人体关键点检测与MMPose
课程链接:https://www.bilibili.com/video/BV1kk4y1L7Xb
这个课程的大致内容是介绍如何从给定的二维影像中恢复出人体的姿态(2D或者3D),大纲如下所示,基本上可以认为流程是:先是恢复2D的关节点姿态,然后是3D的关节点姿态,最后直接演变成三维模型的姿态(更加精细)。
虽然我对这个研究方向完全不感兴趣,但是学习了解一下也不错。

2D姿态估计
2D姿态估计就是利用图片恢复人体关键点姿态,其方法思路可以分为基于回归(直接回归关键点的坐标)和基于热力图(预测关键点的位置分布图)两大类。
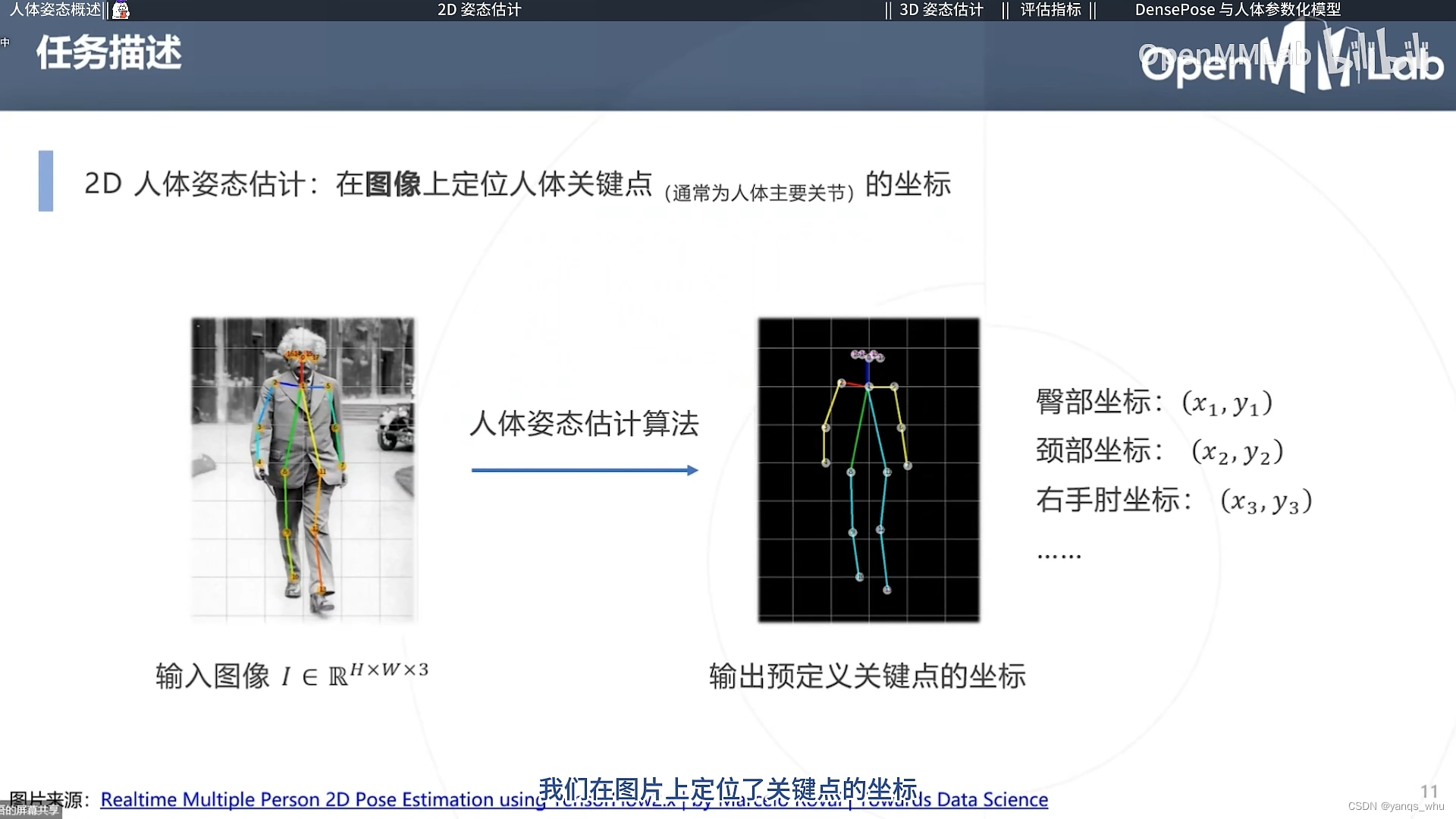
基于回归看起来很简单,但是显然无脑
a
−
b
a-b
a−b的方式很难回归出关键点的正确位姿,比较合理的方式还是预测分布。。。虽然理解起来可能有点困难,但是明显更合理。你不能要求神经网络去学习高频的东西(一张图片上只有一个正确的坐标,其他都是错误的,样本太不均匀)。

基于热力图听起来就非常合理,根据像素与关节点的位置生成热力图,然后预测一个平滑的分布图即可。当然最终应用的时候,我们只需要一个坐标值,直接加权求和就完了。
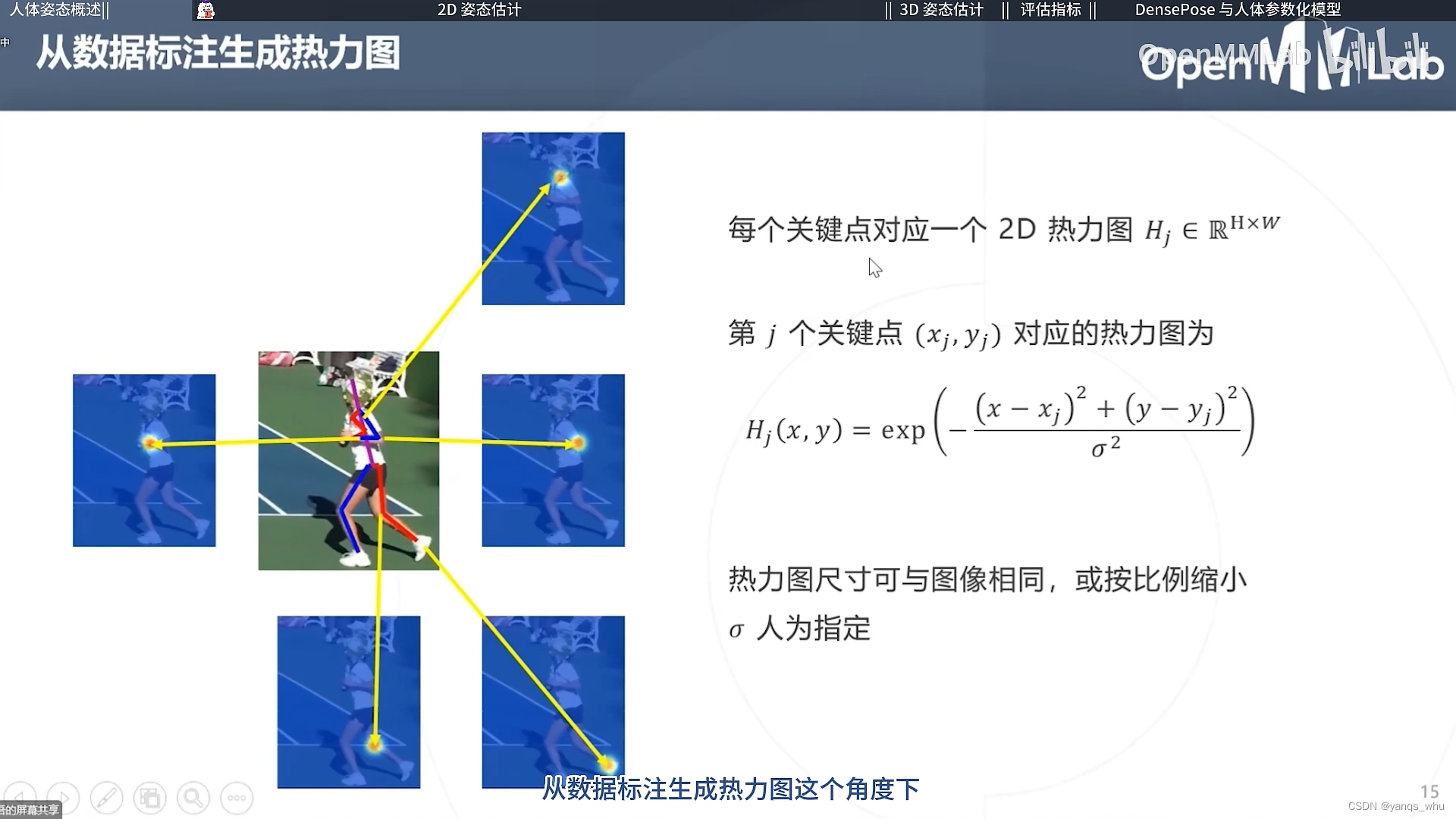
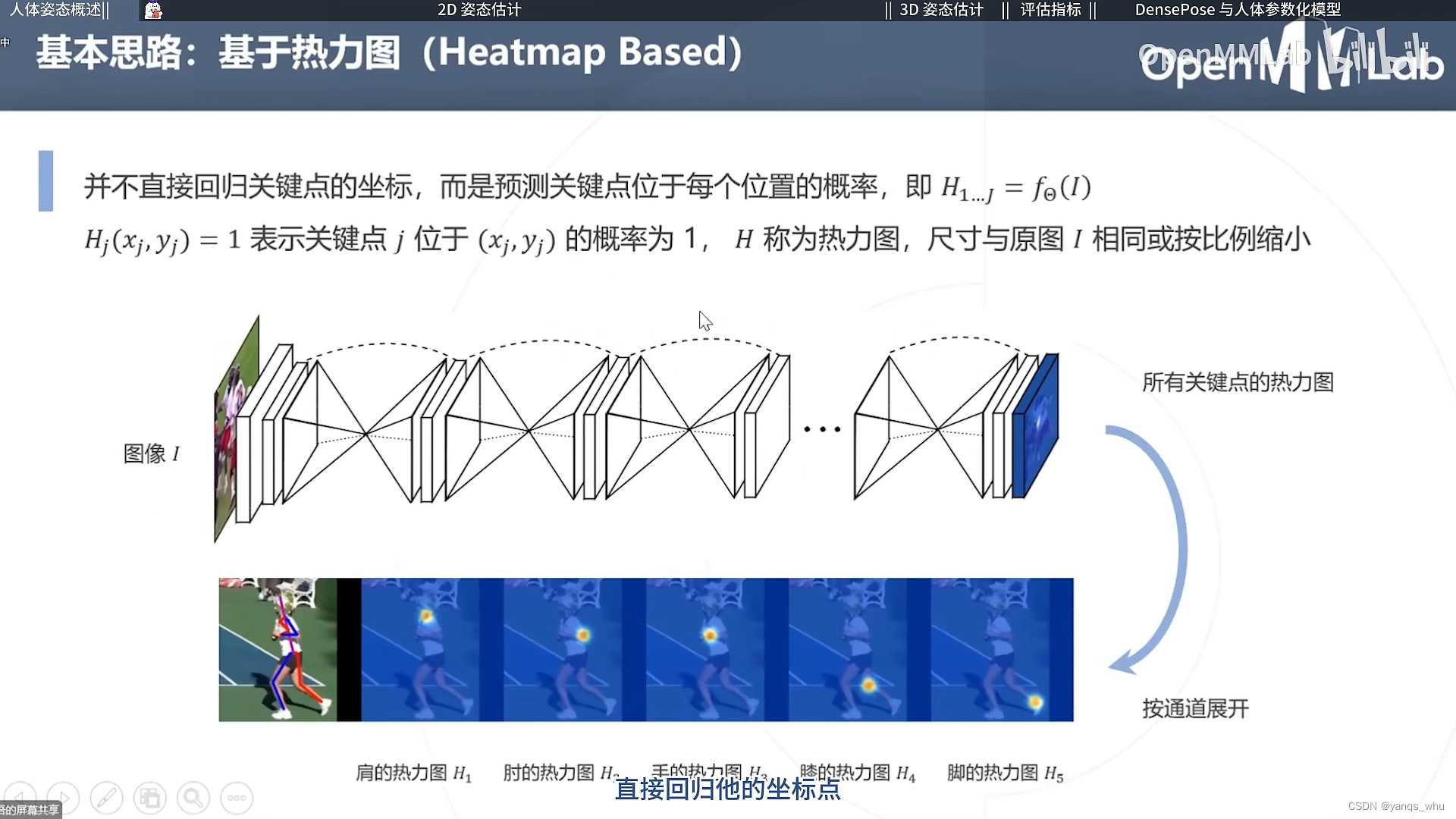
3D姿态估计
2D的坑看样子没过多久就被填满了,马上就开始回归三维坐标。提到了三种思路:直接猜、连续影像猜和多视角猜。
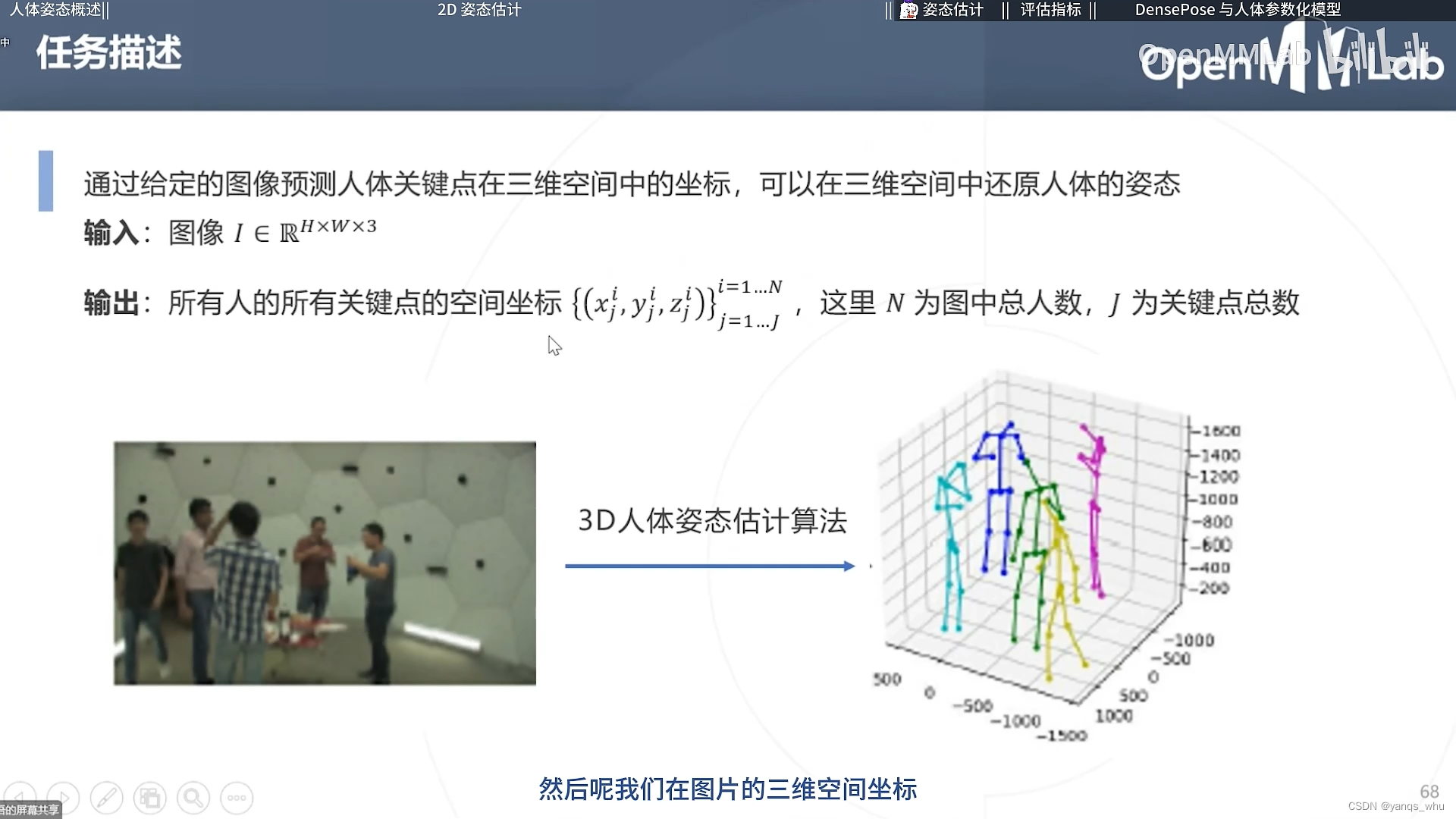
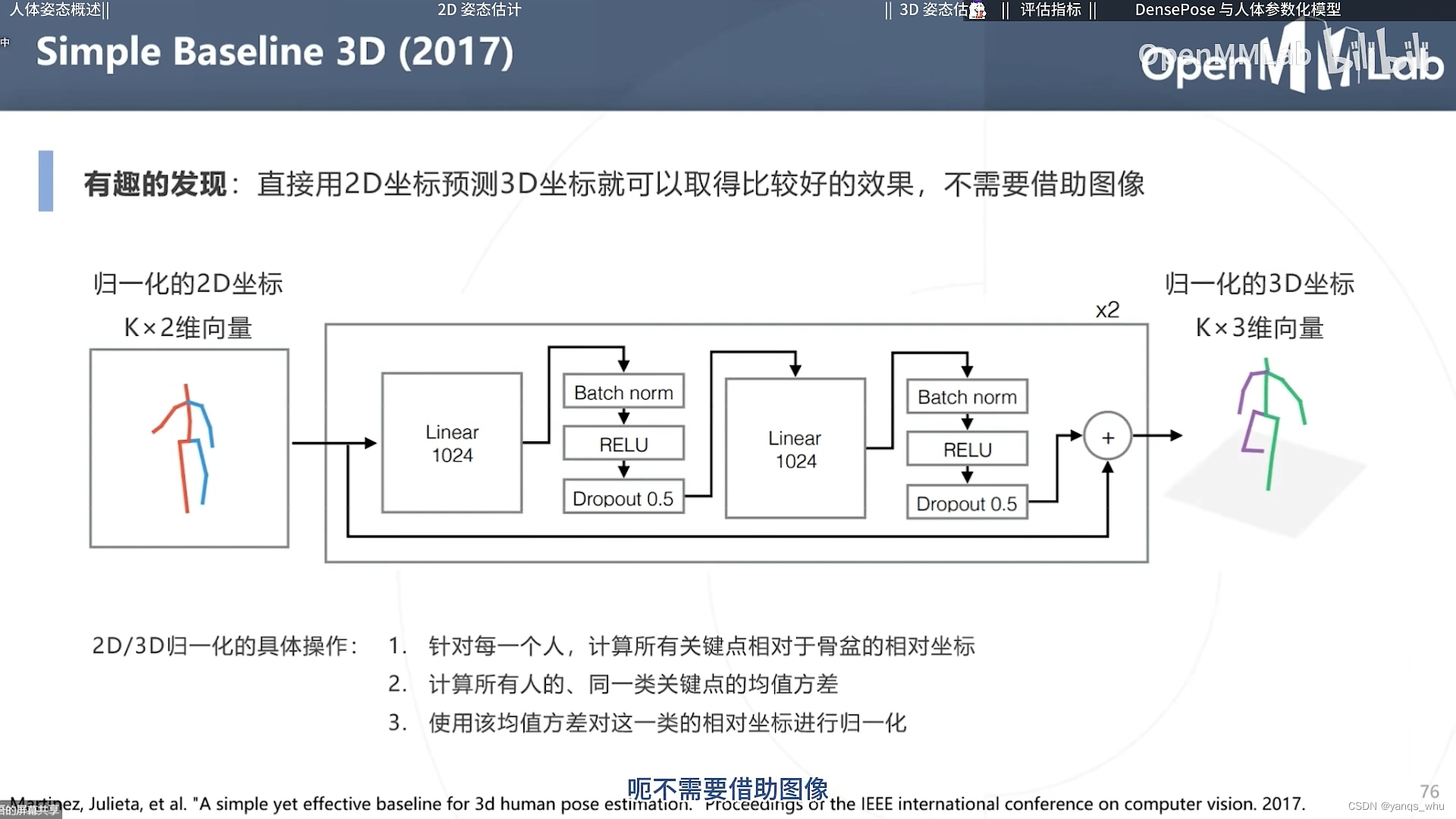
结果好像是基于2D预测结果直接猜就不错,多张猜更好。我的感觉是一个好的骨架给定后,由于人四肢躯干的长度都是固定的,2D-3D之前显然存在一个几何变换(当然我也是猜的),所以网络学习起来比较容易。
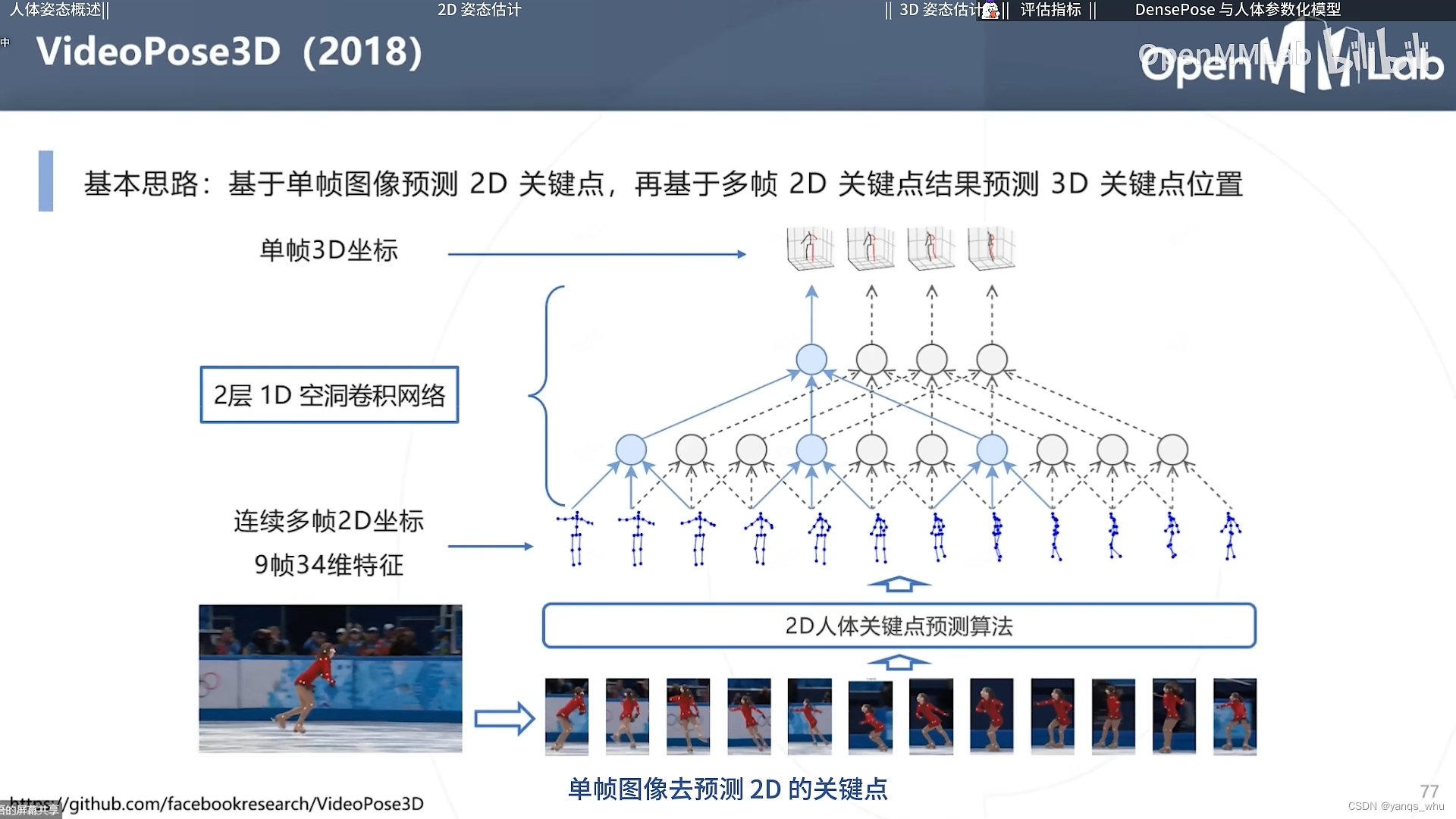
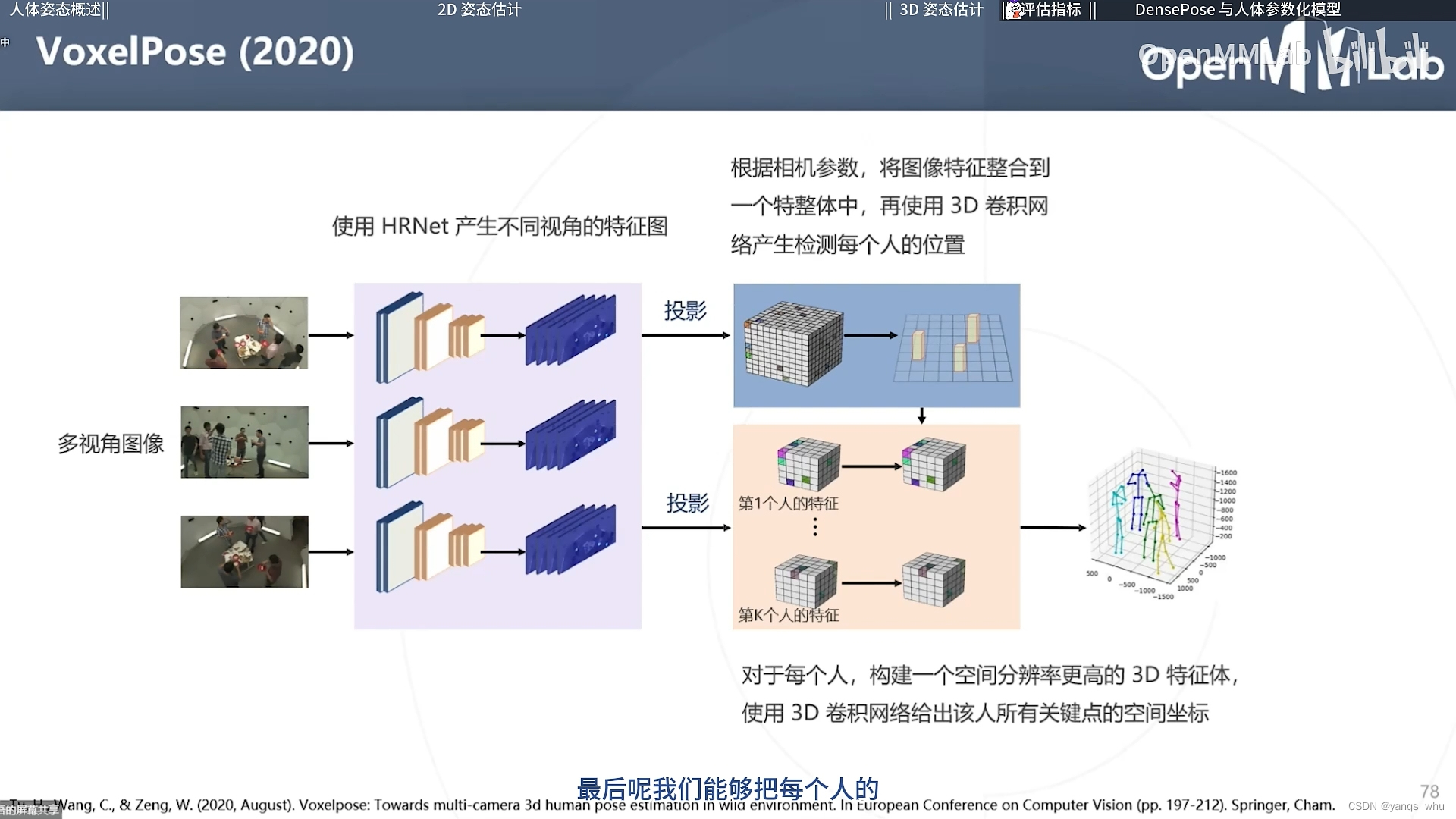
当然直接用三维热力图也是可以的。恍惚之间,在这里想起类BEV,红红火火。
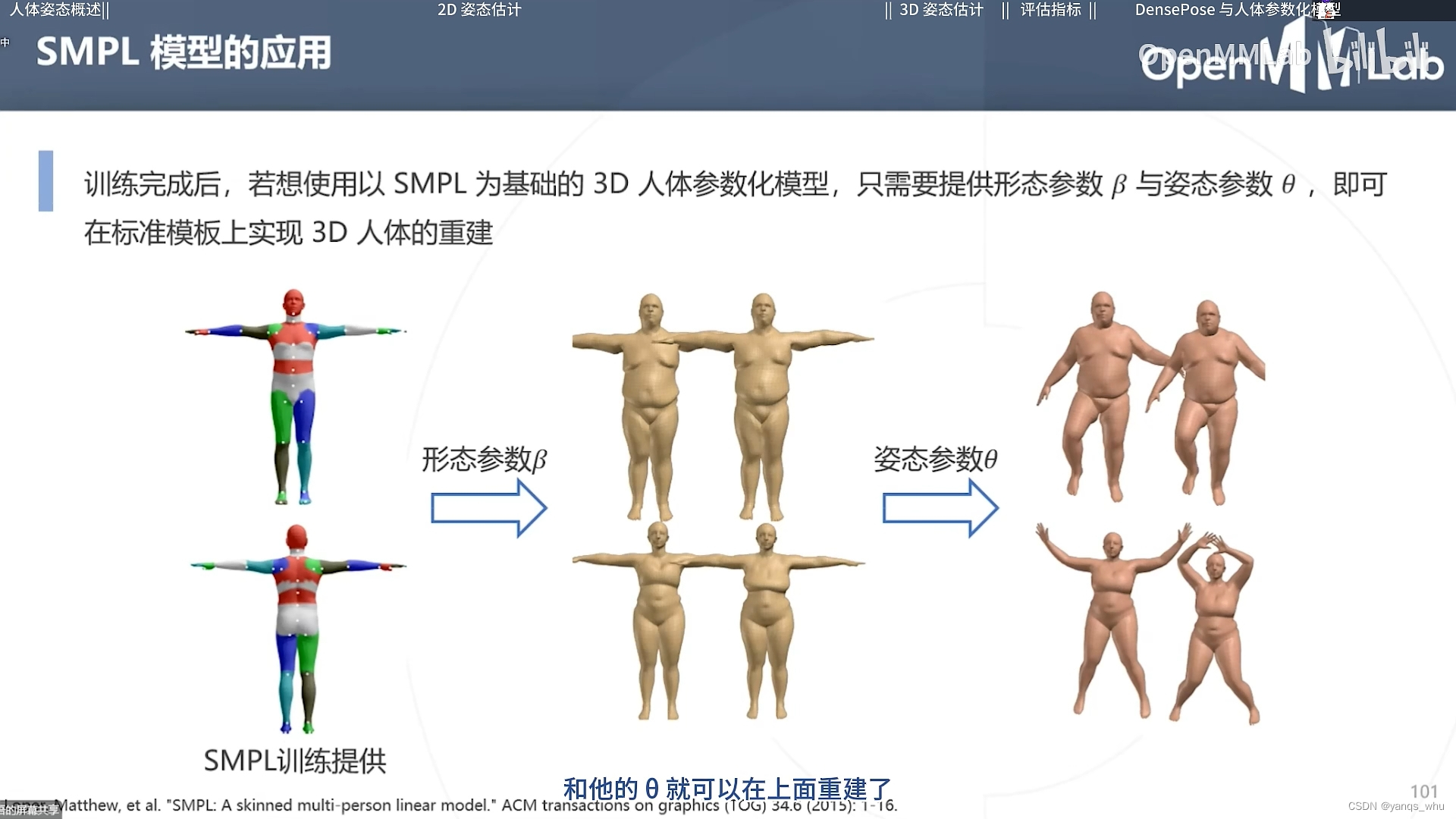
三维模型
不知道为啥并没有介绍太多3D姿态估计,估计三维模型还是更好一些。基于一些图形学的复杂工具,似乎网路的负担更低了,只需要学习一些固定的参数。
 介绍了三种,但是都没看太懂,但是反正就是某种固定的动画模式???反正就是一步一步,又回到了单张出三维模型。
介绍了三种,但是都没看太懂,但是反正就是某种固定的动画模式???反正就是一步一步,又回到了单张出三维模型。


多人姿态估计
我稍微调整了一下PPT的顺序,把某些分成了多人姿态估计。上边说的所有方法都是一个人,但是这太不场景了,更多的还是多人。有两种方法,two-stage和one-shot(目标检测只乎内行)。




![[数据挖掘02] pandas的分配和聚合函数](https://img-blog.csdnimg.cn/86d3e0a69b9a45018f7d0f34d72d0fe9.png)