同事推荐一篇论文 Bolt: Sub-RTT Congestion Control for Ultra-Low Latency,写点想法。
端到端原则使网络在拥塞控制中始终扮演配角,人们认为拥塞控制是端到端的事。几十年来人们设计的拥塞控制机制始终围绕 “主机在什么情况下要增减 cwnd” 打转。但在数据中心,事情不一样。
你是实现复杂的 SACK(非常消耗 CPU 的算法) 任由丢包后恢复,还是构建一个不丢包的网络,后者把问题推给网络,但显然用 以太网/Internet 的设计思想很难设计出这种网络。
下面的图景该有多好:
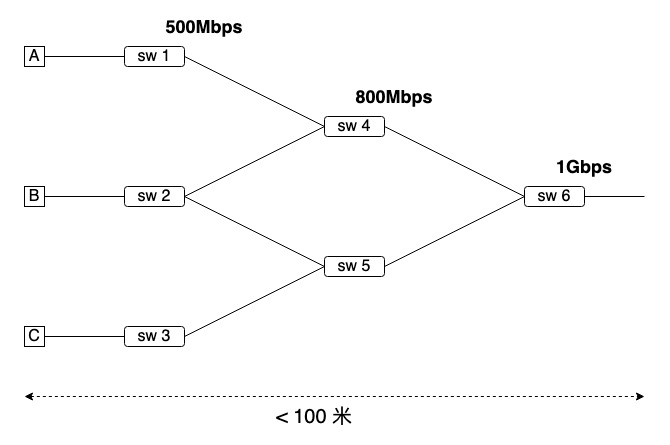
- A 传输,路由决策 sw1-sw4-sw6,资源占用 sw1:500-sw4:500-sw6:500,获得 500Mbps 吞吐;
- B 申请传输,路由决策 sw2-sw5(资源更充足)-sw6,资源预留 sw2:500-sw5:800-sw6:500,B 取最小值 500;
- B 传输;
- C 申请传输,路由决策 sw3-sw5-sw6,资源预留 sw3:500-sw5:400-sw6:333;
- sw 分别回复资源预留给 C,sw5 回复资源更新给 B,sw6 回复资源更新给 A,B;
- C 传输;
- A 退出传输;
- B 路由重收敛到 sw2-sw4-sw6,资源更新 sw4:800,sw6:500 回复给 B,sw6:500 回复给 C;
- …至于 incast 问题,如果能在极短的时间(< 10us) 预约临时时间槽,显然不错,但也可以利用等价多路径以及拓扑将扇入数据散列开,别忘了,交换机和主机是相互知晓的。这种网络非常适合与 homa 结合,消除 unscheduled 传输的重传时延以及优化 scheduled 传输的 quota feedback 复杂性。
这是一种与以太网(或任何组成 Internet 的网络)截然不同的网络,网络核心深度参与传输控制而不再仅仅尽力而为。
网络规模只要足够小(RTT 足够小),在广域网上被认为耗时的操作将可行,协作式网络就变得可能。
协作式网络需主机和交换机彼此交互和理解。交换机要知道主机报文的含义,主机也依赖交换机(而不是对端主机)反馈的信息。
以上想法来自两个尺度缩放问题。
正如以太网冲突域缩小到芯片尺寸后交换芯片替换 CSMA/CD 一样,网络尺寸从广域缩小到数据中心内部,全局流控也可替换分布式拥塞控制。
另一方面,网络尺寸缩小到数据中心,主机处理时延占比将变大,重传代价变大,驱使复杂性向网络转移,比如尽量不丢包代替快速恢复,网络将分担更多控制面任务,大幅卸载主机传输控制策略以平摊端到端时延,端到端原则在数据中心将被重估。
网络规模小,拓扑规则,RTT 小,路由收敛快,不但能以流控代替代价高昂的丢包重传,全局控制也更容易实现多路径传输。
罗马本是一个城邦,城邦民主是适合的,但随着西西里,北非,马其顿,西班牙,高卢进入版图,尺度变大,城邦民主制度就不再适合,这意味着城邦民主制度是不可扩展的…帝国制度采用集中式控制还是分布式控制,开销完全不同,这是一个控制面和尺度如何适配的问题。网络问题都是社会问题的复现,社会即网络。百字短文,不多说。
浙江温州皮鞋湿,下雨进水不会胖。