作者:~小明学编程
文章专栏:Java数据结构
格言:目之所及皆为回忆,心之所想皆为过往

目录
为什么我们需要哈希表?
哈希表的原理
什么是哈希值
冲突
负载因子
解决冲突
闭散列
开散列/哈希桶
代码实现
不考虑泛型
put操作
get操作
整体代码
考虑泛型
hashCode和equals为何要同时重写
代码:
为什么我们需要哈希表?
前面我们已经讲了很多的数据结构了,例如顺序表,链表,二叉树等等,这些数据结构的增删查改的时间复杂度有的是增为O(1),但删就为O(n),有的虽然增为O(n),但是删为O(1),但是我们的哈希表很牛,增删的时间复杂度都是O(1),就问你牛杯不?下面我们就来详细的说说这是怎么实现的。
哈希表的原理
之所以我们的时间复杂度能达到O(1)是因为我们没有比较,直接将我们的元素插入到哈希表中,我们想插入的元素都会有一个哈希值,这个哈希值我们可以看作是一个地址,这样我们就相当于通过这个地址直接插入元素,当我们想要取出这个元素的时候也可以通过我们的哈希值直接找到我们的元素。
什么是哈希值
我们先来看一下这幅图
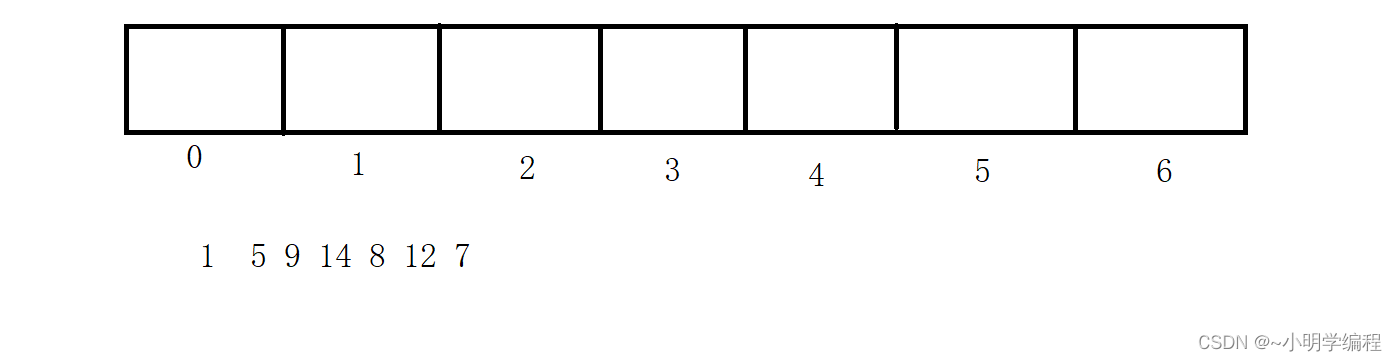
上面是我们的数组,下面是我们想要放进去的数字,可以看到我们数组的长度是7,这时候我们的哈希值就可以是我们的key%capacity,也就是拿我们的当前的值余上我们的数组长度,这样我们放的时候就不会出现数组越界的情况了,有点像我们的桶排序。

我们可以看到前面放元素的过程就是这样,现在我们想要把8也放进去然后就会发现问题,我们8所计算出来的哈希值也是2。
冲突
这时我们就发现我们想要放进去的8与我们哈希表里面的1冲突了,这种冲突不可避免,首先我们想到的就是去降低我们冲突发生的频率,想要降低冲突频率当然就是扩大我们的哈希表,也就是扩大我们的数组。
负载因子
所谓的负载因子就是我们哈希表底层的数组,已经放进去的元素/数组的长度,负载因子与我们冲突的关系如下:
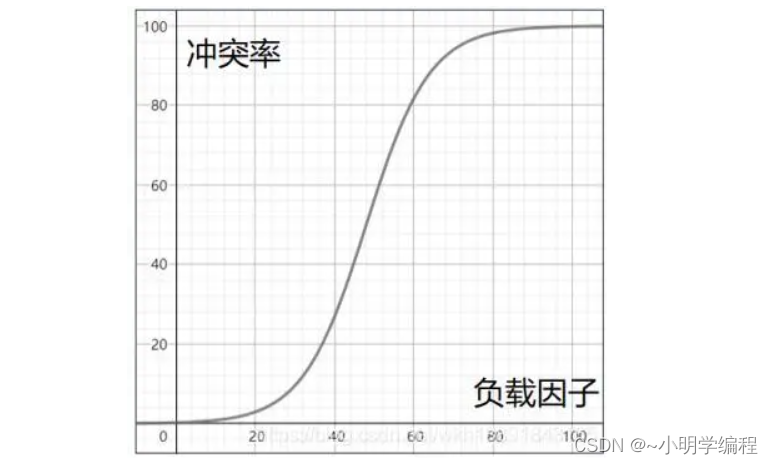
一般情况下我们的负载因子设定为0.75也就是当我们的底层数组被放了七八成的时候我们就要开始对数组进行扩容了。
这个时候也许会有疑问,我们的负载因子为什么不设置为1或者0.5呢?
这是因为当我们的负载因子设置为1的时候我们肯定已经产生大量的冲突了,这是我们所不想看到的,我们想要的是较低的冲突,那么既然我们想要较低的冲突我们为什么不将其设置为0.5呢?通过上面的图我们可以看到,但负载因子是0.5的时候我们的冲突率是很低的,确实冲突率是降低了,但是我们的数组才用了一半就要进行数组的扩容这样太浪费空间了,所以我们取中设0.75为我们的负载因子。
解决冲突
解决哈希冲突两种常见的方法是:闭散列和开散列。
闭散列
闭散列:也叫开放定址法,当我们发生冲突的时候我们的数组我们可以将发生冲突的元素放到数组中的其它空闲的位置。
对于如何去找下一个空闲的位置我们常见的有两种方法:
线性探测法:就是向当前冲突的位置一直向后找直到找到空闲的位置,但是这样做的缺点就是会导致我们冲突的元素都聚集到一起了。
二次探测:二次探测的出现就是解决我们线性探测法的问题的,其目的就是避免聚集,所以我们找空位置的方式就不再是挨着去找了,而是用一个公式找出我们的位置H(i) =( H0+i^2)%m,其中:i = 1,2,3…, 是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
开散列/哈希桶
开散列法又叫链地址法(开链法):我们将哈希表的底层数组中的每个元素都设置为一个链表,当我们产生冲突的时候就向我们的链表中插入一个新的节点,如下图: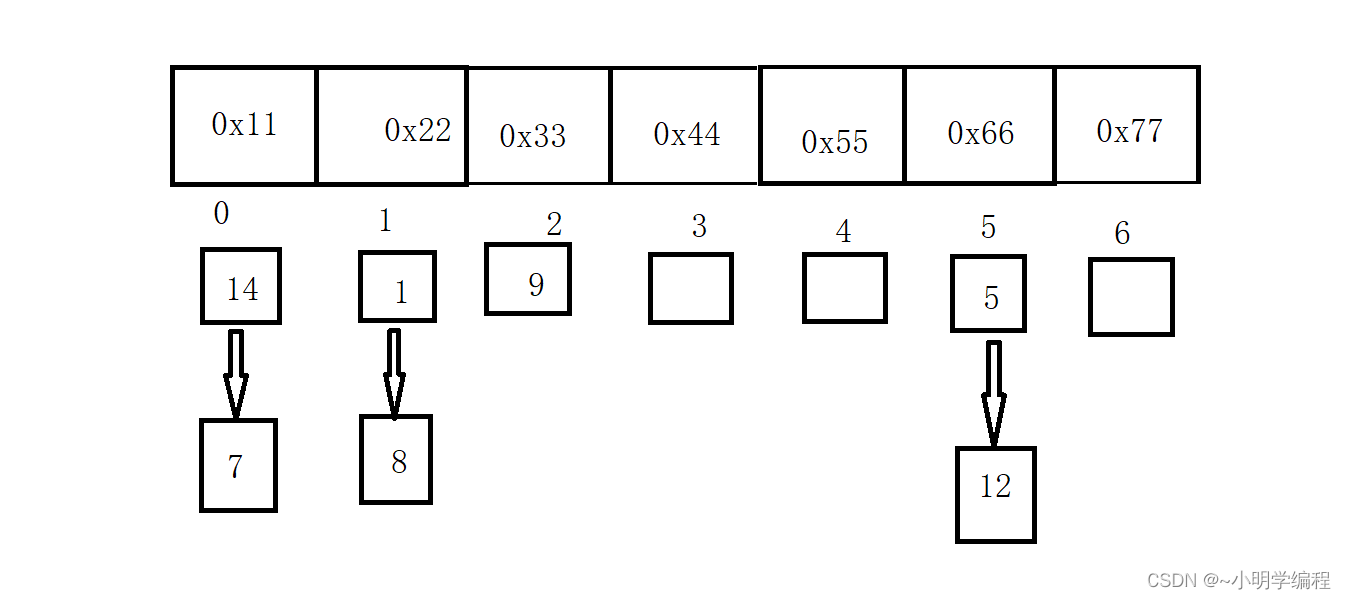
思路很简单,接下来我们就用代码来实现一下。
代码实现
不考虑泛型
首先我们就是要设置我们的链表节点:
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}我们将其定义为一个静态的内部类,里面包含我们的key值,数据域val,还有我们的下一个节点的地址next。
Node[] array;//哈希表
public int userSize = 0;//我们哈希表里面的元素个数
public static final double DEFAULT_LOAD_FACTOR = 0.75;//负载因子
public HashBuck() {
this.array = new Node[10];
}接下来就是设定我们的哈希表,设置为我们的节点类型的数组,元素个数和负载因子。
put操作
我们的put操作的功能就是向我们的哈希表中放元素,这里我们的key是整型的所以:
1.算出我们的hash值,new一个我们当前的节点。
2.通过hsah值找到我们元素在数组中的位置。
3.遍历当前链表的所有节点看看是否该key已存在,如果存在那就直接结束不用再插入了。
4.判断一下我们的负载是否超过负载因子,超过的话就需要扩容。
5.采用链表的头插法将当前节点插入哈希表中。
代码:
//放入元素的操作
public void put(int key,int val) {
int index = key% array.length;//找到我们对应的数组下标
Node node = new Node(key, val);
Node cur = array[index];//找到数组所对应链表的首地址
//首先遍历一遍链表如果key相同的话,我们要更新key的值
while (cur!=null) {
if (cur.key == key) {
cur.val = val;
return;
}
cur = cur.next;
}
//考虑扩容问题,如果我们当前的负载因子达到了阈值,就开始扩容
if (getDefaultLoadFactor()>DEFAULT_LOAD_FACTOR) {
resize();
}
//将当前的节点连接到链表上去,采用头插法
node.next = array[index];
array[index] = node;
this.userSize++;
}
//返回我们当前的负载因子
private double getDefaultLoadFactor() {
return 1.0*userSize/this.array.length;
}
//扩容操作
private void resize() {
//首先new一个新的数组
Node[] newArray = new Node[2 * array.length];
for (int i = 0; i < array.length; i++) {
Node cur = array[i];
while (cur!=null) {
Node curNext = cur.next;//记录一下我们的下一个节点防止后面插入后丢失
int index = cur.key % newArray.length;//记录当前的下标
//一样还是采用头插法
cur.next = newArray[index];
newArray[index] = cur;
cur = curNext;
}
}
this.array = newArray;
}get操作
get操作就比较简单了,获取我们的hash值,然后找到数组下标,接着遍历链表找到我们的key.
代码:
//获取操作
public int get(int key) {
int index = key % array.length;
Node cur = array[index];
while (cur!=null) {
if (cur.key==key) {
return cur.val;
}
}
return -1;
}整体代码
public class HashBuck {
//哈希表中的节点
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
Node[] array;//哈希表
public int userSize = 0;//我们哈希表里面的元素个数
public static final double DEFAULT_LOAD_FACTOR = 0.75;//负载因子
public HashBuck() {
this.array = new Node[10];
}
//放入元素的操作
public void put(int key,int val) {
int index = key% array.length;//找到我们对应的数组下标
Node node = new Node(key, val);
Node cur = array[index];//找到数组所对应链表的首地址
//首先遍历一遍链表如果key相同的话,我们要更新key的值
while (cur!=null) {
if (cur.key == key) {
cur.val = val;
return;
}
cur = cur.next;
}
//考虑扩容问题,如果我们当前的负载因子达到了阈值,就开始扩容
if (getDefaultLoadFactor()>DEFAULT_LOAD_FACTOR) {
resize();
}
//将当前的节点连接到链表上去,采用头插法
node.next = array[index];
array[index] = node;
this.userSize++;
}
//返回我们当前的负载因子
private double getDefaultLoadFactor() {
return 1.0*userSize/this.array.length;
}
//扩容操作
private void resize() {
//首先new一个新的数组
Node[] newArray = new Node[2 * array.length];
for (int i = 0; i < array.length; i++) {
Node cur = array[i];
while (cur!=null) {
Node curNext = cur.next;//记录一下我们的下一个节点防止后面插入后丢失
int index = cur.key % newArray.length;//记录当前的下标
//一样还是采用头插法
cur.next = newArray[index];
newArray[index] = cur;
cur = curNext;
}
}
this.array = newArray;
}
//获取操作
public int get(int key) {
int index = key % array.length;
Node cur = array[index];
while (cur!=null) {
if (cur.key==key) {
return cur.val;
}
}
return -1;
}
}
考虑泛型
前面我们因为我们的key值是整型所以我们在计算哈希值的时候直接用key%数组长度,那么当我们的key不是整型而是其它的类型,例如是一个String类型或者,其它应用类型时候该怎么办呢?
这时候就要用到我们的hashCode方法,该方法就是根据我们的引用来生成一个hash值,例如我们有一个Person的类。
class Person {
public int ID;
public Person(int ID) {
this.ID = ID;
}
} public static void main(String[] args) {
Person person1 = new Person(340);
Person person2 = new Person(340);
Person person3 = person1;
System.out.println(person1.hashCode());//460141958
System.out.println(person2.hashCode());//1163157884
System.out.println(person3.hashCode());//460141958
}这里我们调用hashCode的方法可以看到我们生成一个hash值,这样就解决了我们hsah值的问题了,那么问题又来了,我们new的这两个对象本质上是一样的,都是ID=340,但是其hash值却不一样,当我们想要其hash值一样的时候就需要重写其hashCode,但是在我们重写hashCode的过程中往往也要重写equals,这是为什么呢?
hashCode和equals为何要同时重写
这是因为我们的hashCode所生成的hash值在是根据对象的地址来生成就如同上述的代码,我们的person1和person2不相等(没有重写equals,此时判断是否相等比较的是地址)而person1和person3是相等的,所以我们person1和person3所生成的hash值都是一样的。
现在我们不需要根据地址来生成哈希值,因为这样没有太大的意义,我们要根据我们对象里面的成员来生成我们的hash值,比如我们的Person类,我们要根据我们的ID来生成我们想要的hash值,此时我们就要去重写hashCode了,重写完之后:
class Person {
public int ID;
public Person(int ID) {
this.ID = ID;
}
@Override
public int hashCode() {
return Objects.hash(ID);
}
} public static void main(String[] args) {
Person person1 = new Person(340);
Person person2 = new Person(340);
Person person3 = person1;
System.out.println(person1.hashCode());//371
System.out.println(person2.hashCode());//371
System.out.println(person3.hashCode());//371
}此时我们得到了我们想要的东西,hash都一样了,但是当我们向里面put元素和get元素的时候,我们就会发现问题:
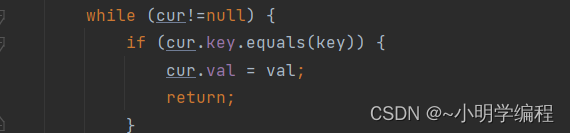
我们会发现无论是put还是get我们都会有一个equals,比较当前对象是否一致才行,如果不重写还是默认比较地址,那么既然是比较地址就行了何必重写我们的hashCode呢,我们的hash值能让我们找到我们想要的元素在数组的哪一个下标,但是每个下标下面又是一个链表(或者红黑树)所以想要找到具体的元素还需要去比较,所以就得重写equals。
代码:
public class HashBuck2<K,V> {
static class Node<K,V>{
public K key;
public V val;
public Node<K,V> next;
public Node(K key,V val){
this.key = key;
this.val = val;
}
}
public Node<K,V>[] array = (Node<K,V>[])(new Node[10]);//哈希表
public int userSize = 0;//我们哈希表里面的元素个数
public static final double DEFAULT_LOAD_FACTOR = 0.75;//负载因子
//放入元素的操作
public void put(K key,V val) {
int hash = key.hashCode();
int index = hash% array.length;//找到我们对应的数组下标
Node<K,V> node = new Node(key, val);
Node<K,V> cur = array[index];//找到数组所对应链表的首地址
//首先遍历一遍链表如果key相同的话,我们要更新key的值
while (cur!=null) {
if (cur.key.equals(key)) {
cur.val = val;
return;
}
cur = cur.next;
}
//考虑扩容问题,如果我们当前的负载因子达到了阈值,就开始扩容
if (getDefaultLoadFactor()>DEFAULT_LOAD_FACTOR) {
resize();
}
//将当前的节点连接到链表上去,采用头插法
node.next = array[index];
array[index] = node;
this.userSize++;
}
//返回我们当前的负载因子
private double getDefaultLoadFactor() {
return 1.0*userSize/this.array.length;
}
//扩容操作
private void resize() {
//首先new一个新的数组
Node<K,V>[] newArray = new Node[2 * array.length];
for (int i = 0; i < array.length; i++) {
Node<K,V> cur = array[i];
while (cur!=null) {
Node<K,V> curNext = cur.next;//记录一下我们的下一个节点防止后面插入后丢失
int hash = cur.key.hashCode();
int index = hash % newArray.length;//记录当前的下标
//一样还是采用头插法
cur.next = newArray[index];
newArray[index] = cur;
cur = curNext;
}
}
this.array = newArray;
}
//获取操作
public V get(K key) {
int hash = key.hashCode();
int index = hash % array.length;
Node<K,V> cur = array[index];
while (cur!=null) {
if (cur.key.equals(key)) {
return cur.val;
}
}
return null;
}
}


![[附源码]计算机毕业设计基于SpringBoot的校园报修平台](https://img-blog.csdnimg.cn/4db374525d9f4ba593911464638dc7e7.png)
![[附源码]Python计算机毕业设计Django人员信息管理](https://img-blog.csdnimg.cn/e965403684be41da973c2f2958a79c77.png)