深度学习自然语言处理 原创
作者 | 刘嘉玲
随着开源语言大模型(LLM)的百花齐放,模型的性能和效率关乎到产品的成本和服务体验的均衡。那么,有没有办法让语言大模型变得更高效、更优秀呢?
为了进一步提高开源模型的上限,清华大学的研究团队给出了一个答案:通过扩大高质量指导性对话数据,显著提高了模型的性能和效率。如下图所示,UltraLLaMA问鼎LLM榜!
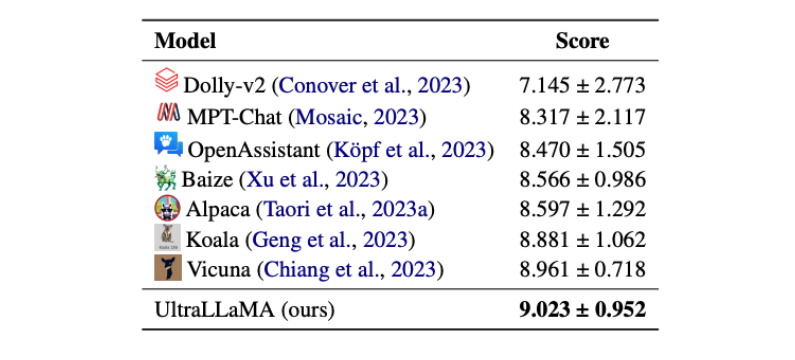
被网友评价:包含150万个高质量,多样化的多回合对话的UltraChat,优于SotA开源模型Vicuna。 我们一起仔细读读论文,看看能带来哪些启示~
我们一起仔细读读论文,看看能带来哪些启示~
论文:Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
地址:https://arxiv.org/pdf/2305.14233.pdf
代码:https://github.com/thunlp/UltraChat进NLP群—>加入NLP交流群
1 论文项目概述
为了进一步提高开源模型的上限,论文提出了一种新的聊天语言模型——UltraLLaMA,它是通过提供多样化、高质量的指令对话数据集UltraChat上微调LLaMA模型得到的,成功提升了聊天语言模型的性能。
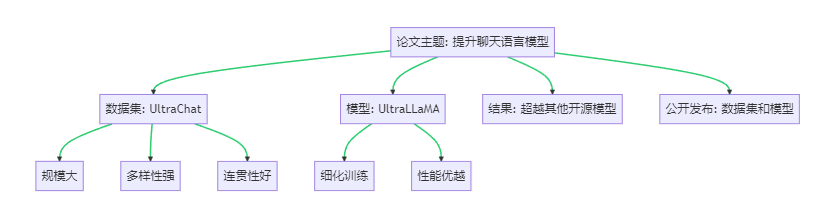

2 UltraChat多模态数据集是如何构建的?
构建设计:UltraChat的总体思路是使用单独的LLM来生成开场白、模拟用户和响应查询。UltraChat的三个方案:关于世界的问题、写作和创作、对现有材料的协助都有特点的设计,如下图:
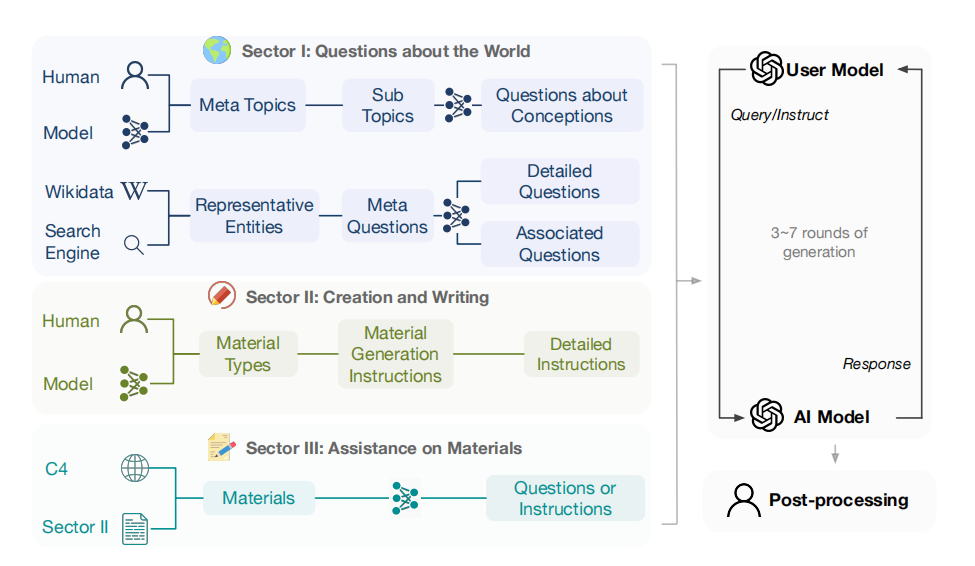
2.1 关于世界的问题
这部分数据主要关注的是现实世界中存在的概念、对象和实体。
收集这部分数据的方法有两个角度:一个是围绕主题和概念,另一个是围绕现实世界的实体。
请求ChatGPT生成30个涵盖我们日常生活各个方面,具有代表性和多样性的元主题,如下图:

构建过程:
首先,根据这些元主题生成了1100多个子主题;同时从维基数据中收集了最常用的10,000个现实世界的命名实体,比如人物、地点、事件等。
再为每个子主题设计了最多10个具体的问题;每个实体设计了5个基本问题,10个具体问题和20个扩展问题。
然后使用Turbo API为10个问题中的每一个生成新的相关问题。想用这些问题来创建对话,所以从大约500,000个问题中筛选和抽样了一些作为对话的开头。
使用手工制作的prompt来指示模型生成涵盖各种常见概念和对象的各种问题,要求它回答简洁、有意义,并且考虑到对话历史的上下文。
最后对200k个特定问题和250k个一般问题以及50k个元问题进行采样,并迭代地生成多轮的对话。
2.2 写作和创作
这部分的目的是根据用户的指示,自动生成不同类型的写作文本。
使用ChatGPT使其根据用户的指示,生成20种不同类型的写作文本,比如故事、诗歌、论文等。

构建过程:
对于每种类型的写作,生成200条不同的prompt,让AI助手生成文本材料,其中80%的指令被进一步扩展和细化。
将生成的指令作为初始输入,分别生成2~4轮的对话。
2.3 对现有材料的协助
这部分的目的是根据现有的文本材料,生成不同类型的任务,比如改写、翻译、总结等。
用到包含了大量文本片段和源URL的数据集的C4语料库,和20种故事、诗歌、论文等不同的材料类型。
构建过程:
从C4数据集中提取了约10w种不同的材料。
为每种类型设计了一些关键字,得到了根据关键字和URL对文本片段进行归类后的材料。
用ChatGPT为每份材料生成最多5个问题/说明。
将每个问题/指令的材料与一组手动设计的模板结合起来,作为用户的初始输入,开始与 AI 助手的对话。
得到了50万个对话开头,每个对话开头包含了一个文本片段和一个任务指令。对于每个输入,生成 2~4 轮对话。

2.4 数据集评价
UltraChat数据集是一个大规模的多模态对话数据集,它包含了超过100万个对话,每个对话平均包含8轮对话。其中不仅包含了文本信息,还包含了音频、视频和屏幕共享数据。
UltraChat与其他几个指令数据集进行统计分析比较,结果下表所示。
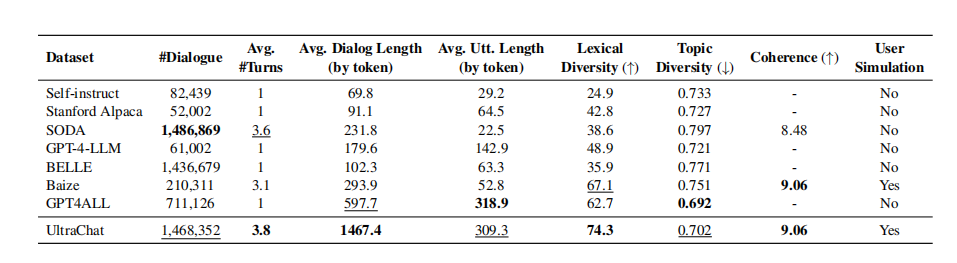
UltraChat在规模、平均回合数、每个实例的最长平均长度和词汇多样性方面都优于其他数据集,是最大的开源数据集之一。
UltraChat的话题多样性略低于GPT4ALL,但仍高于其他数据集。这可能是因为UltraChat的每个对话包含更多的令牌,而GPT4ALL的每个对话只有一个回合。
评估数据集的连贯性,发现UltraChat和Baize的数据在一致性方面排名最高。
3 UltraLLaMA对话模型有多强大?
模型基本情况:
改进LLaMA-13B模型的UltraLLaMA,能够更好地理解对话上下文。
为了使模型能够利用对话前面部分的信息,生成更相关和连贯的回复,研究者们将对话切分为较短的序列,最大长度为2048个标记,并只优化模型响应的损失函数。
使用交叉熵损失和128A100gpu来微调模型,总批量大小为512。
建立评估数据集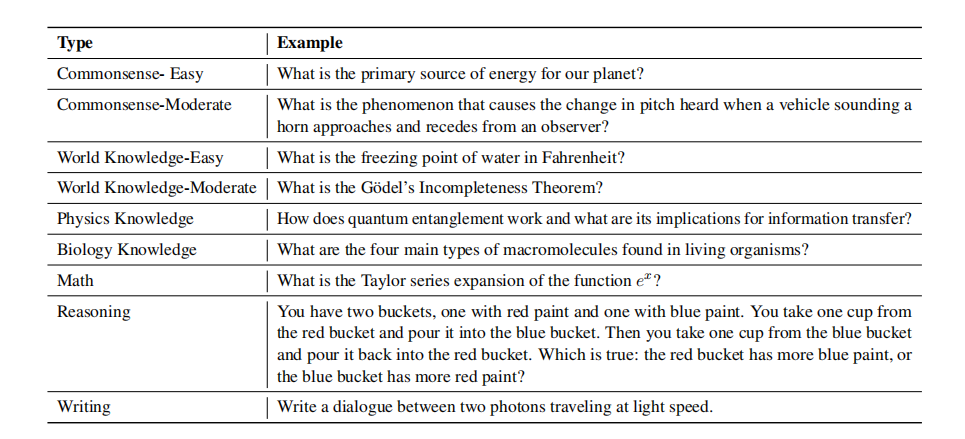
构建了一个评估集,包含Vicuna基准和GPT-4生成的300个问题/指令,涉及多个主题和难度等级,如上表所示。
使用TruthfulQA基准来评估模型和基线的世界知识,检测它们是否能够识别真实的陈述,避免产生或传播虚假信息。
TruthfulQA基准是一个具有挑战性的测试,包含38个类别和两种评估任务:多项选择题和生成任务。
3.1 模型评价
基线评估
使用ChatGPT来评估UltraLLaMA和其他基线模型在每个问题上的回答。

给ChatGPT输入问题和两个模型的回答 ,并让它对每个回答打分,从1到10,并给出理由。
评估提示是以正确性为主要标准。
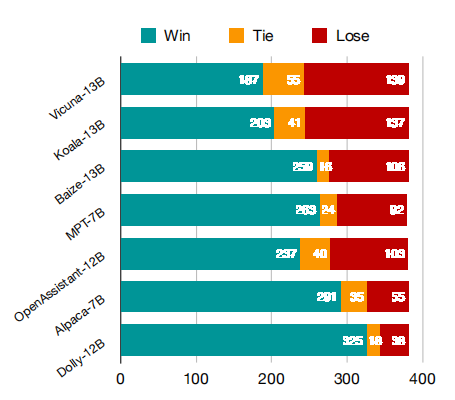
比较了UltraLLaMA和其他基线模型在评估集上的Win/Tie/Lose次数,如上图所示。
UltraLLaMA在评估集上的表现远超其他开源模型,胜率高达85%。
UltraLLaMA的胜率比Vicuna高出13%。
独立评估

使用ChatGPT对UltraLLaMA模型和基线模型的回答进行独立评分。基于回答的质量分数从1到10。粗体表示最好的分数,下划线表示第二好的。
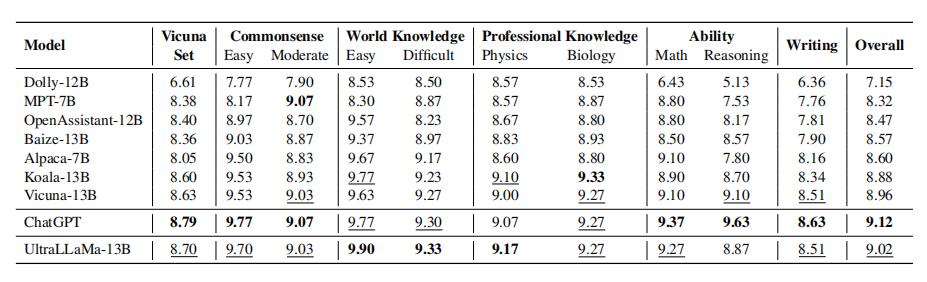
上表显示了UltraLLaMA和基线模型的得分比较。UltraLLaMA在总分和评估集的大部分部分上都优于其他开源模型,显示了其强大的能力。
这个细分也反映了每个模型在不同类型的问题和指令上的性能。一般来说,所有模型在简单的常识和世界知识相关的问题上表现更好,但在涉及推理和创造性写作的更复杂的任务上表现较差。有趣的是,LLaMA虽然参数较少,但在常识和世界知识相关的问题上与较大的模型相当,但在更苛刻的任务上落后。此外,我们还注意到,Dolly和OpenAssistant基于Pythia的模型比基于LLaMA的模型表现更差,即使它们更小。这说明了底层语言模型的重要性。
问答精确度
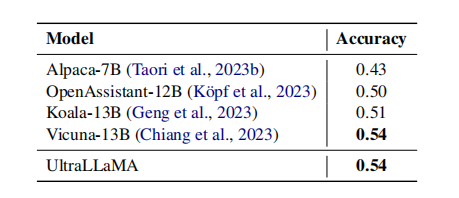
在真实QA多重回声任务上测试了UltraLLaMA和其他基线模型。让模型判断每个候选答案是真的还是假的。
下表显示了各个模型的判断准确率。发现真实判断对于现有模型来说仍然是一项困难的任务。
UltraLLaMA在这个任务上比Vicuna表现更好,也超过了其他基线。
系统提示符的影响
大家常使用系统prompt来指导各种角色和回答风格。
发现系统提示会影响模型生成的输出的质量。当模型被提示提供“有用且详细的”回答时,它会生成更相关和信息丰富的回答。
这种提示虽然不一定会提高确定性问题的准确性,但会提高回答的整体质量,因为它会包含更多的额外信息。
可以从下表中看到一个例子,其中两个回答都是正确的,但系统通过prompt引导的模型产生了更详细的回答。

4 总结
这篇论文的研究成果对于聊天语言模型的发展具有重要的意义。首先,UltraChat数据集的创建为聊天语言模型的训练提供了丰富的资源。其次,通过对LLaMA模型的微调,研究者们成功地创建了一个性能优越的对话模型UltraLLaMA,这为聊天语言模型的进一步优化提供了有力的参考。
进NLP群—>加入NLP交流群