❝如此好看的头像,怎么能不喜欢???
❞
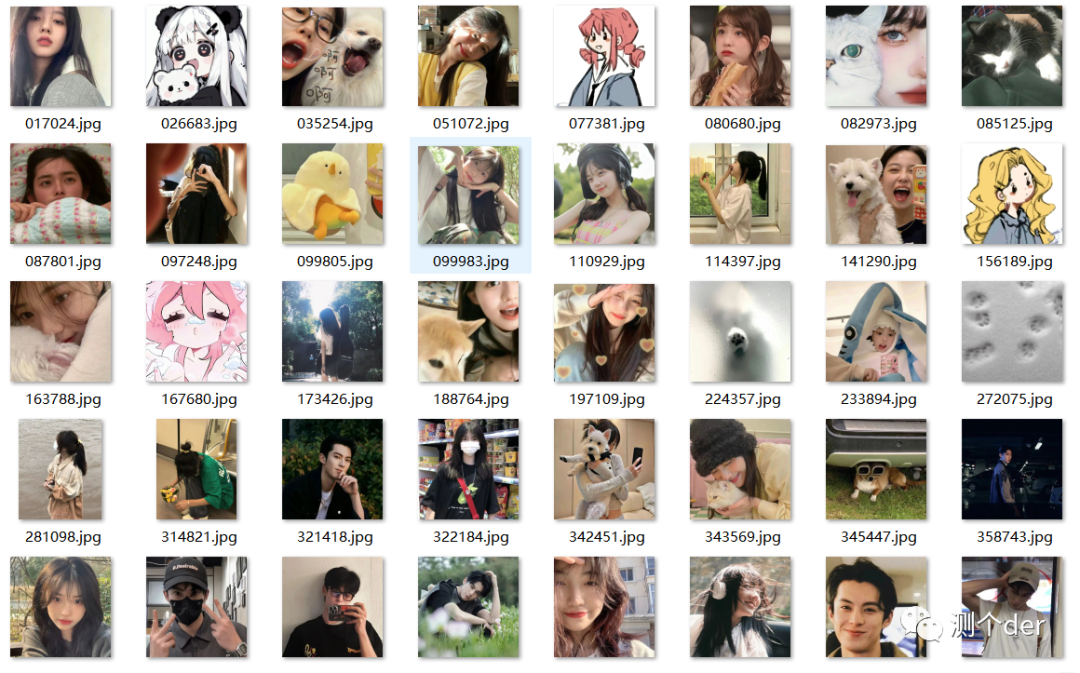
代码放在了最后
后续还会出一个工具,以便于随时打开下载。
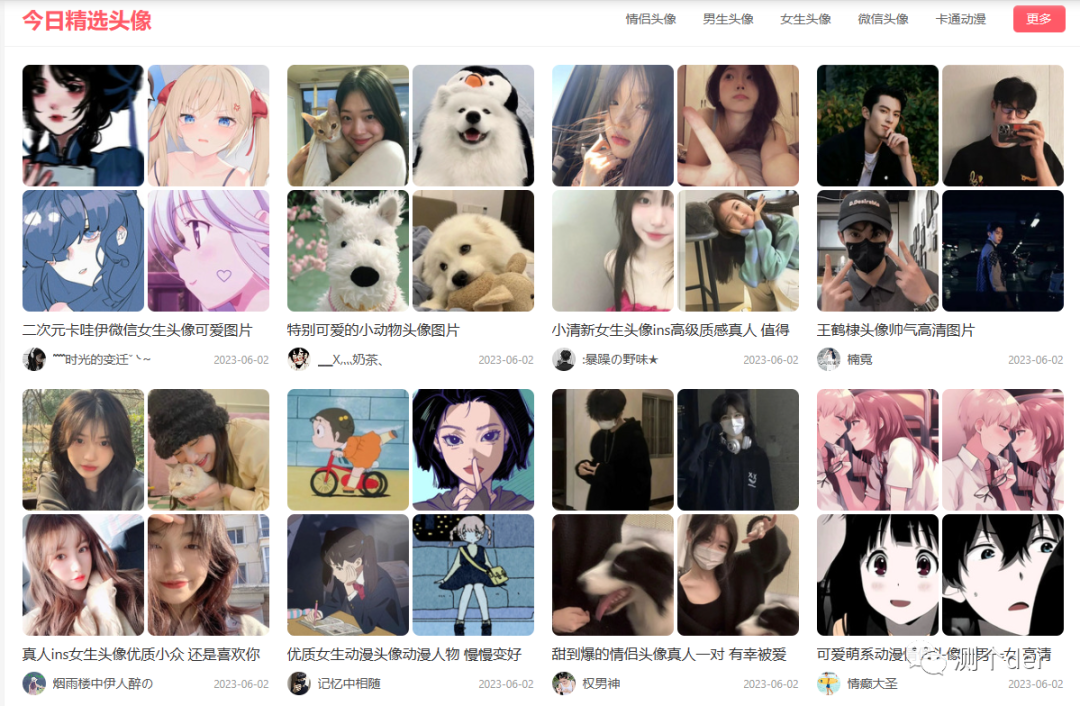
看上述的头像是不是还是很不错的。看着网站还是✨✨每天都会有更新的✨✨。
所以,我动手了,下载下载来的头像是真的不错💥💥

我们需要的是这些,问就是,要最高清的图片。所以宁愿程序复杂点。
先把上述图片中的url搞出来。用到了bs4.
URL = 'https://www.ddtouxiang.com'
html = requests.get(URL,headers=headers)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text,'lxml')
HREFS = soup.findAll(class_='index_tx_item_title')
# print(HREFS)
for value in HREFS:
A_HREF = value.find('a')
HREF_URLS.append(URL+A_HREF.get('href'))这样就能过滤出精选的各博主分享的url了。
这个界面获取到url我们再次访问内部的图片链接,以便于浏览更高清的图片

for IMG_URL in HREF_URLS[:5]:
IMG_HTML = requests.get(IMG_URL,headers=headers)
IMG_HTML.encoding = 'utf-8'
IMG_SOUP = BeautifulSoup(IMG_HTML.text,'lxml')
IMG_SRC = IMG_SOUP.findAll('img',class_='detail_picbox_img')
for src in IMG_SRC:
IMG_URLS.append(src.get('src'))先拿前五个试试水,如果想有多少下载多少,那就直接将HREF_URLS[:5]的[:5]删除即可。
def run(url):
header = {
"User-Agent": random.choice(UA_LIST),
'Referer': url
}
path = r"E:\picture\精选头像\\"
pic = requests.get(url,headers=header)❝最后的代码中请求的时候headers中用到了Referer,需要注意一下。不加上的话,下载的图片无法查看(下载寂寞)。
❞
❝其次就是注意路径path = r"E:\picture\精选头像\"换成自己的。
❞
最后简单的封装一下就好了。直接看源码吧。
❝仓库地址:https://gitee.com/qinganan_admin/reptile-case/blob/master/%E5%A4%B4%E5%83%8F/%E7%B2%BE%E9%80%89%E5%A4%B4%E5%83%8F%E4%B8%8D%E9%87%8D%E6%A0%B7.py
❞
期待工具下载吧,直接下载输入该网址的头像即可下载。