“TipDM大数据挖掘建模平台”(以下简称平台)是由广东泰迪智能科技股份有限公司自主研发,基于Python引擎的数据挖掘建模平台。使用平台配置的开箱即用的算法组件,用户可在没有编程基础的情况下,通过拖拽的方式进行操作,将数据输入输出、数据预处理、挖掘建模等环节通过流程化的方式进行连接,帮助用户快速建立数据挖掘工程,提升数据处理的效能。目前已经广泛运用在南方电网、中国电力科学研究院、珠江数码、北京智慧信访、中国石油勘探研究院、轻工业环境保护研究所、交通运输部公路科学研究所等众多企事业单位。平台的界面如图1所示。
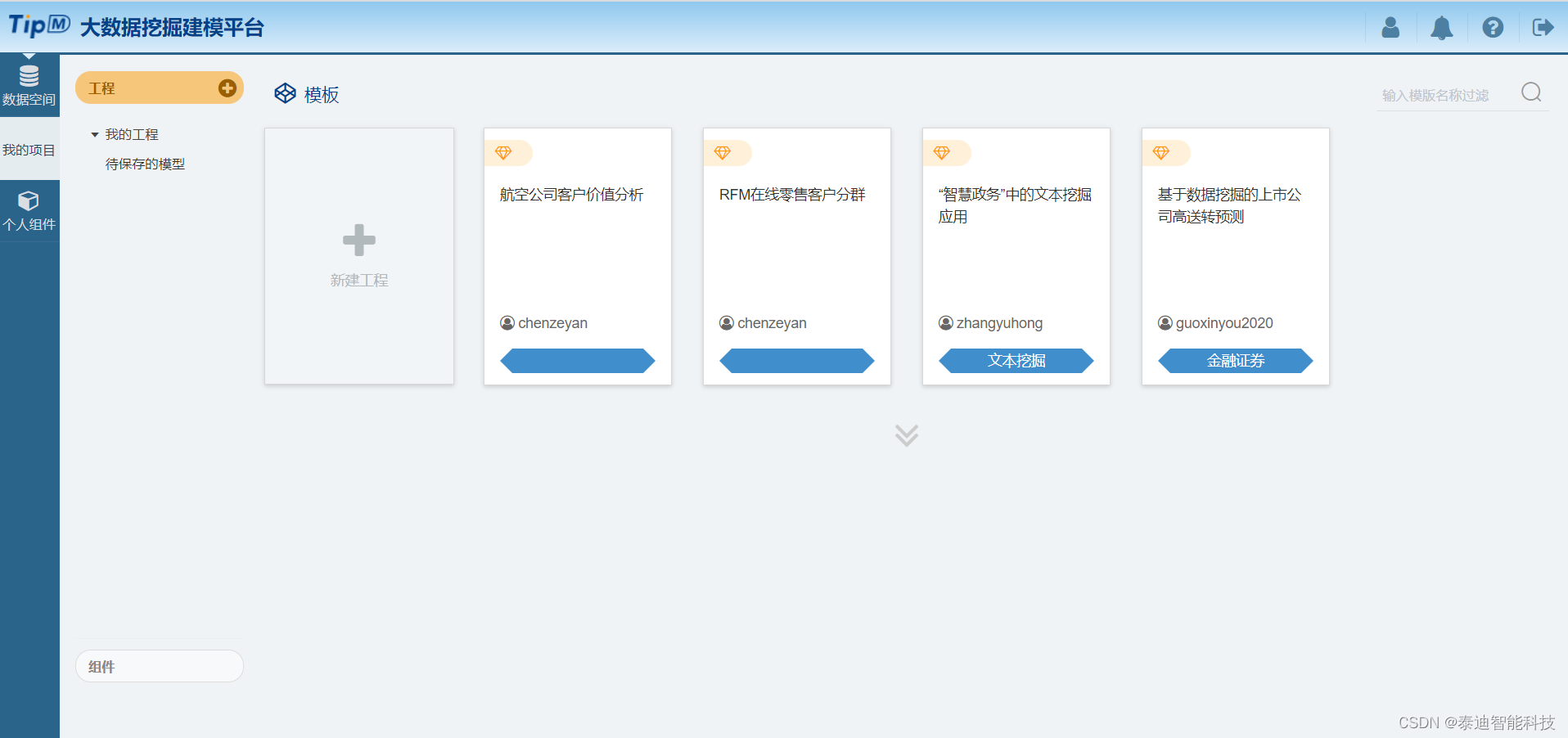
图1 平台界面图
平台简介
TipDM大数据挖掘建模平台主要有以下几个特点。
(1)平台算法基于Python引擎,用于数据挖掘建模。Python是目前最为流行的用于数据挖掘建模的语言之一,高度契合使用需求。
(2)用户可在没有Python编程基础的情况下,使用直观的可视化图形界面,通过拖拽的方式构建数据挖掘流程,无需编程。
(3)提供公开可用的数据挖掘示例工程,一键创建,快速运行。支持挖掘流程每个节点的结果在线预览。提供实时日志查看功能,出现问题快速定位。
(4)提供八大类数十种算法组件,包括数据预处理、统计分析、分类、聚类、文本分析等常用数据挖掘算法。同时提供Python脚本,粘贴代码即可运行。
平台主要分为数据空间、我的项目、算法组件三个模块。
数据空间
【数据空间】主要用于数据集的导入与管理,用户可从本地将任意类型的数据导入到平台中使用,如图2所示。同时,还可以选择是否将数据作为公共数据集进行上传,分享给其他用户使用,如图3所示。
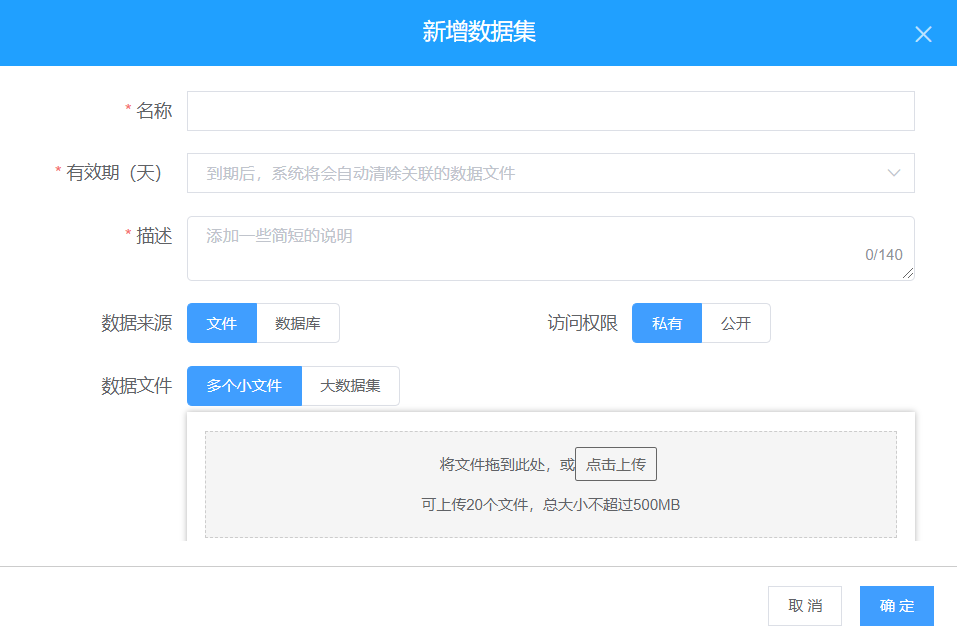
图2 新增数据集
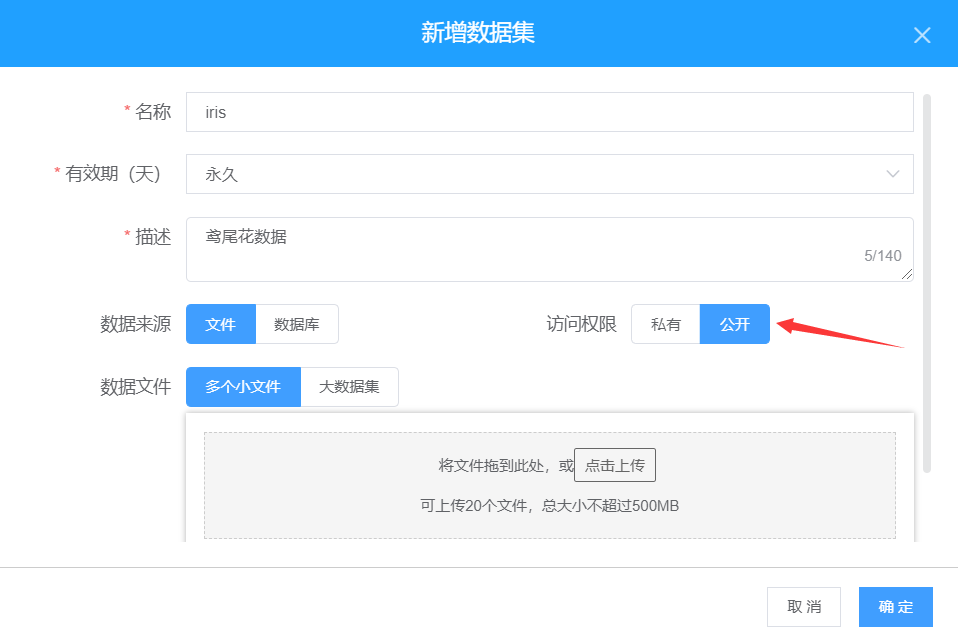
图3 上传公共数据集
我的项目
【我的项目】主要用于数据挖掘流程化的创建与管理。通过【我的项目】模块,能够创建空白的工程,进行数据挖掘流程的配置,如图4所示。对于完成度优秀的工程,可以将其保存为模板,如图5所示,其他用户可通过模板创建已配置好算法的数据挖掘工程,一键运行。

图4 工程

图5 模板
算法组件
在平台中,每一个数据挖掘算法都可称之为一个组件。【算法组件】主要分为系统算法组件和个人算法组件两部分。系统算法组件是由平台提供的默认算法,用户无需编辑,可直接在工程中使用。个人算法组件是在系统算法组件无法满足使用的情况下,用户可使用Python编写个人算法组件,供本用户使用。
系统算法组件包括输入、统计分析、预处理、脚本组件、聚类、分类、回归、文本分析,共八大类,如图6所示。
(1) 【输入/输出】提供配置数据挖掘工程的输入组件,包括:输入源。
(2) 【统计分析】提供对数据整体情况进行统计的常用组件,包括:相关性分析、正态性检验、主成分分析、全表统计、平稳性检验、因子分析、卡方检验。
(3) 【预处理】提供对数据进行清洗的组件,包括:主键合并、表堆叠、记录去重、新增序列、数据标准化、数据拆分、频数统计、衍生变量、缺失值处理、数据排序、分组聚合。
(4)【脚本组件】:提供一个代码编辑框,用户可以在代码编辑框中粘贴已经写好的程序代码,直接运行,无需再额外配置成组件,包括:Python脚本。
(5) 【分类】提供常用的分类算法组件,包括:CART分类树、K最近邻、朴素贝叶斯、支持向量机、逻辑回归、Adaboost、随机森林。
(6) 【聚类】提供常用的聚类算法组件,包括:层次聚类、DBSCAN密度聚类、K-Means聚类、K-中心点聚类、模糊聚类。
(7) 【回归】提供常用的回归算法组件,包括:CART回归树、线性回归、支持向量回归、K最近邻回归。
(8) 【文本分析】提供常用的文本分析算法组件,包括:HanLP分词与词性、长短期记忆网络训练、过滤停用词、word2vec、结巴提取、正则匹配、基于词向量/文档向量、TextRank等。
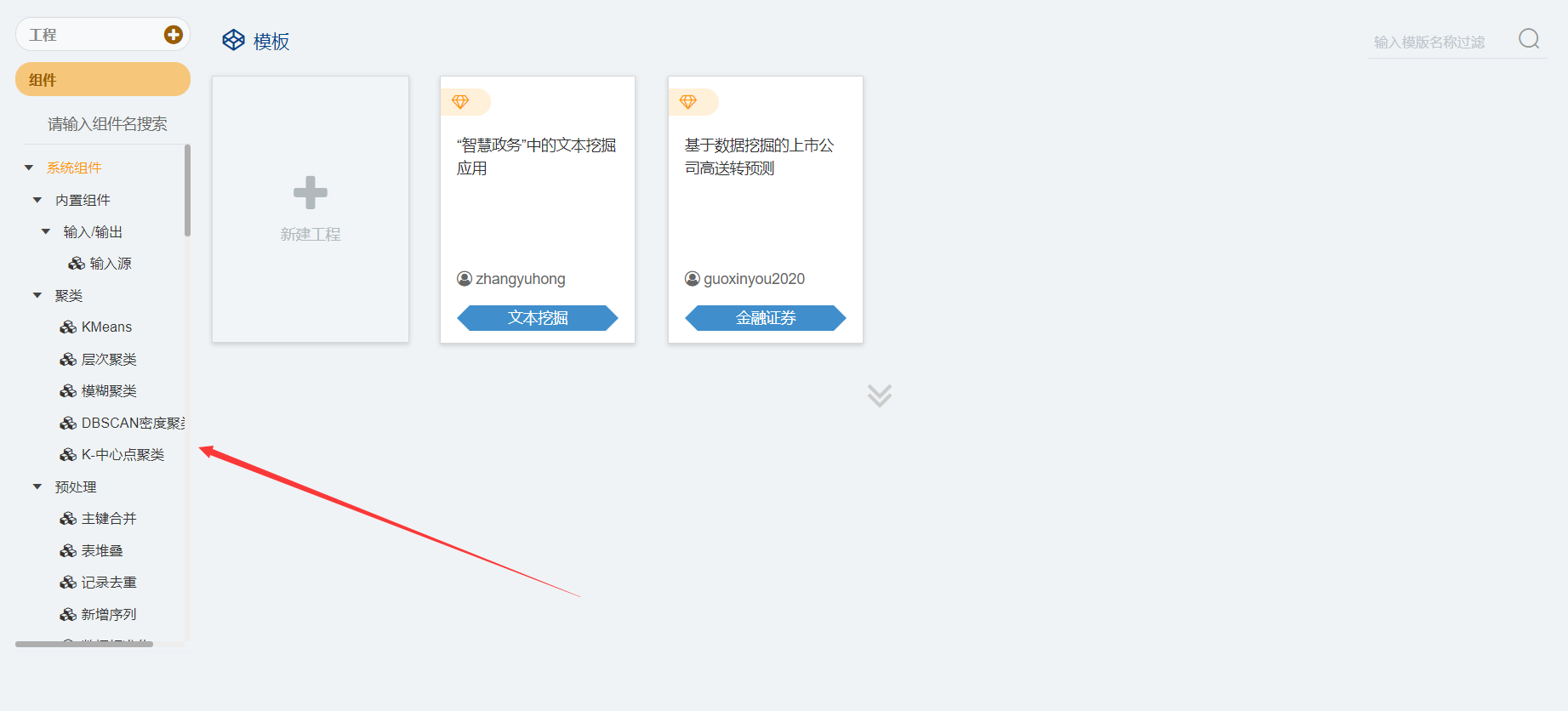
图6 系统组件算法

图7 个人组件算法
接下来给大家秀把操作,使用平台构建一个鸢尾花聚类工程。

图8 上传数据

图9 创建工程
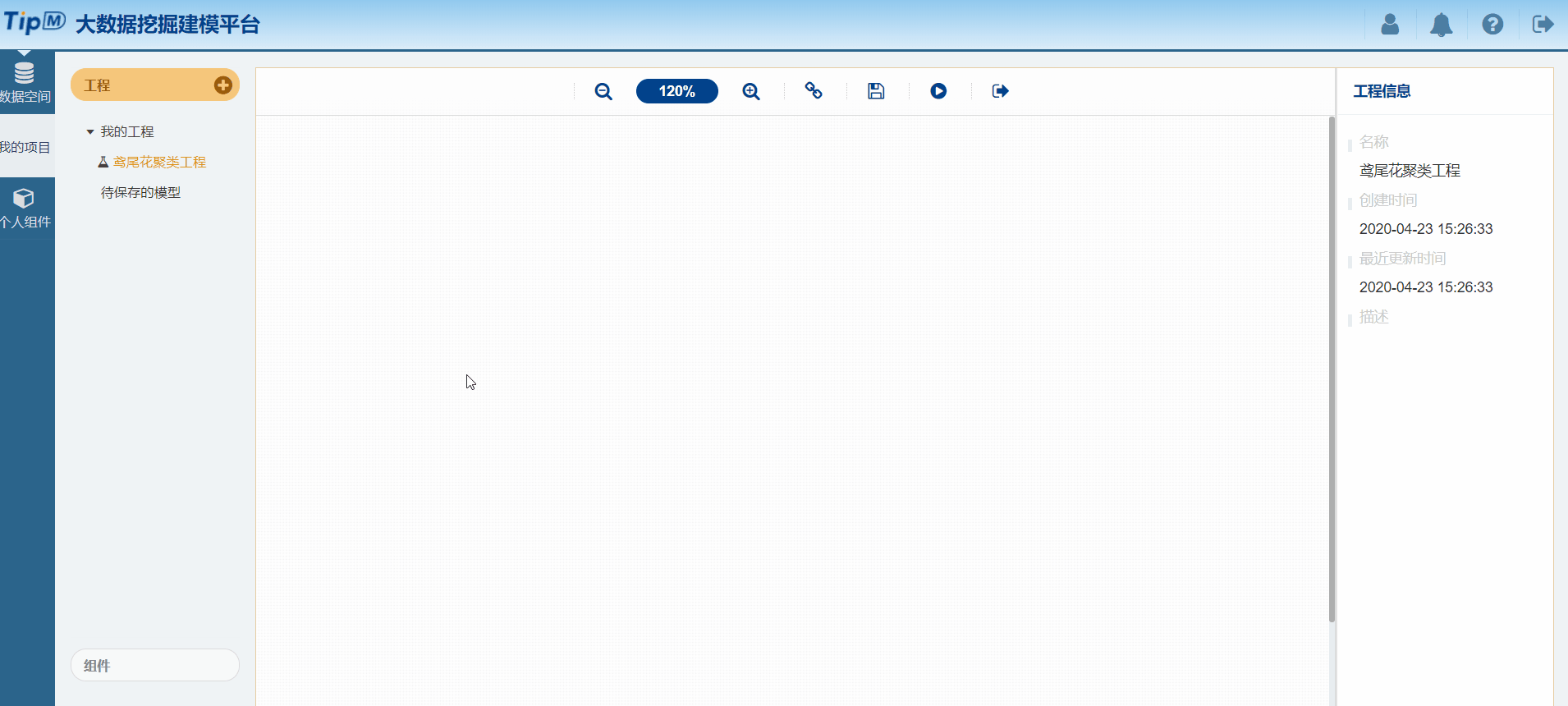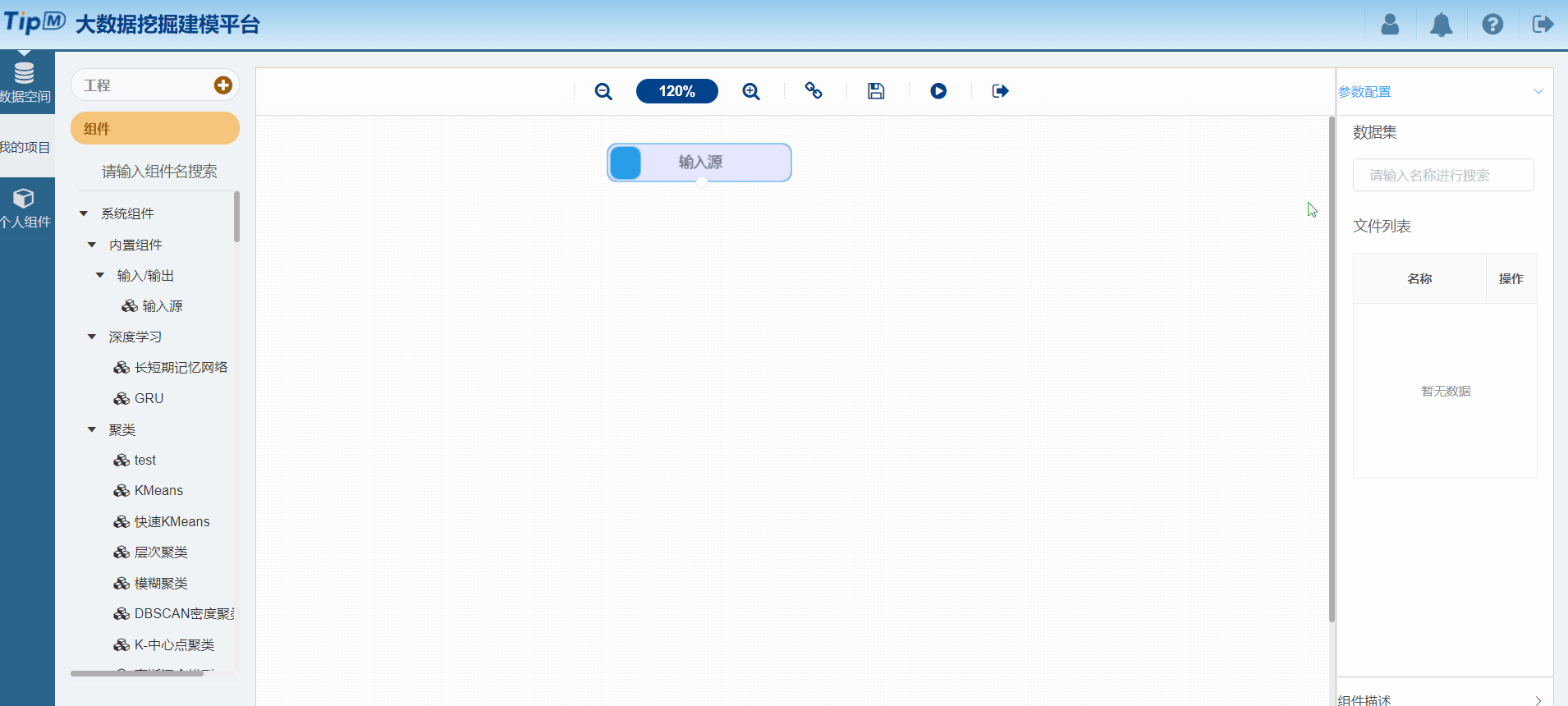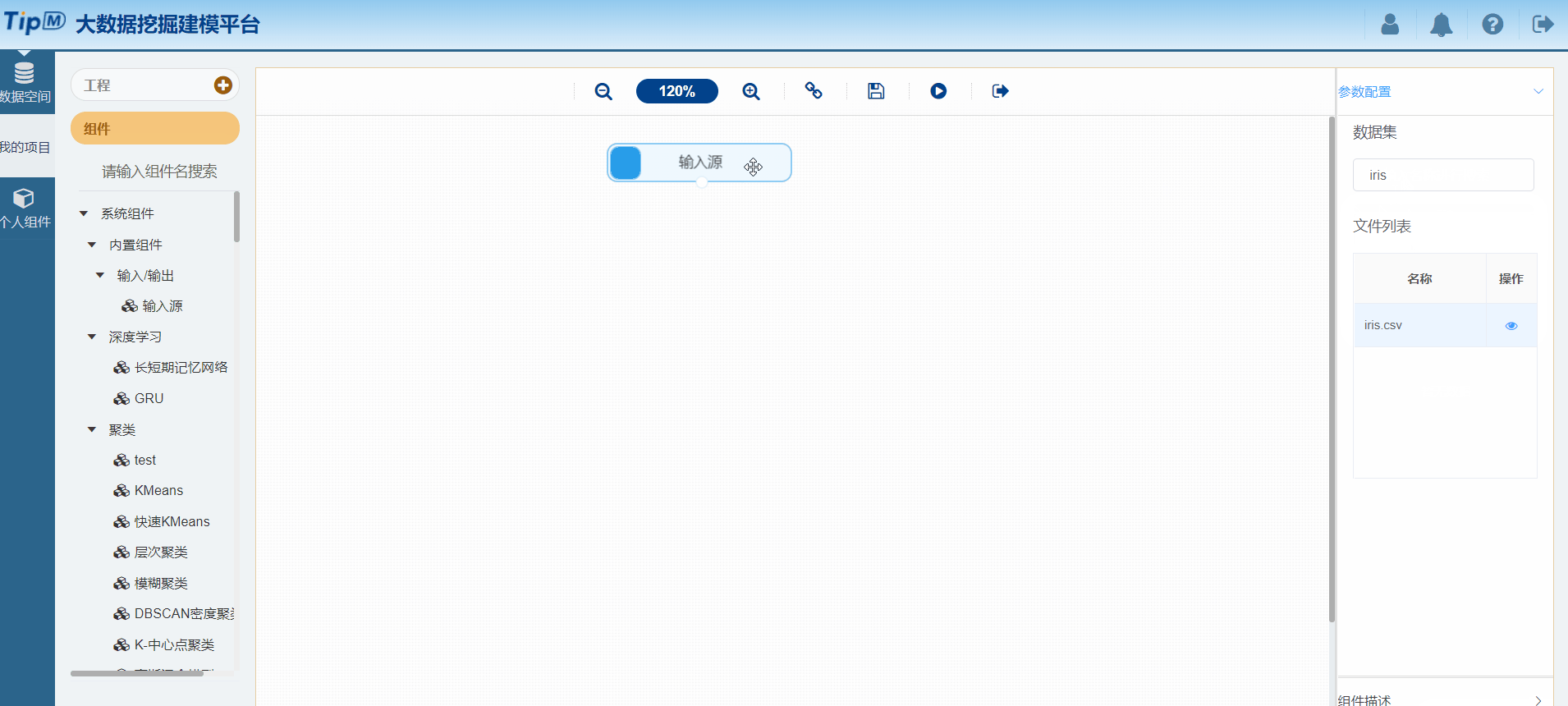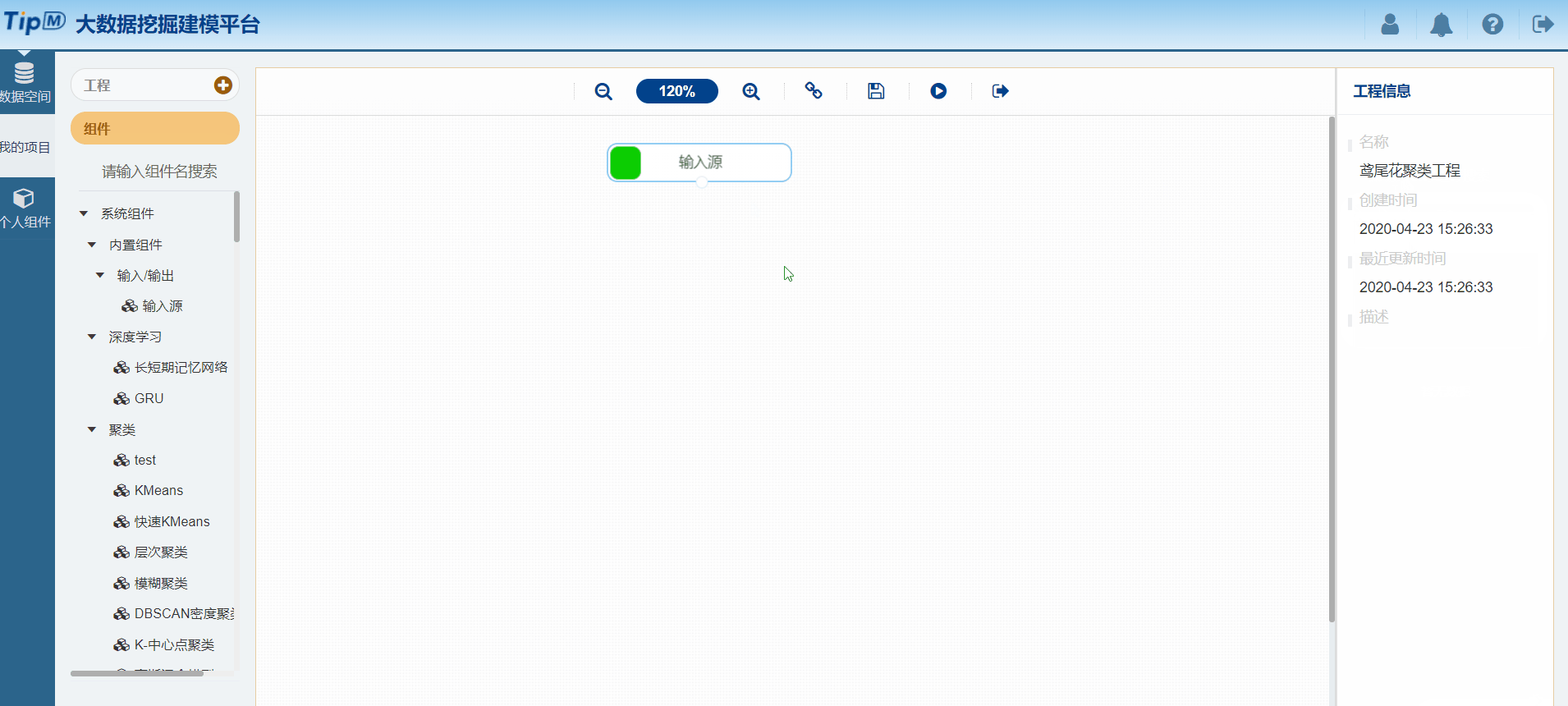
图10 配置输入源组件
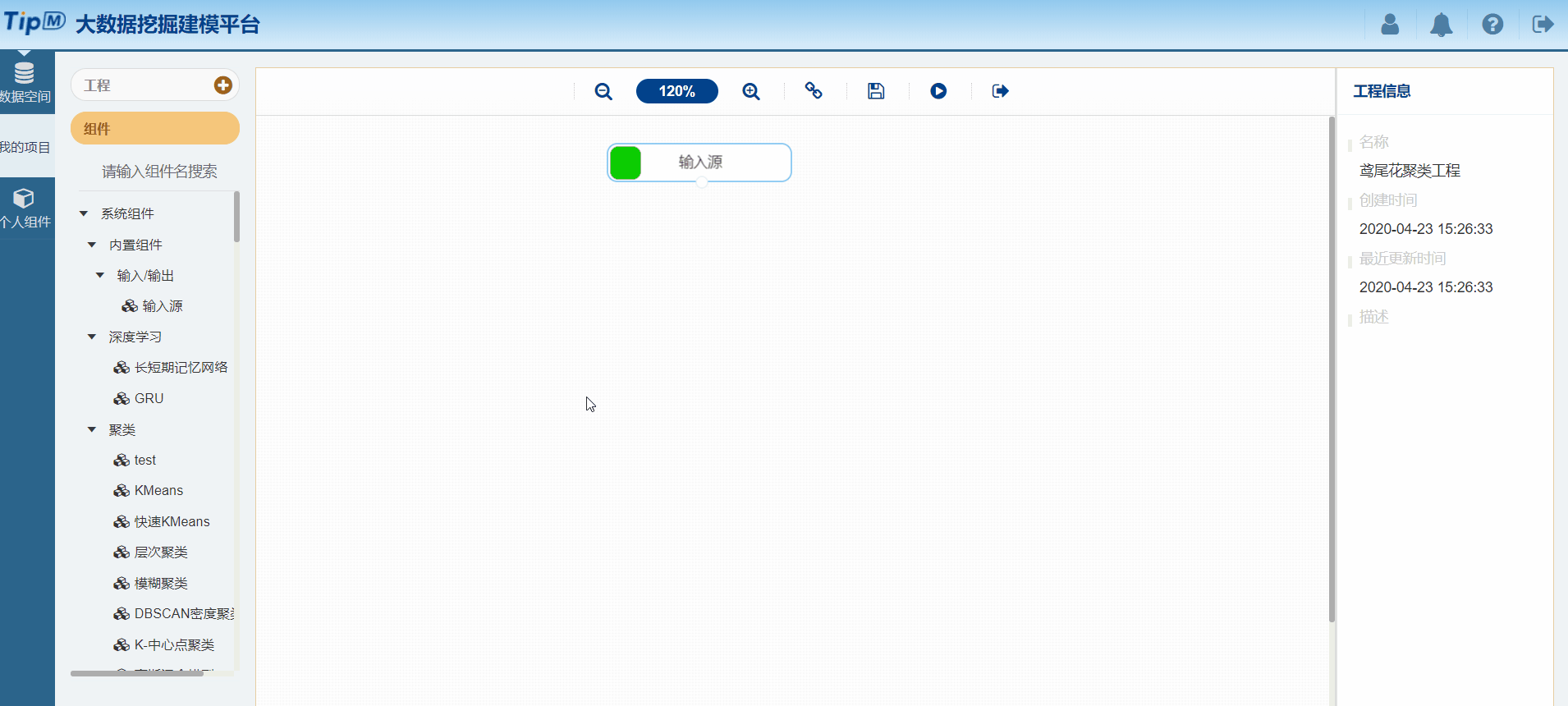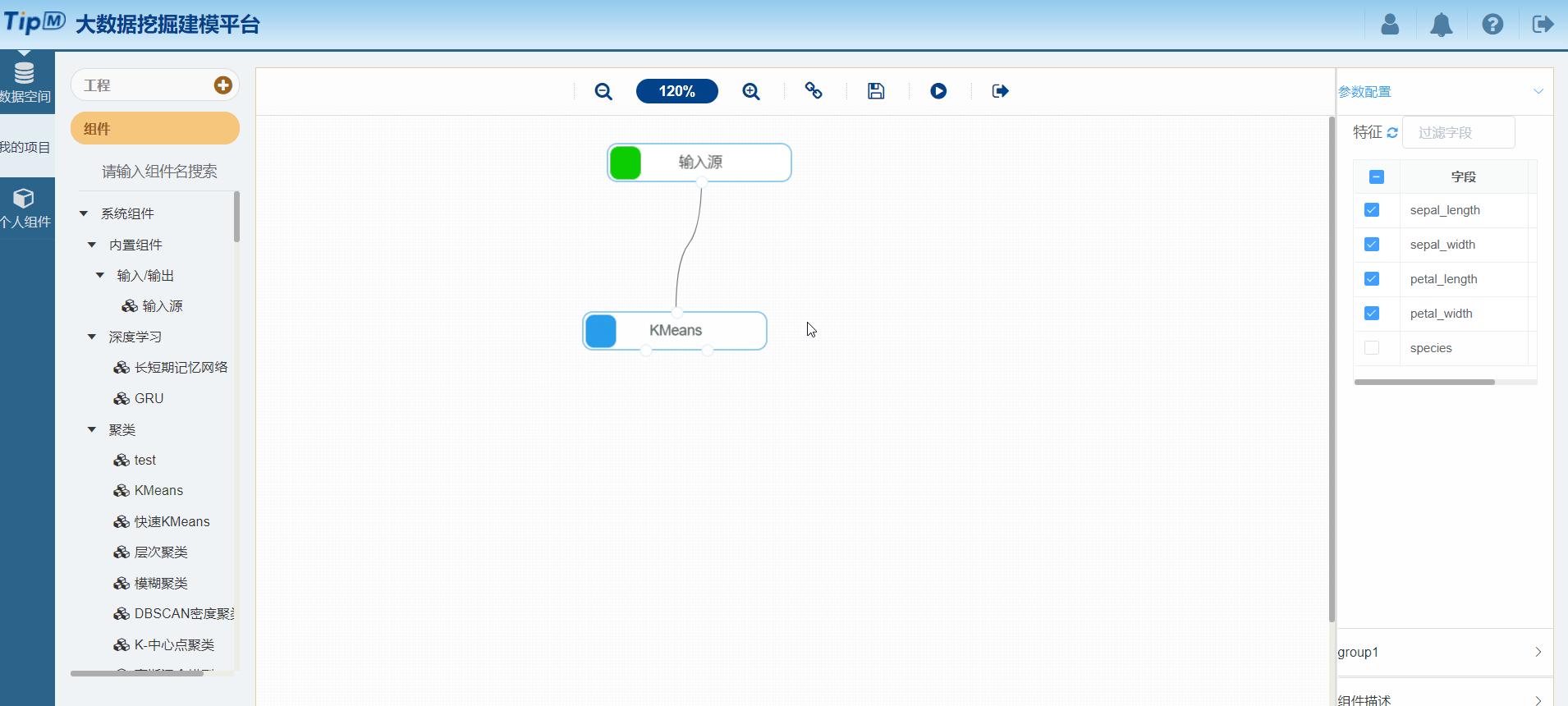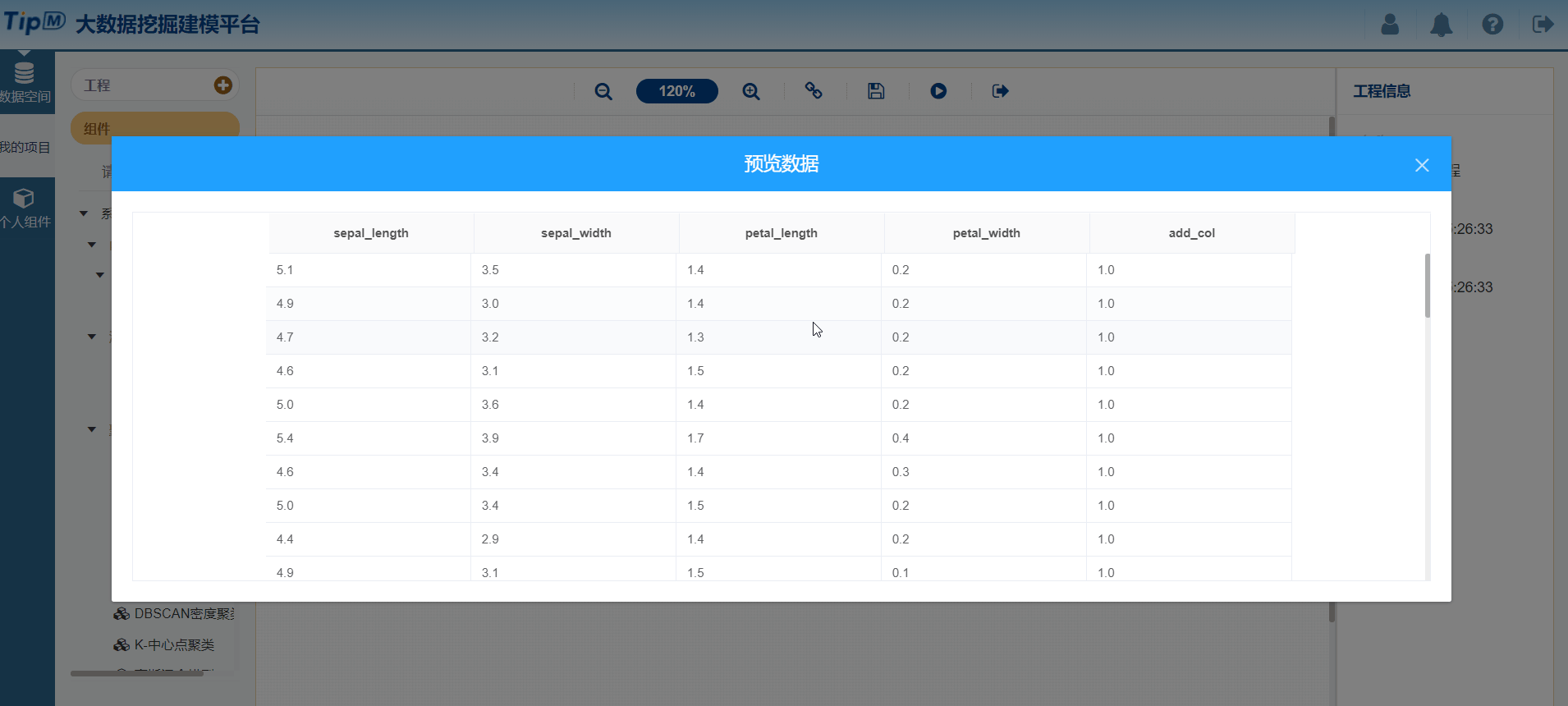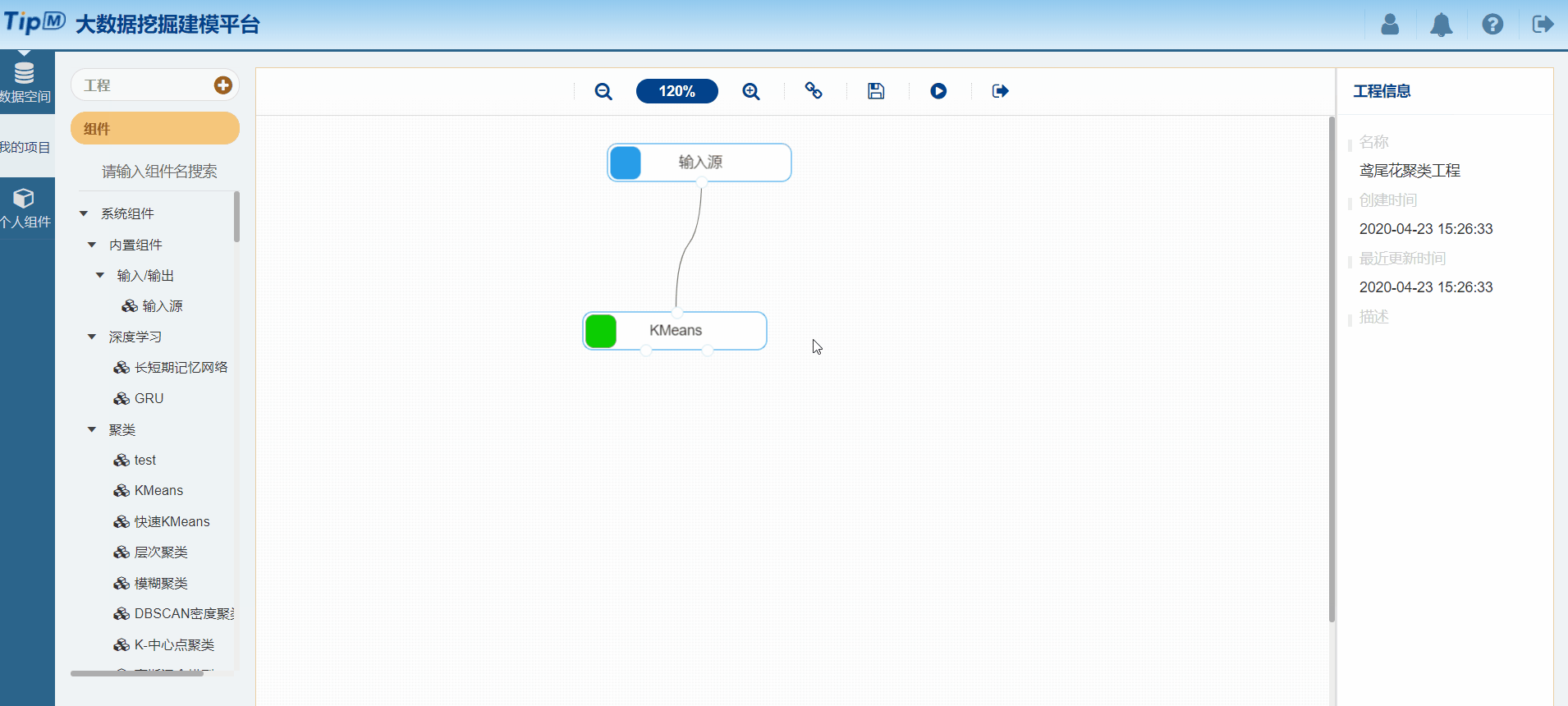
图11 配置KMeans组件