如何用Python写个网页爬取程序
- 准备开发工具
- 安装Python
- Python安装pip
- Pip安装爬取插件
- 准备好网页地址
- 代码实现
准备开发工具
额,作者用的是vscode。具体怎么安装自行百度哈,这个都不会建议就不要学爬取了。
不忍心藏着也,给你个方法吧
- vscode下载
- windows如何安装vscode
安装Python
怎么安装?这个不会建议也不要学爬取了。算了出于善良,给你们指条明路。
- windows如何下载Python
- 如何配置Python环境变量
- vscode如何配置Python开发环境
Python安装pip
在开发工具配置好py环境后直接上代码就完事了。
python.exe -m pip install --upgrade pip //py 更新pip
python.exe -m pip install //py 安装pip
py -m pip install //这是一个缩写格式
Pip安装爬取插件
为了快速讲解,直接上代码吧
pip install requests //安装请求插件
pip install beautifulsoup4 //直接抽取图片内容的插件
准备好网页地址
知道你们想偷懒,送你们了,不谢
https://www.vcg.com/creative/
代码实现
我们知道网页中图片的格式一般是
<img src="https://xxx.com/xx.jpg/img/png/webp">
但很不幸有些网站的内容并非如此,我们来看下如下代码爬取的内容
import requests
url = "https://www.vcg.com/creative/"
response = requests.get(url)
if response.status_code == 200:
content = response.content.decode("utf-8")
print(content)
else:
print("Failed to retrieve content from", url)
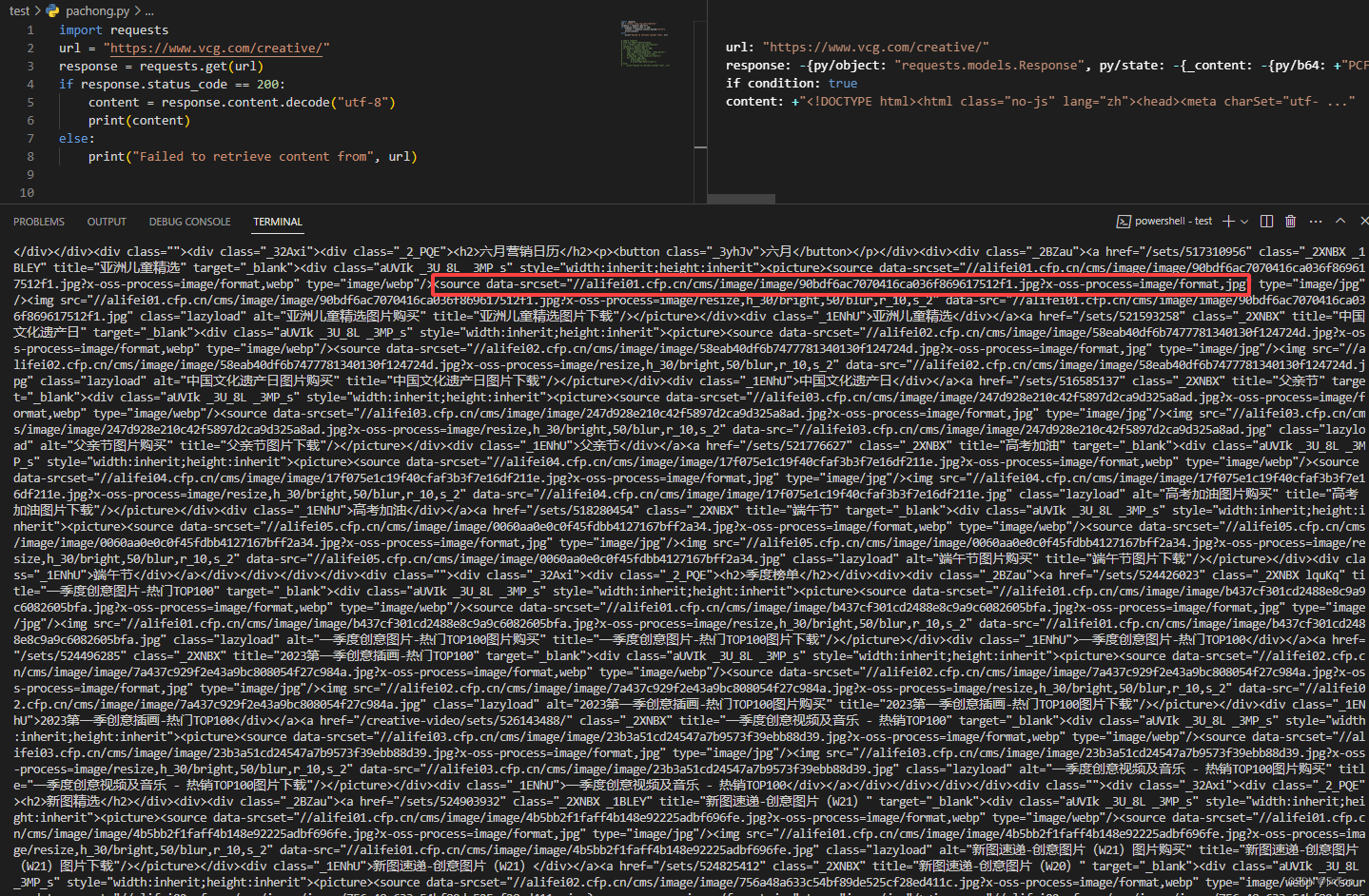
网页中图片居然是这种格式显示的
<source data-srcset="//alifei01.cfp.cn/cms/image/image/90bdf6ac7070416ca036f869617512f1.jpg?x-oss-process=image/format,jpg" type="image/jpg"/>
针对上诉该如何是好呢?
这个就要用到我们上诉安装的beautifulsoup4 抽取图片连接的工具,来看看怎么用吧。先给你们看下效果,不懂再看下方解释
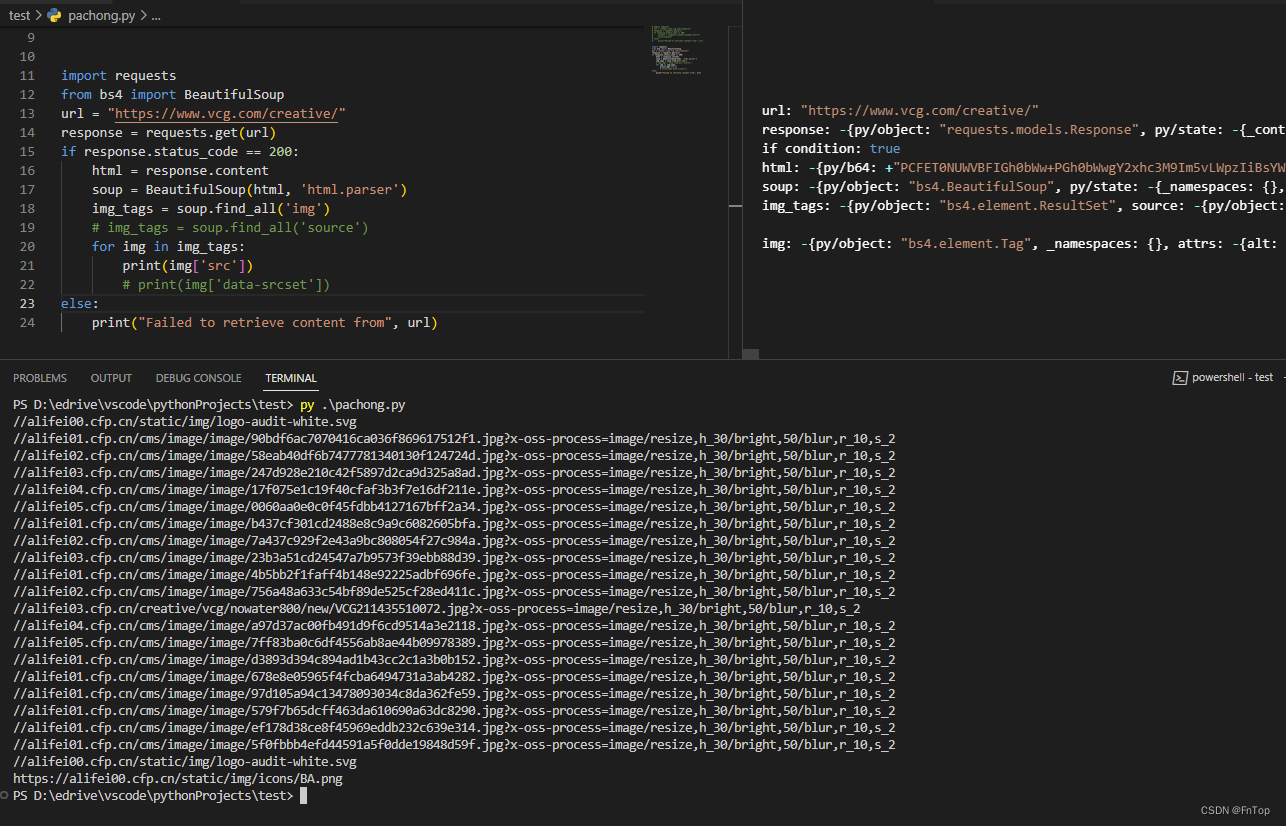
代码解释
import requests
from bs4 import BeautifulSoup
url = "https://www.vcg.com/creative/"
response = requests.get(url)
if response.status_code == 200:
# 获取网页内容
html = response.content
# 解析html格式网页,可以是其他格式
soup = BeautifulSoup(html, 'html.parser')
# 根据图片标签获取标签属性内容。正常情况都是<img src="">这种,而我们的是<source data-srcset="">
#img_tags = soup.find_all('img')
img_tags = soup.find_all('source')
for img in img_tags:
print(img['src'])
# print(img['data-srcset'])
else:
print("Failed to retrieve content from", url)
当然通过上诉代码我们可以爬取不同的网页格式内容。以及多种格式的标签图片,我们取个并集就好了。
爬取的内容
//alifei02.cfp.cn/cms/image/image/58eab40df6b7477781340130f124724d.jpg?x-oss-process=image/format,webp
//alifei02.cfp.cn/cms/image/image/58eab40df6b7477781340130f124724d.jpg?x-oss-process=image/format,jpg
//alifei03.cfp.cn/cms/image/image/247d928e210c42f5897d2ca9d325a8ad.jpg?x-oss-process=image/format,webp
//alifei03.cfp.cn/cms/image/image/247d928e210c42f5897d2ca9d325a8ad.jpg?x-oss-process=image/format,jpg
//alifei04.cfp.cn/cms/image/image/17f075e1c19f40cfaf3b3f7e16df211e.jpg?x-oss-process=image/format,webp
//alifei04.cfp.cn/cms/image/image/17f075e1c19f40cfaf3b3f7e16df211e.jpg?x-oss-process=image/format,jpg
//alifei05.cfp.cn/cms/image/image/0060aa0e0c0f45fdbb4127167bff2a34.jpg?x-oss-process=image/format,webp
//alifei05.cfp.cn/cms/image/image/0060aa0e0c0f45fdbb4127167bff2a34.jpg?x-oss-process=image/format,jpg
//alifei01.cfp.cn/cms/image/image/b437cf301cd2488e8c9a9c6082605bfa.jpg?x-oss-process=image/format,webp
//alifei01.cfp.cn/cms/image/image/b437cf301cd2488e8c9a9c6082605bfa.jpg?x-oss-process=image/format,jpg
//alifei02.cfp.cn/cms/image/image/7a437c929f2e43a9bc808054f27c984a.jpg?x-oss-process=image/format,webp
//alifei02.cfp.cn/cms/image/image/7a437c929f2e43a9bc808054f27c984a.jpg?x-oss-process=image/format,jpg
//alifei03.cfp.cn/cms/image/image/23b3a51cd24547a7b9573f39ebb88d39.jpg?x-oss-process=image/format,webp
//alifei03.cfp.cn/cms/image/image/23b3a51cd24547a7b9573f39ebb88d39.jpg?x-oss-process=image/format,jpg
//alifei01.cfp.cn/cms/image/image/4b5bb2f1faff4b148e92225adbf696fe.jpg?x-oss-process=image/format,webp
//alifei01.cfp.cn/cms/image/image/4b5bb2f1faff4b148e92225adbf696fe.jpg?x-oss-process=image/format,jpg
//alifei02.cfp.cn/cms/image/image/756a48a633c54bf89de525cf28ed411c.jpg?x-oss-process=image/format,webp
//alifei02.cfp.cn/cms/image/image/756a48a633c54bf89de525cf28ed411c.jpg?x-oss-process=image/format,jpg
假设我们取第一条
//alifei02.cfp.cn/cms/image/image/58eab40df6b7477781340130f124724d.jpg?x-oss-process=image/format,webp
这个在网页怎么访问??
很简单做个字符串的截取拼接就好了,去掉// 拼接https 去掉参数。如下
https://alifei02.cfp.cn/cms/image/image/58eab40df6b7477781340130f124724d.jpg
假设我们循环存入数据库。。。【奸笑且猥琐】
可是版权怎么办。。。【开始垂头丧气】
不管了,为了理想。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。
也不可以做违法的事。。。。。。。。。。。。。。
自己用用就好,除非人家给你版权了,那我们大可放开手脚的干