点型赋值给一个指针的时候,语义分析程序会发现这个类型不匹配,编译器将会报错。动态语义一般指在运行期出现的语义相关的问题,比如将0作为除数是一个运行期语义错误。
- 经过语义分析阶段以后,整个语法树的表达式都被标识了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应的转换节点。
上面描述的语法树在经过语义分析阶段以后成为如图2-4所示的形式。
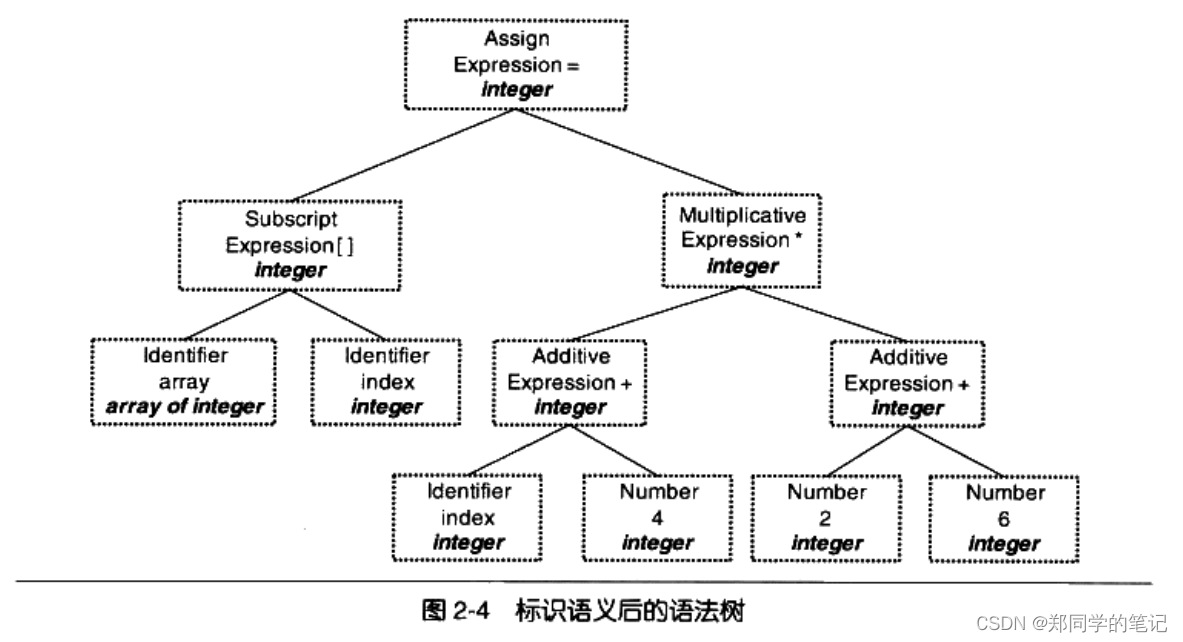
可以看到,每个表达式(包括符号和数字)都被标识了类型。我们的例子中几乎所有的表达式都是整型的,所以无须做转换,整个分析过程很顺利。语义分析器还对符号表里的符号类型也做了更新。
四、编译器的后端实现技术
编译器后端的任务就是生成目标代码(汇编代码),然后再由汇编器生成机器码,生成的文件叫目标文件,最后再使用链接器就能生成可执行文件或库文件了。

另外一种形式是生成字节码,保证代码的可移植性。在某些场景下,我们没法提前知道,程序运行的目标机器,所以,也就没有办法提前编译。
元语言,先编译成字节码,到了具体运行的平台上,再即时编译成目标代码来运行。
中间代码AST使得编译器可以被分为前端和后端。编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转换成目标机器代码。这样对于一些可以跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端。
目标代码生成与优化
源代码级优化器产生中间代码标志着下面的过程都属于编辑器后端。编译器后端主要包括代码生成器(Code Generator)和目标代码优化器(Target Code Optimizer)。
参考
1、《程序员的自我修养链接装载与库》
2、其他资料