文章目录
文章目录
HDFS Load和Spark Load的基本原理
一、HDFS Load
二、 Spark Load的基本原理
HDFS Load和Spark Load的基本原理
一、HDFS Load
HDFS Load主要是将HDFS中的数据导入到Doris中,Hdfs load 创建导入语句,导入方式和Broker Load 基本相同,只需要将 WITH BROKER broker_name语句替换成 With HDFS即可。
HDFS Load 与Broker Load 一样,并且底层就是转换成Broker Load进行导入数据。
除了有HDFS Load外,还有S3 Load ,两者都是将外部存储数据导入到Doris中。使用方式参考官网:
https://doris.apache.org/zh-CN/docs/dev/data-operate/import/import-scenes/external-storage-load、https://doris.apache.org/zh-CN/docs/dev/data-operate/import/import-way/s3-load-manual
二、 Spark Load的基本原理
Spark load 通过外部的 Spark 资源实现对导入数据的预处理,提高 Doris 大数据量的导入性能并且节省 Doris 集群的计算资源。Spark Load 最适合的场景就是原始数据在文件系统(HDFS)中,数据量在 几十 GB 到 TB 级别,主要用于初次迁移,大数据量导入 Doris 的场景。
Spark load 是利用了 spark 集群的资源对要导入的数据的进行了排序,Doris be 直接写文件,这样能大大降低 Doris 集群的资源使用,对于历史海量数据迁移降低 Doris 集群资源使用及负载有很好的效果。
小数据量还是建议使用 Stream Load 或者 Broker Load。如果大数据量导入Doris,用户在没有 Spark 集群这种资源的情况下,又想方便、快速的完成外部存储历史数据的迁移,可以使用 Broker load ,因为 Doris 表里的数据是有序的,所以 Broker load 在导入数据的时是要利用doris 集群资源对数据进行排序,对 Doris 的集群资源占用要比较大。如果有Spark 计算资源建议使用 Spark load。
基本原理:
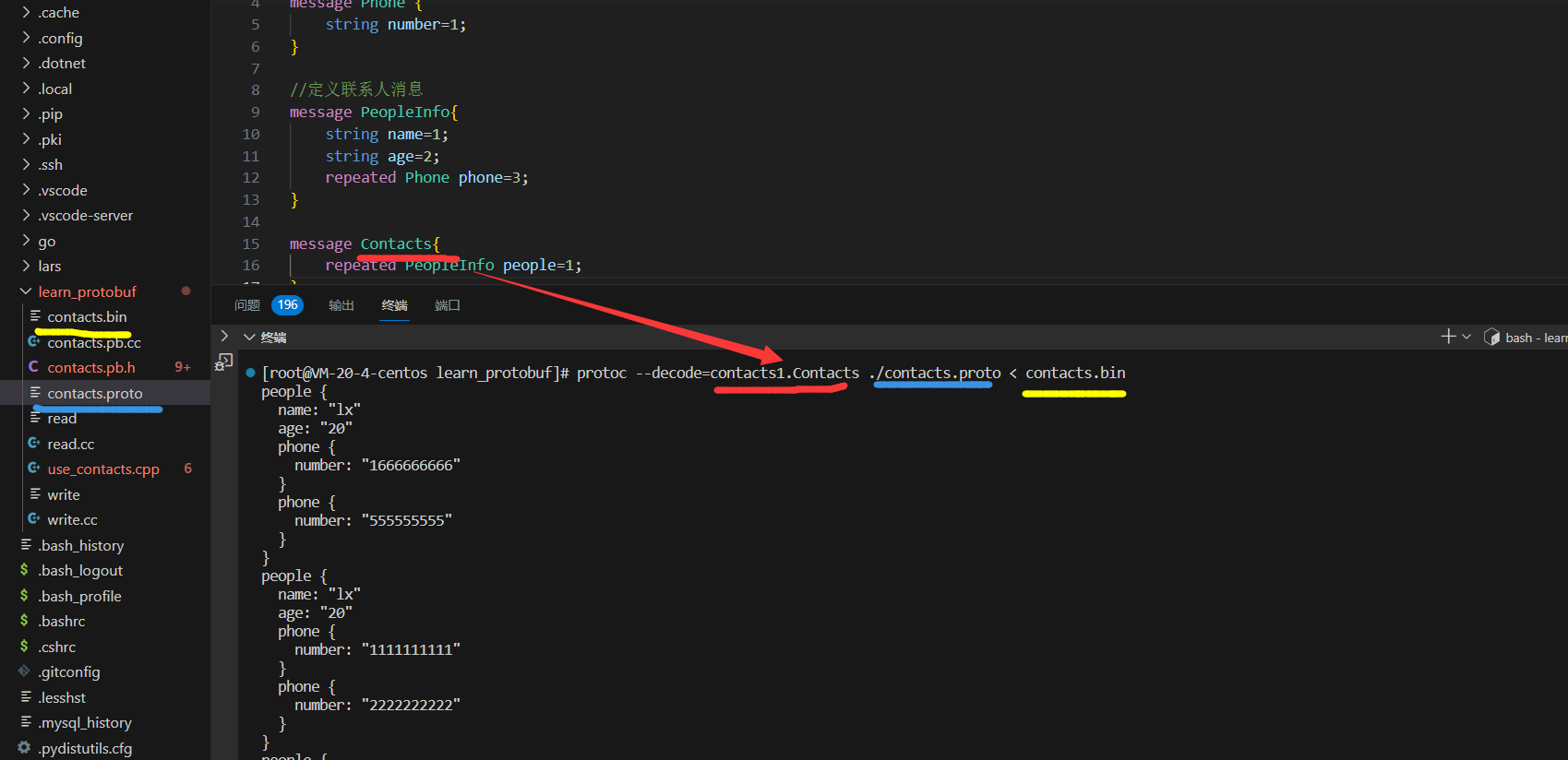
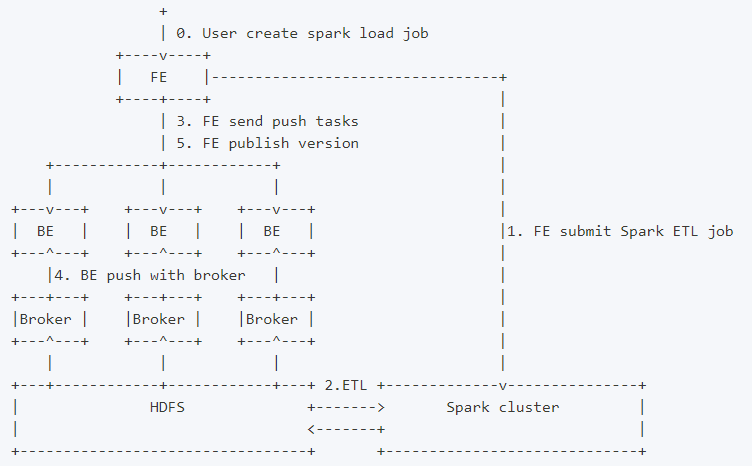
Spark load 是一种异步导入方式,用户需要通过 MySQL 协议创建 Spark 类型导入任务,并通过 SHOW LOAD 查看导入结果。当用户通过 MySQL 客户端提交 Spark 类型导入任务,FE记录元数据并返回用户提交成功,Spark load 任务的执行主要分为以下5个阶段
- FE 调度提交 ETL 任务到 Spark 集群执行。
- Spark 集群执行 ETL 完成对导入数据的预处理。包括全局字典构建( BITMAP 类型)、分区、排序、聚合等。
- ETL 任务完成后,FE 获取预处理过的每个分片的数据路径,并调度相关的 BE 执行 Push 任务。
- BE 通过 Broker 读取数据,转化为 Doris 底层存储格式。
- FE 调度生效版本,完成导入任务。
架构图:
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨