1、 前言
你好呀,我是歪歪。
今天我带大家来卷一下时间轮吧,这个玩意其实还是挺实用的。
常见于各种框架之中,偶现于面试环节,理解起来稍微有点难度,但是知道原理之后也就觉得:

大多数人谈到时间轮的时候都会从 netty 开始聊。
我就不一样了,我想从 Dubbo 里面开始讲,毕竟我第一次接触到时间轮其实是在 Dubbo 里面,当时就惊艳到我了。
而且,Dubbo 的时间轮也是从 Netty 的源码里面拿出来的,基本一模一样。
时间轮在 Dubbo 里面有好几次使用,比如心跳包的发送、请求调用超时时间的检测、还有集群容错策略里面。
我就从 Dubbo 里面这个类说起吧:
org.apache.dubbo.rpc.cluster.support.FailbackClusterInvoker
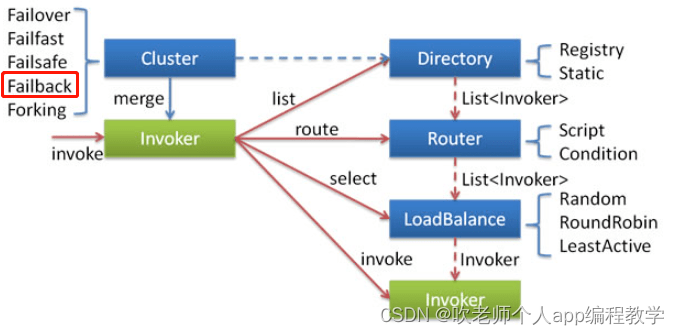
你不了解 Dubbo 也没有关系,你只需要知官网上是这样介绍它的就行了:
我想突出的点在于“ 定时重发”这四个字。
我们先不去看源码,提到定时重发的时候,你想到了什么东西?
是不是想到了定时任务?
那么怎么去实现定时任务呢?
大家一般都能想到 JDK 里面提供的 ScheduledExecutorService 和 Timer 这两个类。
Timer 就不多说了,性能不够高,现在已经不建议使用这个东西。
ScheduledExecutorService 用的还是相对比较多的,它主要有三个类型的方法:
简单说一下 scheduleAtFixedRate 和 scheduleWithFixedDelay 这两个方法。
ScheduleAtFixedRate,是每次执行时间为上一次任务开始起向后推一个时间间隔。
ScheduleWithFixedDelay,是每次执行时间为上一次任务结束起向后推一个时间间隔。
前者强调的是上一个任务的开始时间,后者强调的是上一个任务的结束时间。
你也可以理解为 ScheduleAtFixedRate 是基于固定时间间隔进行任务调度,而 ScheduleWithFixedDelay 取决于每次任务执行的时间长短,是基于不固定时间间隔进行任务调度。
所以,如果是我们要基于 ScheduledExecutorService 来实现前面说的定时重发功能,我觉得是用 ScheduleWithFixedDelay 好一点,含义为前一次重试完成后才应该隔一段时间进行下一次重试。
让整个重试功能串行化起来。
那么 Dubbo 到底是怎么实现这个定时重试的需求的呢?
撸源码啊,源码之下无秘密。
准备发车。

撸源码
有的同学看到这里可能着急了:不是说讲时间轮吗,怎么又开始撸源码了呀?
你别猴急呀,我这不得循序渐进嘛。
我先带你手撕一波 Dubbo 的源码,让你知道源码这样写的问题是啥,然后我再说解决方案嘛。
再说了,我直接,啪的一下,把解决方案扔你脸上,你也接受不了啊。
我喜欢温柔一点的教学方式。

好了,先看下面的源码。
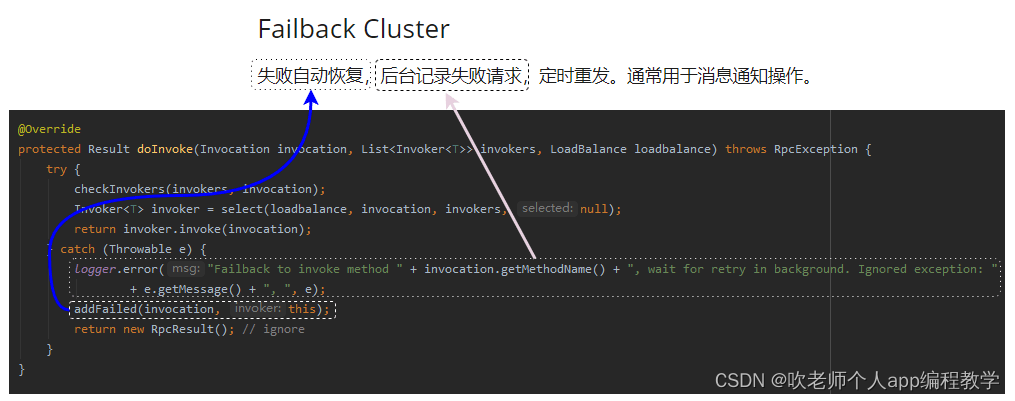
这几行代码你要是没看明白没有关系,你主要关注 catch 里面的逻辑。
我把代码和官网上的介绍帮你对应了一下。
意思就是调用失败了,还有一个 addFailed 来兜底。
addFailed 是干了啥事呢?
干的就是“定时重发”这事:
org.apache.dubbo.rpc.cluster.support.FailbackClusterInvoker#addFailed
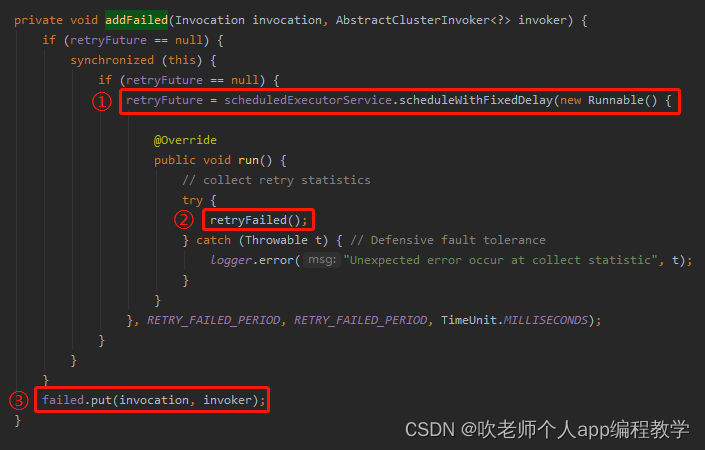
这个方法就可以回答前面我们提出的问题:Dubbo 集群容错里面,到底是怎么实现这个定时重试的需求的呢?
从标号为 ① 的地方可以知道,用的就是 ScheduledExecutorService,具体一点就是用的 scheduleWithFixedDelay 方法。
再具体一点就是如果集群容错采用的是 failback 策略,那么在请求调用失败的 RETRY_FAILED_PERIOD 秒之后,以每隔 RETRY_FAILED_PERIOD 秒一次的频率发起重试,直到重试成功。
RETRY_FAILED_PERIOD 是多少呢?
看第 52 行,它是 5 秒。
另外,你可以在前面 addFailed 方法中看到标号为 ③ 的地方,是在往 failed 里面 put 东西。
failed 又是一个什么东西呢?
看前面的 61 行,是一个 ConcurrentHashMap。
标号为 ③ 的地方,往 failed put 的 key 就是这一次需要重试的请求,value 是处理这一次请求对应的服务端。
failed 这个 map 是什么时候用呢?
请看标号为 ② 的 retryFailed 方法:
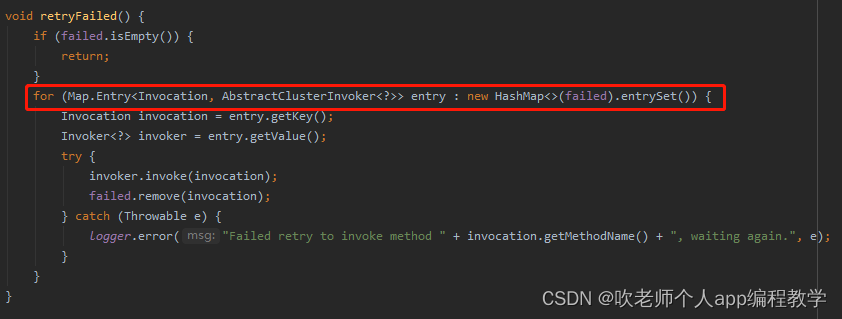
在这个方法里面会去遍历 failed 这个 map,全部拿出来再次调用一遍。
如果成功了就调用 remove 方法移除这个请求,没有成功的会抛出异常,打印日志,然后等待下次再次重试。
到这里我们就算是揭开了 Dubbo 的 FailbackClusterInvoker 类的神秘面纱。
面纱之下,隐藏的就是一个 map 加 ScheduledExecutorService。
感觉好像也没啥难的啊,很常规的解决方案嘛,我也能想到啊。
于是你缓缓的在屏幕上打出一个:

但是,朋友们,抓好坐稳,要“但是”了,要转弯了。
这里面其实是有问题的,最直观的就是这个 map,没有限制大小,由于没有限制大小,那么在一些高并发的场景下,是有可能出现内存溢出的。
好,那么问题来了,怎么防止内存溢出呢?
很简单,首先我们可以限制 map 的大小,对吧。
比如限制它的容量为 1000。
满了之后,怎么办呢?
可以搞一个淘汰策略嘛,先进先出(FIFO),或者后进先出(LIFO)。
然后也不能一直重试,如果重试超过了一定次数应该被干掉才对。
上面说的内存溢出和解决方案,都不是我乱说的。
我都是有证据的,因为我是从 FailbackClusterInvoker 这个类的提交记录上看到了它的演进过程的,前面截图的代码也是优化之前版本的代码,并不是最新的代码:
这一次提交,提到了一个编号叫 2425 的 issue。
https://github.com/apache/dubbo/issues/2425
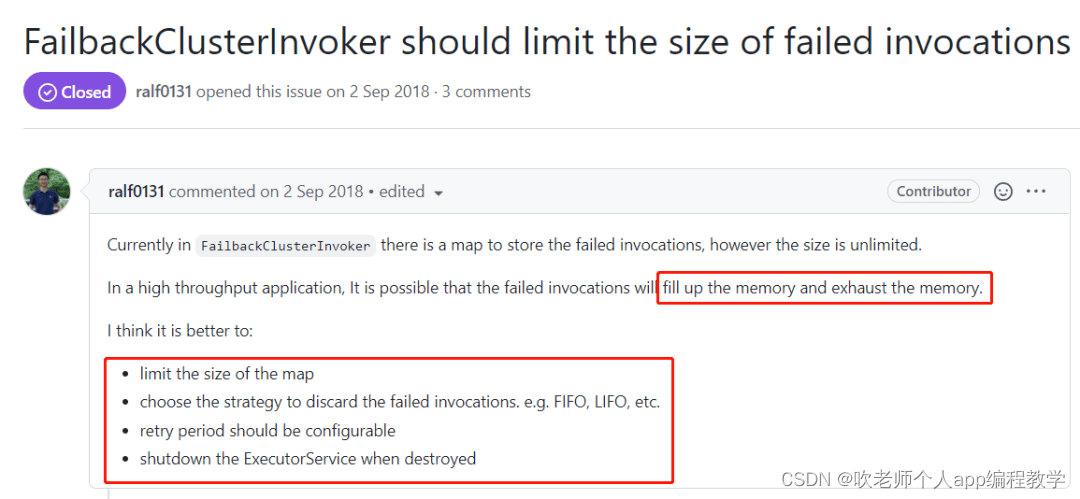
这里面提到的问题和解决方案,就是我前面说的事情。
终于,铺垫完成,关于时间轮的故事要正式开始了。
时间轮原理
有的朋友又开始猴急了。
要我赶紧上时间轮的源码。
你别着急啊,我直接给你讲源码,你肯定会看懵逼的。
所以我决定,先给你画图, 给大家画一下时间轮的基本样子,理解了时间轮的工作原理,下面的源码解析理解起来也就相对轻松一点了。
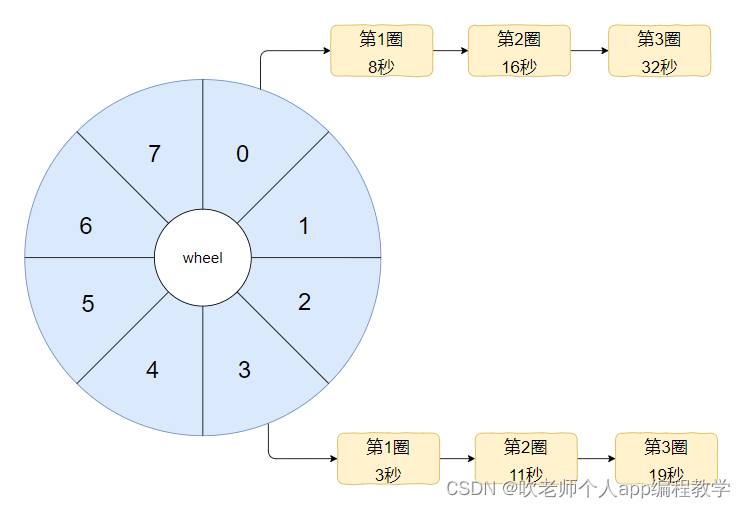
首先时间轮最基本的结构其实就是一个数组,比如下面这个长度为 8 的数组:
怎么变成一个轮呢?
首尾相接就可以了:
假如每个元素代表一秒钟,那么这个 数组一圈能表达的时间就是 8 秒,就是这样的:
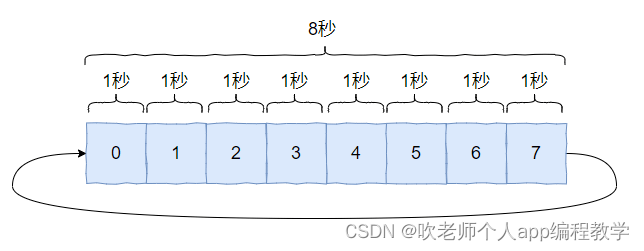
注意我前面强调的是一圈,为 8 秒。
那么 2 圈就是 16 秒, 3 圈就是 24 秒,100 圈就是 800 秒。
这个能理解吧?
我再给你配个图:
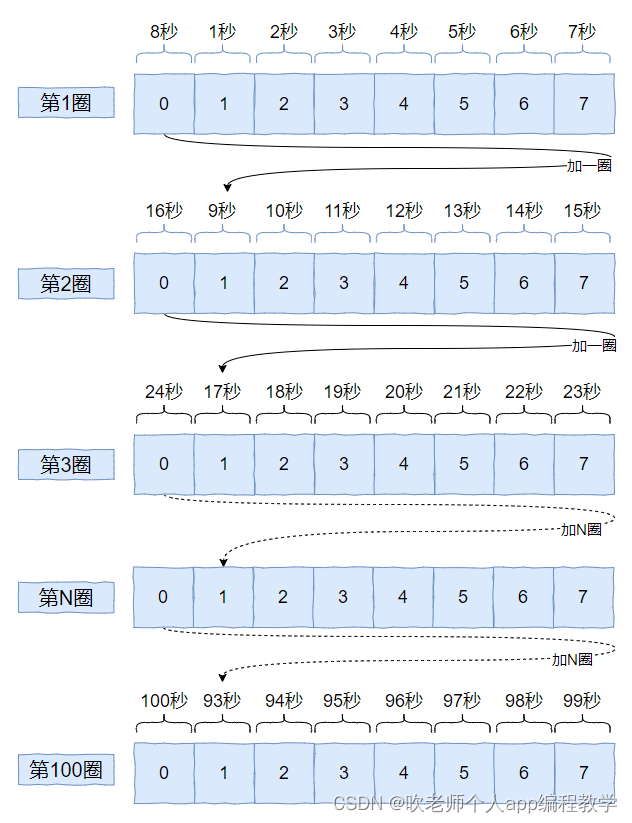
虽然数组长度只有 8,但是它可以在上叠加一圈又一圈,那么能表示的数据就多了。
比如我把上面的图的前三圈改成这样画:
希望你能看明白,看不明白也没有关系,我主要是要你知道这里面有一个“第几圈”的概念。
好了,我现在把前面的这个数组美化一下,从视觉上也把它变成一个轮子。
轮子怎么说?
轮子的英文是 wheel,所以我们现在有了一个叫做 wheel 的数组:
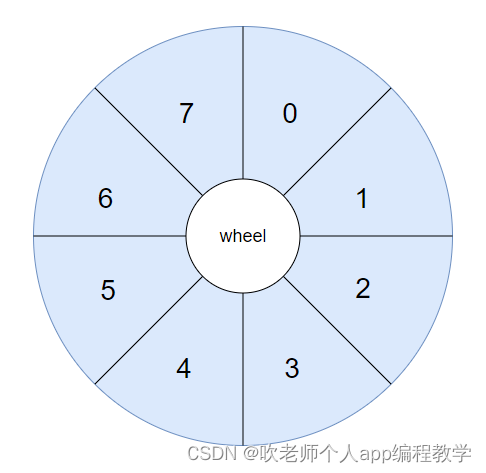
然后,把前面的数据给填进去大概是长这样的。
为了方便示意,我只填了下标为 0 和 3 的位置,其他地方也是一个意思: