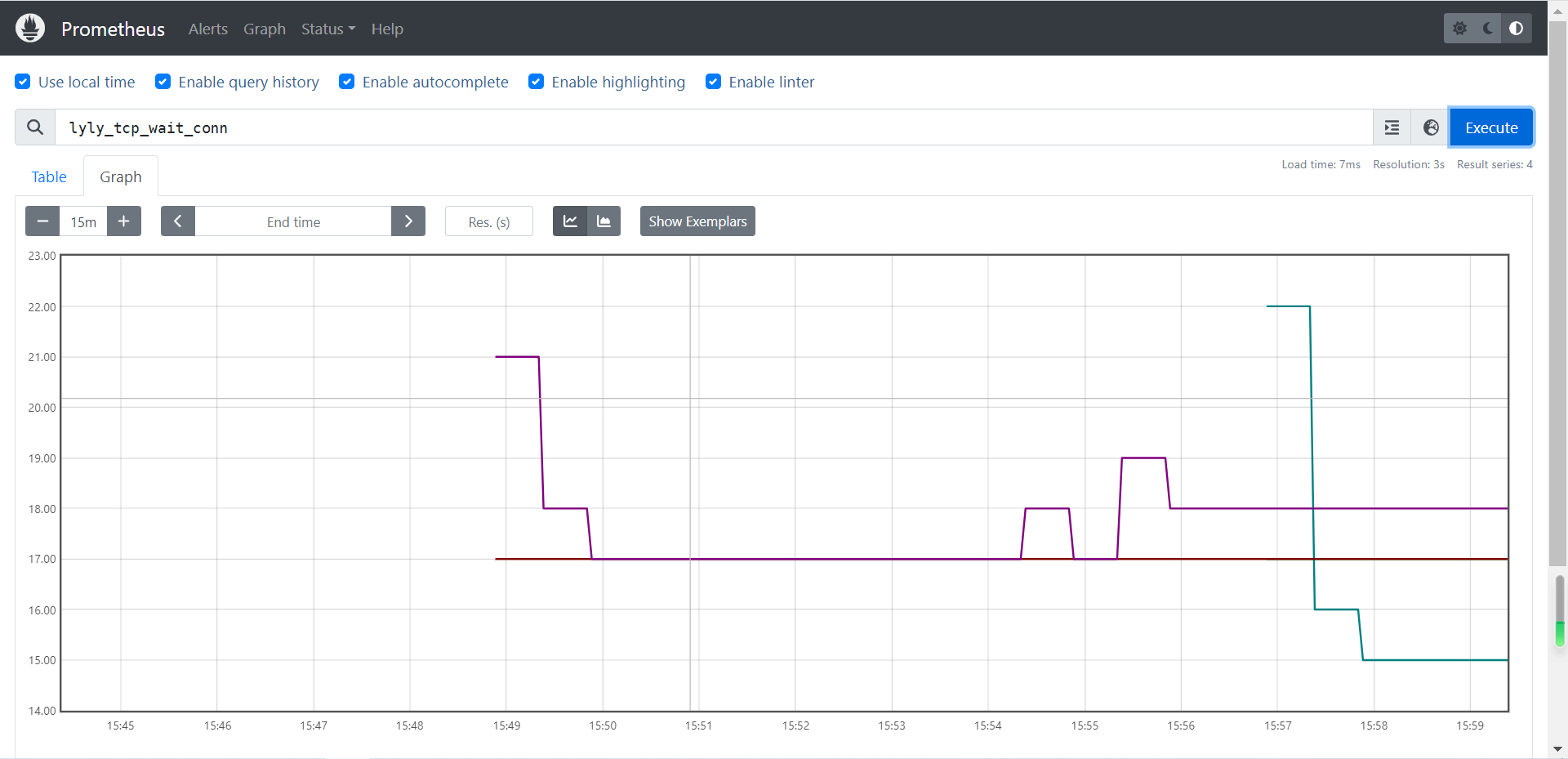
Redis数据类型之(哈希Hash和集合Set)
一定注意看红色注意项。
哈希(Hash):
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
特征:提到hash首先想到Java语言中的hashMap,他的结构也是key-value结构(下面就用字段名和值表示hash里面的key value)。这就相当于redis的里面可以存一个key - (key-value),这有点像json了,只不过就2层。如果有一个用户,他有姓名、年龄、地址等信息。在redis中就可以用hash类型来存储。下面是hash的使用命令。
由于他是string类型的一个映射表,所以他的命令基本都是H开头的String命令:如下
-
Hset:field相当于字段名,value是值
HSET key field value
将哈希表 key 中的字段 field 的值设为 value 。 -
Hget:
HGET key field
获取存储在哈希表中指定字段的值。 -
Hmset:设置多对字段名和值,成对出现。
HMSET key field1 value1 [field2 value2 ]
同时将多个 field-value (域-值)对设置到哈希表 key 中。 -
Hmget:获取多个字段值
HMGET key field1 [field2]
获取所有给定字段的值 -
Hkeys:获取key 中的所有字段名
HKEYS key
获取哈希表中的所有字段 -
Hvals:获取key 中的所有值
HVALS key
获取哈希表中所有值。 -
Hlen:获取key中的字段数量
HLEN key
获取哈希表中字段的数量 -
Hgetall:获取key中的字段名和值,都输出
HGETALL key
获取在哈希表中指定 key 的所有字段和值 -
Hexists:字段名是否存在
HEXISTS key field
查看哈希表 key 中,指定的字段是否存在。 -
Hdel:删除多个字段
HDEL key field1 [field2]
删除一个或多个哈希表字段 -
Hincrby:可以给字段中的数值增加,比如age:18。可以增加age的值1。1就是加1,如果写-1就是减一,不需要再多加一个减法命令。
HINCRBY key field increment
为哈希表 key 中的指定字段的整数值加上增量 increment 。 -
Hincrbyfloat:上面提到整数增减了,这个是浮点数增减,比如:0.5 就是加0.5,-0.5就是减0.5。
注意:如果用浮点型命令加0.5后,就只能使用浮点命令操作了,因为他就变成了浮点型。若果用浮点型给一个整数增加了1,则还可以用整数型命令继续操作,因为数值还是整数。
HINCRBYFLOAT key field increment
为哈希表 key 中的指定字段的浮点数值加上增量 increment 。

-
Hsetnx:如果该字段不存在时,设置该字段值
HSETNX key field value
只有在字段 field 不存在时,设置哈希表字段的值。
实操:
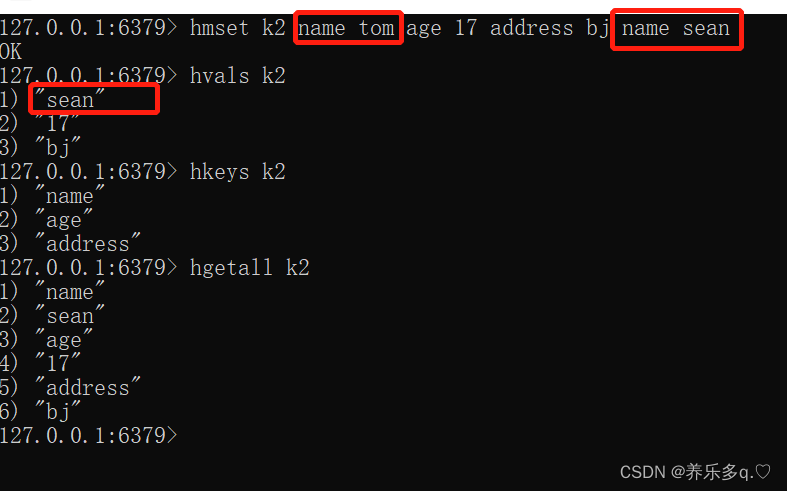
这里可以看到我用hmset设置了多组属性,并且设置了两次name。最终查询结果表示name被最后一个设置覆盖了,所以可以说明他具有hashmap的特征,去重。
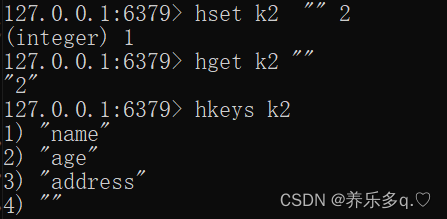
这里也支持设置一个空字符串。和hashmap一样。
哈希(Hash)的使用场景:
由于他可以对字段进行数值计算。所以可以在点赞,收藏场景使用,巨鹿用户点赞数,然后每点一次就+1,取消-1,收藏同样。因为他还是key-value结构,用来存储详情页信息等。
- 点赞
- 收藏
- 存储详情页信息
集合(Set):
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
集合对象的编码可以是 intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
特征:他和Java语言中的set一样,所以具有set的特征。无序和去重
他的命令基本都是S开头:如下
- Sadd:member1 是值。如果设置多个同样的值,会自动去重
SADD key member1 [member2]
向集合添加一个或多个成员 - Scard:返回集合的成员数量有几个
SCARD key
获取集合的成员数 - Smembers:返回集合中具体的成员
SMEMBERS key
返回集合中的所有成员 - Srem:删除元素。
因为他是无序,所以只能增删,不能改
SREM key member1 [member2]
移除集合中一个或多个成员
下面介绍一下他的交、并、差集,应用多
-
Sinter:返回他们的交集。
SINTER key1 [key2]
返回给定所有集合的交集 -
SinsterStore:把他们交集返回并存储在destination 中。
写的时候可以都小写,我只是为了看着清晰,才驼峰写法
SINTERSTORE destination key1 [key2]
返回给定所有集合的交集并存储在 destination 中 -
Sunion:返回他们的并集。
SUNION key1 [key2]
返回所有给定集合的并集 -
SunionStore:把他们并集返回并存储在destination 中。
SUNIONSTORE destination key1 [key2]
所有给定集合的并集存储在 destination 集合中 -
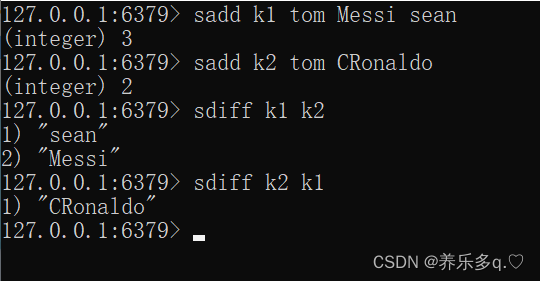
Sdiff:返回他们的差集。**
这里需要注意,key1和key2的顺序。key1在前表示返回key1中key2没有的数据,反之则返回key2中key1没有的数据。下面会提到他的具体用处
SDIFF key1 [key2]
返回第一个集合与其他集合之间的差异。
-
SdiffStore:把他们差集返回并存储在destination 中。
SDIFFSTORE destination key1 [key2]
返回给定所有集合的差集并存储在 destination 中 -
Smove:
SMOVE source destination member
将 member 元素从 source 集合移动到 destination 集合 -
Spop:随机移除一个 。
可以用到抽奖上,抽完且不放回
SPOP key
移除并返回集合中的一个随机元素 -
Srandmember:返回一个或多个随机数。
可以用到抽奖可重复中,因为不删除
SRANDMEMBER key [count]
返回集合中一个或多个随机数 -
SisMember:判断元素是否存在
SISMEMBER key member
判断 member 元素是否是集合 key 的成员
集合(Set)的使用场景:
由于他可以进行交并差集运算。所以可以在点赞,收藏场景使用,巨鹿用户点赞数,然后每点一次就+1,取消-1,收藏同样。因为他还是key-value结构,用来存储详情页信息等。
-
抽奖:
A:只抽1次,1次抽n个人。
B:抽多次,比如三等奖抽3名,二等奖抽2名,一等奖抽1名。
主要利用Set结构元素的不重复性和获取随机数的方法来实现 -
微博、微信点赞(文章的收藏)
微信朋友圈用户A的某条消息的点赞功能,要实现点赞、取消点赞、获取点赞列表、获取点赞用户数量、判断某用户是否点赞过。
A:点赞 sadd方法B:取消点赞 srem方法
C:获取点赞列表 smembers方法
D:获取点赞用户数量 scard方法
E:判断某用户是否点赞过 sIsMember方法
-
关注模型
比如微博关注或者共同好友的问题,以微博关注为例,要实现:同时关注、关注的和、关注A的用户中也关注B的、当A进入B页面,求可能认识的人。A:关注和取消关注: sadd方法 和 srem方法
B:同时关注:求交集
C:关注的和:求并集
D:关注A的用户中也有关注B的
注意这里不是取交集,而是在A的用户中判断,是否有关注B的,所以要遍历一遍A的用户:遍历A中的用户,利用sIsMember判断是否也关注BE:当A进入B页面,求可能认识的人:这里指的是关注B中的用户 扣去 里面也关注A的用户,就是A可能认识的人。
注意:这里的A和B求差集是有顺序的,比如求A的可能认识的人,就要把B放在A前面:Sdiff B A。仔细思考下是不是这样,要求A的可能认识人,就相当于求B中没有在A中出现的人。反之就是Sdiff A B。
求差集:B-A,A-B