文章目录
- 一. 问题描述
- 二. 解决方案
- 三. 一些拓展
一. 问题描述
最近在使用StarRocks的时候,发现一个问题
table_a 10W 左右数据,通过where条件过滤数据后 剩下 10行数据。
table_b 5亿左右数据,通过where过滤条件后 剩下 5kw 数据。
table_a 通过关联字段 与 table_b 进行join,然后再进行group by
table_b join后其实只剩下少量的数据,进行聚合运算,应该也不会太慢。
但是实际情况是 table_b 居然是扫描了 5kw数据后,在于table_a 进行join,每次执行消耗的资源非常大
原始SQL:
with t1 as
(
select key1, value1
from table_a
order by value1 desc
limit 10
),
t2 as
(
select key2,value2,value3,value4
from table_b
where value2 > 100
)
select t1.key1,
sum(t2.value3),
sum(t2.value4)
from t2
join t1
on t1.key1 = t2.key2
group by t1.key1;
运行情况:
扫描数据量: 5千万
执行时间: 15秒
二. 解决方案
通过explain查看了执行计划,发现了table_b 访问的行数太多了
因为explain里面的计划有时候存在偏差,所以还是开启了一个query profile,看到访问的数据量
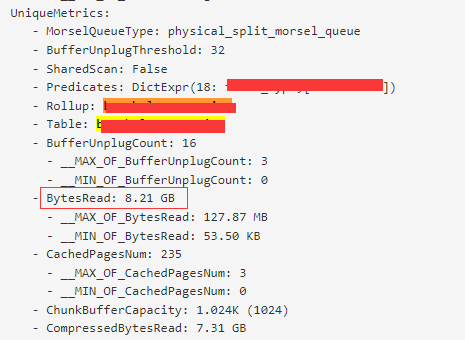
调优SQL:
with t1 as
(
select key1, value1
from table_a
order by value1 desc
limit 10
),
t2 as
(
select key2,value2,value3,value4
from table_b
where value2 > 100
)
select t1.key1,
sum(t2.value3),
sum(t2.value4)
from t2
join [broadcast] t1
on t1.key1 = t2.key2
group by t1.key1;
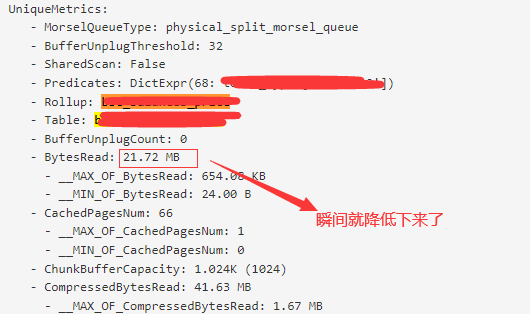
三. 一些拓展
Join分布式执行选择 :
- BroadCast Join:将右表全量发送到左表的HashJoinNode
- Shuffle Join:将左右表的数据根据哈希计算分散到集群的节点之中
- Colocate Join:两个表的数据分布都是一样的,只需要本地join即可,没有网络传输开销。
- Bucket Shuffle Join:join的列是左表的数据分布列(分桶键),所以相比于shuffle join只需要将右表的数据发送到左表数据存储计算节点。
- Replicated Join:右表的全量数据是分布在每个节点上的(也就是副本个数和BE节点数量一致),不管左表怎么分布,都是走本地Join。没有网络传输开销。