@[目录]
目录
#数据类型详细介绍
数据类型介绍
整型家族归类:
浮点型家族归类:
构造类型:
指针类型:
空类型:
#整型在内存中的存储
#大小端字节序存储
#浮点数在内存中的存储
为什么会这样?
一:不是全0也不是全1
二:全0
三:全1
#数据类型详细介绍
数据类型介绍
char //字符型 // 1字节
short //短整型 // 2字节
int //整型 // 3字节
long //长整型 // 4字节或8字节 // C规定大于等于int
long long //更长的整型 // 8字节
float //单精度浮点型 // 4字节
double //双精度浮点型 // 8字节
整型家族归类:
signed char // char这里不能确定是有符号的,C语言没有明确规定
unsigned char
signed short // 等同于short
unsigned short
signed int // 等同于int
unsigned int
signed long // 等同于long
unsigned long
浮点型家族归类:
float
double
构造类型:
结构体类型
枚举类型
共用体类型(联合类型)
自定义类型
指针类型:
int* pi
char* pc
long* pl
short* ps
float* pf
double* pd
空类型:
void //函数中 example: void reverse();
void*
#整型在内存中的存储
计算机中对整型数据的存储采用二进制(注意计算机中数据都存为补码的形式)
原码:将数值翻译成二进制就是原码
反码:正数同原码,负数符号位不变,其他位取反,0变1,1变0
补码:正数同原码,负数为其反码+1
对signed类型的数据来说有数值位和符号位一说,对于unsigned类型的数据来说只有数值位
符号位是在二进制的最高位上,short 2个字节,16个bit位,最左边那一位就是符号位,0为正,1为负,存储数据大小范围是 -32768 ~ 32767.那么为什么负数不是-32767呢?
int main()
{
// 1的原码:00000000 00000000 00000000 00000001
// short类型16个bit位,所以会发生数据的截断,从低位开始截断
// 所以a中数据原码和补码为 00000000 00000001
short a = 1;
// 1的原码:00000000 00000000 00000000 00000001
// 1的补码:00000000 00000000 00000000 00000001
// -1的反码:11111111 11111111 11111111 11111110
// -1的补码:11111111 11111111 11111111 11111111
// b的原码:00000000 00000001
// b的补码:11111111 11111111
short b = -1;
//那么接下来就可以看一下-32768和32767了
// 32767原码:01111111 11111111 只有十五个数值位,最左边一位是符号位
// 32767补码:01111111 11111111
//-32767原码:11111111 11111111
//-32767补码:10000000 00000001
//那么-32768怎么来的呢?
//发现了吗,是不是有一个补码没有用上?似乎没有值对应啊?
//是的,补码10000000 00000000,所以C语言就给它规定了一个值,就是-32768
//于是就有了short能存的数据大小范围,int,char,long也是同理的。
return 0;
}
那么为什么计算机中,对正数和负数都存补码呢,其实是为了方便计算。
int main() { int a = 1; int b = -1; //进行a+b的运算 // // 若存储原码: // a的原码:00000000 00000000 00000000 00000001 // b的原码: 10000000 00000000 00000000 00000001 // a+b:10000000 00000000 00000000 00000010 // 结果为-2,当然不对了 // // a的补码 00000000 00000000 00000000 00000001 // b的补码 11111111 11111111 11111111 11111111 // a+b 00000000 00000000 00000000 00000000 // 结果为0 return 0; }
#大小端字节序存储
大端字节序存储:数据的低位(字节序的内容)存储在内存的高地址处,而数据的高位(字节序的内容)存储在内存的低地址处。
小端字节序存储:数据的低位(字节序的内容)存储在内存的低地址处,而数据的高位(字节序的内容)存储在内存的高地址处。
废话不多说,上图:
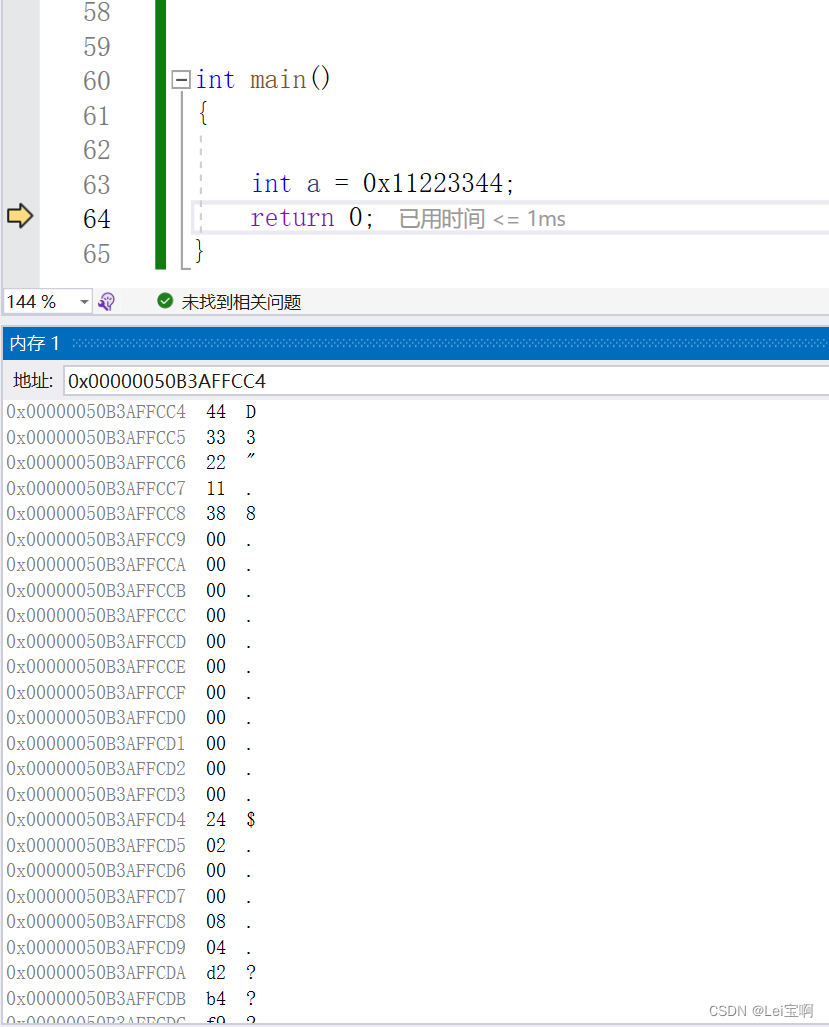
所以我所用的编译器是小端存储,低位的44存在了低地址处。
#浮点数在内存中的存储
先来一个引例;
#include <stdio.h>
int main()
{
int n = 6;
float* pf = (float*)&n;
printf("%d\n", n); // 6
printf("%f\n", *pf); // 0.000000
*pf = 6.0;
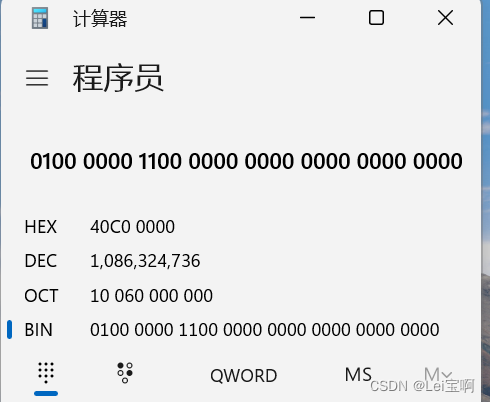
printf("%d\n", n); // 1086324736
printf("%f\n", *pf); // 6.000000
return 0;
}
为什么会这样?
这就是因为浮点数在内存中的存储方式和整数不同的原因,所以以不同的方式存储和和从内存中读取出来的数据是截然不同的。
在浮点数的存储方式中,首位是符号位,对float来说,接下来8位为指数位,剩下的23位为有效数字位,对double来说,11位指数位,剩下52位是有效数字位。
按照国际标准IEEE754任意一个浮点数可以表示成如下形式:
(-1)^0 * M * 2^E
(-1)^1 * M * 2^E
(-1)^0或1是符号位
M是有效数字位,用科学计数法表示,M大于等于1,小于2
2^E是指数位
举个例子:
9在计算机中以补码存储
00000000000000000000000000001001
1001可以表示为1.001 * 2^3
(-1)^0 * 1.001 * 2^3
所以以浮点数类型存储在计算机中的补码为
0 10000010 0010000000000000000000
IEEE754对指数E和M还有一些特殊的规定:
M存储时只存小数点后的数据,小数点前默认为1,且这个1不存,在读取数据的时候在前面加1,这样做的目的是节省一位有效数字,本身有效数字就只有23位,这么做就相当于可以存24位有效数字,提高了精度。
对于指数E,情况就稍微复杂一点
首先,E是一个无符号整数,unsigned int类型,如果是8位的话,他的取值范围就是0~255,如果是11位的话,取值范围为0~2047,但是科学计数法中的E是可以出现负数的,比如,
0.5 // 小数部分二进制表示为0.1
表示为(-1)^0 * 1.0 * 2^(-1) E为-1
所以IEEE754规定,存入内存的E的真实值时,必须加上一个中间数,这个中间数就是127和1023,对应float和double。
像E为-1时就保存为126,即00111111 (float)
然后指数E从内存中取出还可以分成3种情况
一:不是全0也不是全1
这时候采用如下方式取E
用内存中存E的值减去127(1023)得到E的真实值,再将有效数字M加上前面的1
例如:
0.5在内存中存为0 00111111 00000000000000000000000
读取时23位0前加上1,就是1.0,E就是126-126=-1,这就是E的真实值,所以接下来计算
(-1)^0 * 1.0 * 2^(-1) = 0.5
二:全0
这时E的真实值为1-127或1-1023,并且在读取数据时,有有效数字前面不再加1,而是还原为0.xxxxxxxxx,这样做是为了表示+-0,以及接近于0的数字
三:全1
这时,E的真实值为255-127或2047-1023,表示一个非常大的数字,即+-无穷大
接下来就可以解释上述代码为什么会输出那样的结果了
int main()
{
int n = 6;
//按照整数的存储方式
//00000000000000000000000000000110
float* pf = (float*)&n;
printf("%d\n", n); //以整数形式读取数据
printf("%f\n", *pf);//以浮点数形式读取数据
*pf = 6.0;
//按照浮点数的存储方式
//0 10000001 10000000000000000000000
printf("%d\n", n); //以整数形式读取数据
printf("%f\n", *pf); //以浮点数形式读取数据
return 0;
}
完结撒花~