Protobuf入门
Protobuf介绍
Protobuf (Protocol Buffers) 是谷歌开发的一款无关平台,无关语言,可扩展,轻量级高效的序列化结构的数据格式,用于将自定义数据结构序列化成字节流,和将字节流反序列化为数据结构。所以很适合做数据存储和为不同语言,不同应用之间互相通信的数据交换格式,只要实现相同的协议格式,即后缀为proto文件被编译成不同的语言版本,加入各自的项目中,这样不同的语言可以解析其它语言通Protobuf序列化的数据。目前官方提供c++,java,go等语言支持。
Protobuf特点
- 语言无关、平台无关:即Protobuf支持java、C++、Python等多种语言。
- 高效:即比XML更小、更快、更简单。
- 扩展性、兼容性好:可以更新数据结构,而不影响和破坏原有的旧程序。
- 使用特定:Protobuf是需要依赖通过编译生成的头文件和源文件来使用。
工作流程:

- 编写.proto⽂件,⽬的是为了定义结构对象(message)及属性内容。
- 使⽤protoc编译器编译.proto⽂件,⽣成⼀系列接⼝代码,存放在新⽣成头⽂件和源⽂件中。
- 依赖⽣成的接⼝,将编译⽣成的头⽂件包含进我们的代码中,实现对.proto⽂件中定义的字段进⾏设置和获取,和对message对象进⾏序列化和反序列化。
什么是序列化和反序列化
- 序列化过程:是指把一个对象变成二进制内容。
- 反序列化过程:把一个二进制内容变回对象。
Protobuf入门实战
实现目标如下:
• 对⼀个联系⼈的信息使⽤PB进⾏序列化,并将结果打印出来。
• 对序列化后的内容使⽤PB进⾏反序列,解析出联系⼈信息并打印出来。
• 联系⼈包含以下信息:姓名、年龄。
步骤如下:
- 编写.proto文件,定义message
- 编译.proto文件,查看生成的代码
- 实现对一个联系人的序列化和反序列化操作
编写.proto文件
创建contacts.proto文件
Protocol Buffers语⾔版本3,简称proto3,是.proto⽂件最新的语法版本。proto3简化了Protocol Buffers语⾔,既易于使⽤,⼜可以在更⼴泛的编程语⾔中使⽤。它允许你使⽤Java,C++,Python等多种语⾔⽣成protocol buffer代码。在.proto⽂件中,要使⽤syntax = “proto3”; 来指定⽂件语法为proto3,并且必须写在除去注释内容的第⼀⾏。如果没有指定,编译器会使⽤proto2语法。
syntax="proto3"; //消息类型命名规范:使⽤驼峰命名法,⾸字⺟⼤写。
package contacts;
//定义联系人消息
message PeopleInfo{
string name=1;
string age=2;
}
Protobuf标量数据
| protoType | Notes | C++ Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使⽤变⻓编码[1]。负数的编码效率较低⸺若字段可 能为负值,应使⽤sint32代替。 | int32 |
| int64 | 使⽤变⻓编码[1]。负数的编码效率较低⸺若字段可 能为负值,应使⽤sint64代替。 | int64 |
| uint32 | 使⽤变⻓编码[1]。 | uint32 |
| uint64 | 使⽤变⻓编码[1]。 | uint64 |
| sint32 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于 常规的int32类型。 | int32 |
| sint64 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于 常规的int64类型。 | int64 |
| fixed32 | 定⻓4字节。若值常⼤于2^28则会⽐uint32更⾼ 效。 | uint32 |
| fixed64 | 定⻓8字节。若值常⼤于2^56则会⽐uint64更⾼ 效。 | uint64 |
| sfixed32 | 定⻓4字节。 | int32 |
| sfixed64 | 定⻓8字节。 | int64 |
| bool | bool | |
| string | 包含UTF-8和ASCII编码的字符串,⻓度不能超过 2^32。 | string |
| bytes | 可包含任意的字节序列但⻓度不能超过2^32。 | string |
[1]变⻓编码是指:经过protobuf编码后,原本4字节或8字节的数可能会被变为其他字节数。
字段的唯一编号
字段编号的范围为1536,870,911(2^29-1),其中1900019999不可⽤。
19000~19999不可⽤是因为:在Protobuf协议的实现中,对这些数进⾏了预留。如果⾮要在.proto⽂件中使⽤这些预留标识号,例如将name字段的编号设置为19000,编译时就会报警:
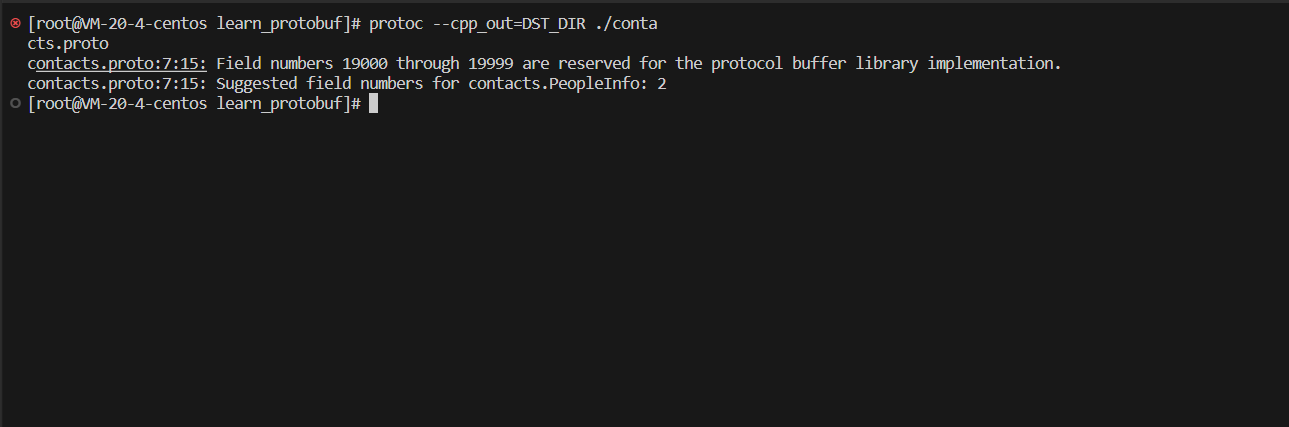
编译.proto文件
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
protoc 是 Protocol Buffer 提供的命令⾏编译⼯具。
--proto_path 指定 被编译的.proto⽂件所在⽬录,可多次指定。可简写成 -IIMPORT_PATH 。如不指定该参数,则在当前⽬录进⾏搜索。当某个.proto ⽂件 import 其他.proto ⽂件时,或需要编译的 .proto ⽂件不在当前⽬录下,这时就要⽤-I来指定搜索⽬录。
--cpp_out= 指编译后的⽂件为 C++ ⽂件。
DST_DIR 编译后⽣成⽂件的⽬标路径。
path/to/file.proto 要编译的.proto⽂件。
执行命令:protoc --cpp_out=. ./contacts.proto
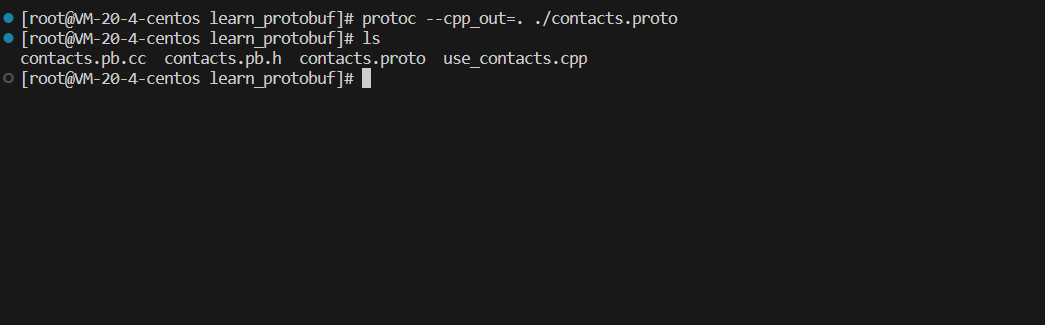
编译contacts.proto⽂件后会⽣成什么
编译contacts.proto⽂件后,会⽣成所选择语⾔的代码,这里选择的是C++,所以编译后⽣成了两个⽂件: contacts.pb.h contacts.pb.cc。对于编译⽣成的C++代码,包含了以下内容:
• 对于每个message,都会⽣成⼀个对应的消息类。
• 在消息类中,编译器为每个字段提供了获取和设置⽅法,以及⼀下其他能够操作字段的⽅法。
• 编辑器会针对于每个.proto ⽂件⽣成 .h 和 .cc ⽂件,分别⽤来存放类的声明与类的实现。
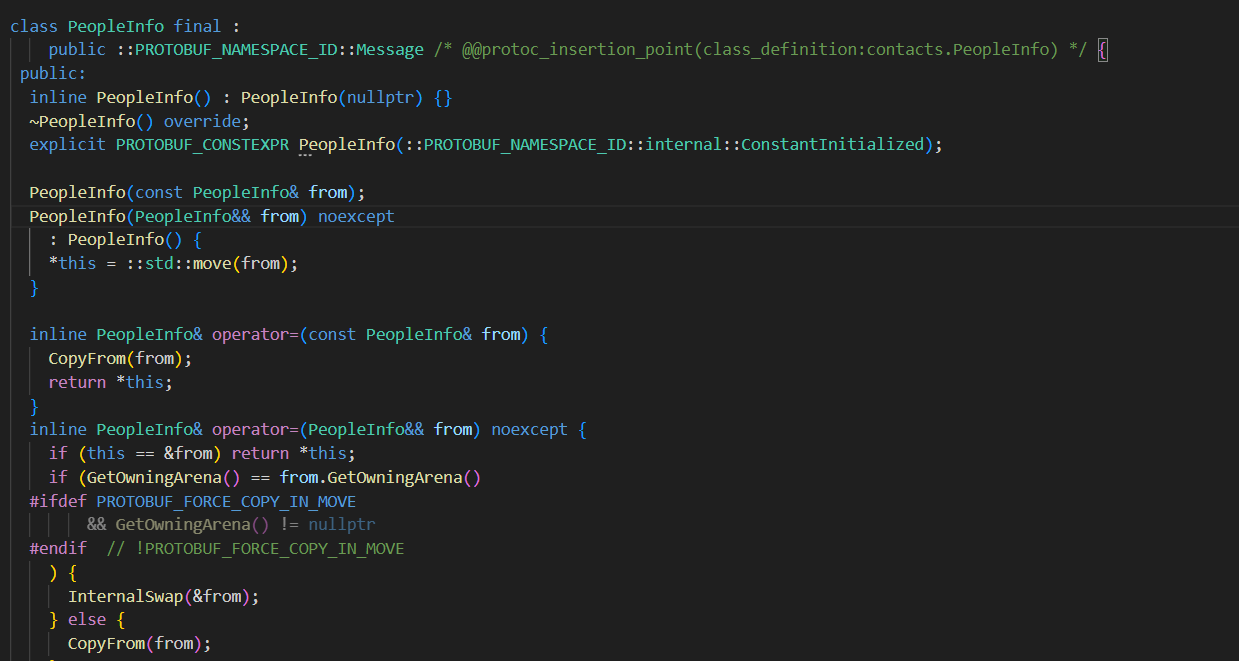
该类是继承于Message类。且对于每一个成员,都有set方法和get方法获取和设置对应的成员属性。
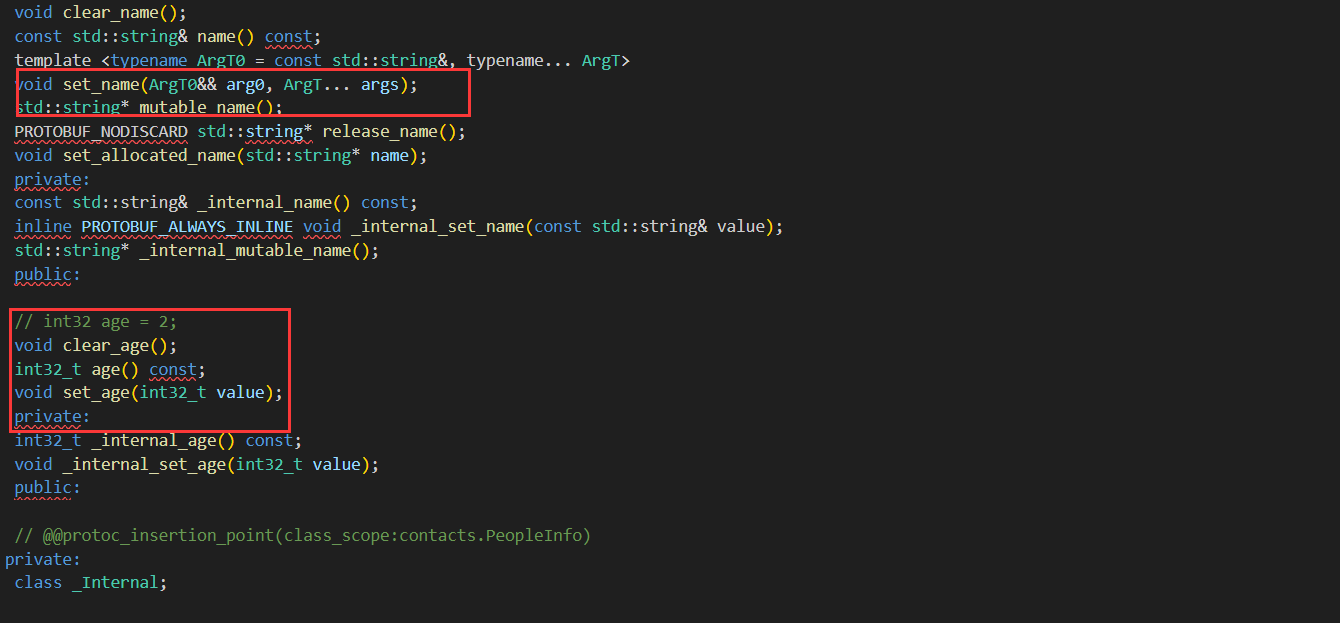
而序列化和反序列化的方法,则是定义在其父类中:MessageLite
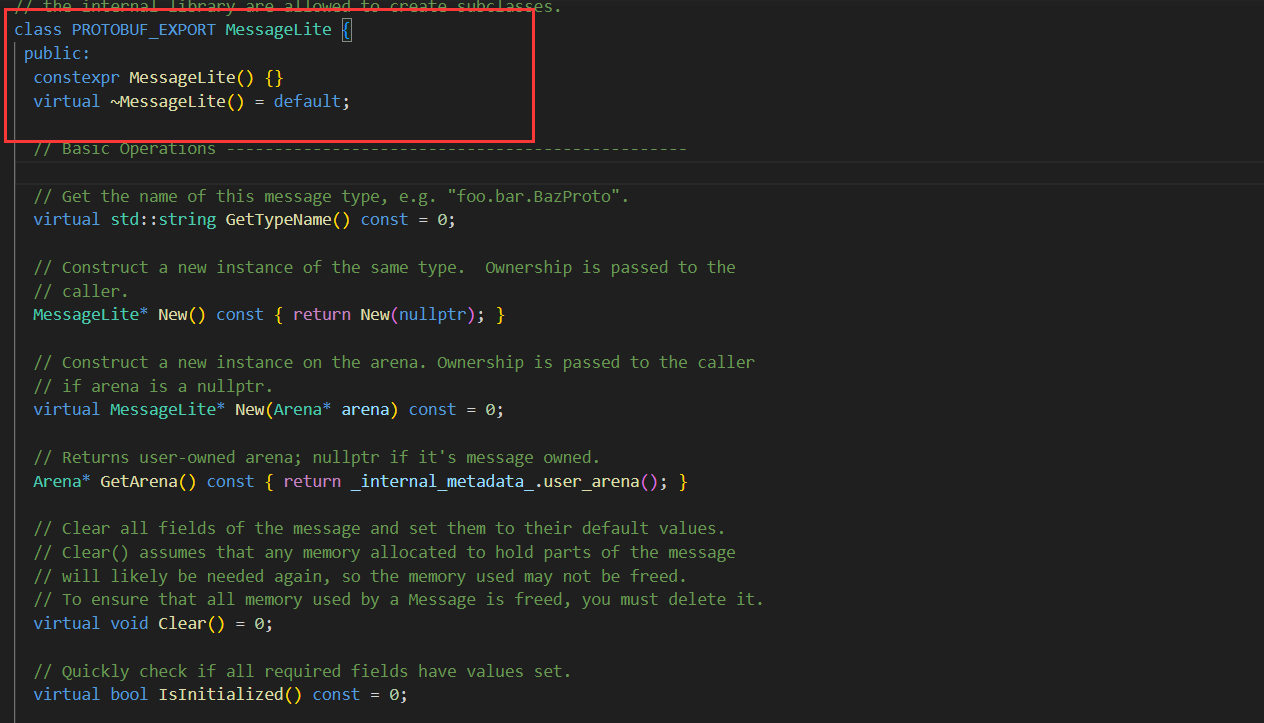
其接口主要如下:
class MessageLite {
public:
//序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写⼊⽂件流
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进⾏反序列化动作
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};
注意:
• 序列化的结果为⼆进制字节序列,⽽⾮⽂本格式。
• 以上三种序列化的⽅法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应⽤场景使⽤。
• 序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容,⽽是将序列化的结果保存到函数⼊参指定的地址中
• 详细messageAPI可以参⻅完整列表。 Protocol Buffers Documentation (protobuf.dev)
实现序列化和反序列化
- 对⼀个联系⼈的信息使⽤protobuf进⾏序列化,并将结果打印出来。
- 然后将二进制数据使用protobuf进行反序列,并获取其内容。
- 创建文件use_contacts.cpp
#include <iostream>
#include "contacts.pb.h"
using namespace std;
int main()
{
string people_str;
{
// .proto⽂件声明的package,通过protoc编译后,会为编译⽣成的C++代码声明同名的命名空间
// 其范围是在.proto ⽂件中定义的内容
contacts::PeopleInfo people;
people.set_age("20");
people.set_name("张三");
// 调⽤序列化⽅法,将序列化后的⼆进制序列存⼊string中
if (!people.SerializeToString(&people_str))
{
cout << "序列化联系⼈失败." << endl;
}
// 打印序列化结果
cout << "序列化后的 people_str: " << people_str << endl;
}
{
contacts::PeopleInfo people;
// 调⽤反序列化⽅法,读取string中存放的⼆进制序列,并反序列化出对象
if (!people.ParseFromString(people_str))
{
cout << "反序列化出联系⼈失败." << endl;
}
// 打印结果
cout << "Parse age: " << people.age() << endl;
cout << "Parse name: " << people.name() << endl;
}
return 0;
}
编译:g++ -o contacts use_contacts.cpp contacts.pb.cc -lprotobuf -std=c++11
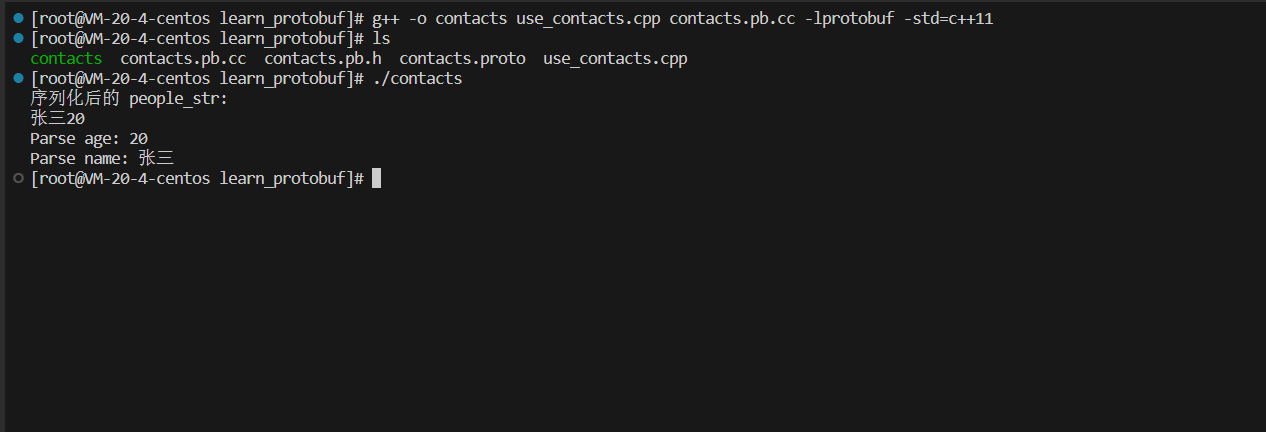
注意:
- 由于ProtoBuf是把对象序列化成了⼆进制序列,这⾥⽤string来作为接收⼆进制序列的容器。所以在终端打印的时候会有换⾏等⼀些乱码显⽰。
- 所以相对于xml和JSON来说,因为被编码成⼆进制,破解成本增⼤,ProtoBuf编码是相对安全的。
protobuf语法详解
项目目标:升级的版本,最终将会升级如下内容:
• 不再打印联系⼈的序列化结果,⽽是将通讯录序列化后并写⼊⽂件中。
• 从⽂件中将通讯录解析出来,并进⾏打印。
• 新增联系⼈属性,共包括:姓名、年龄、电话信息、地址、其他联系⽅式、备注。
字段规则
- singular:消息中可以包含该字段零次或⼀次(不超过⼀次)。proto3语法中,字段默认使⽤该
规则。 - repeated:消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理解为定义了⼀个数组。
比如下面的写法表示:在一个PeopleInfo信息里面,可以包含多个phone_num
//定义联系人消息
message PeopleInfo{
string name=1;
string age=2;
repeated string phone_num=3;
}
消息类型的定义和使用
下面实现,在目前的contacts.proto文件中加入phone属性,并单独设置为一个message。
则一共有三种写法,包括嵌套,非嵌套写法,分开住两个文件中定义
嵌套写法
/--------------嵌套写法---------------/
message PeopleInfo{
string name=1;
string age=2;
message Phone{
string number=1;
}
repeated Phone phone=3;
}
//通讯录定义
message Contacts{
repeated PeopleInfo people=1;
}
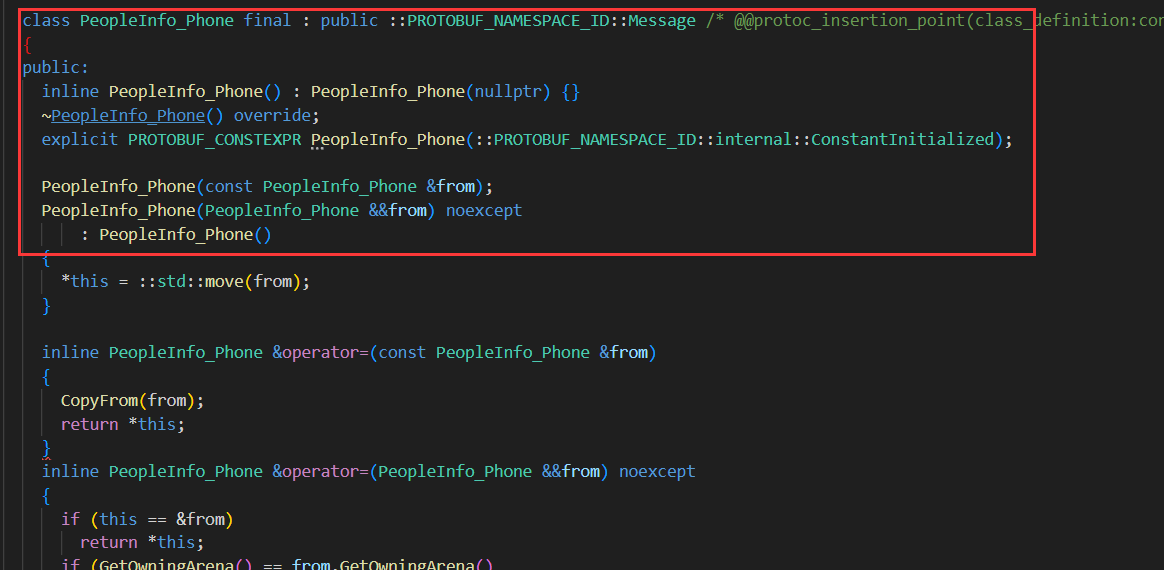
当为嵌套定义时,Phone在头文件中的类名就变为了PeopleInfo_Phone。也是使用下划线将内部与外部名连接起来。
非嵌套写法
message Phone{
string number=1;
}
//定义联系人消息
message PeopleInfo{
string name=1;
string age=2;
repeated Phone phone=3;
}
message Contacts{
repeated PeopleInfo people=1;
}
分为两个文件
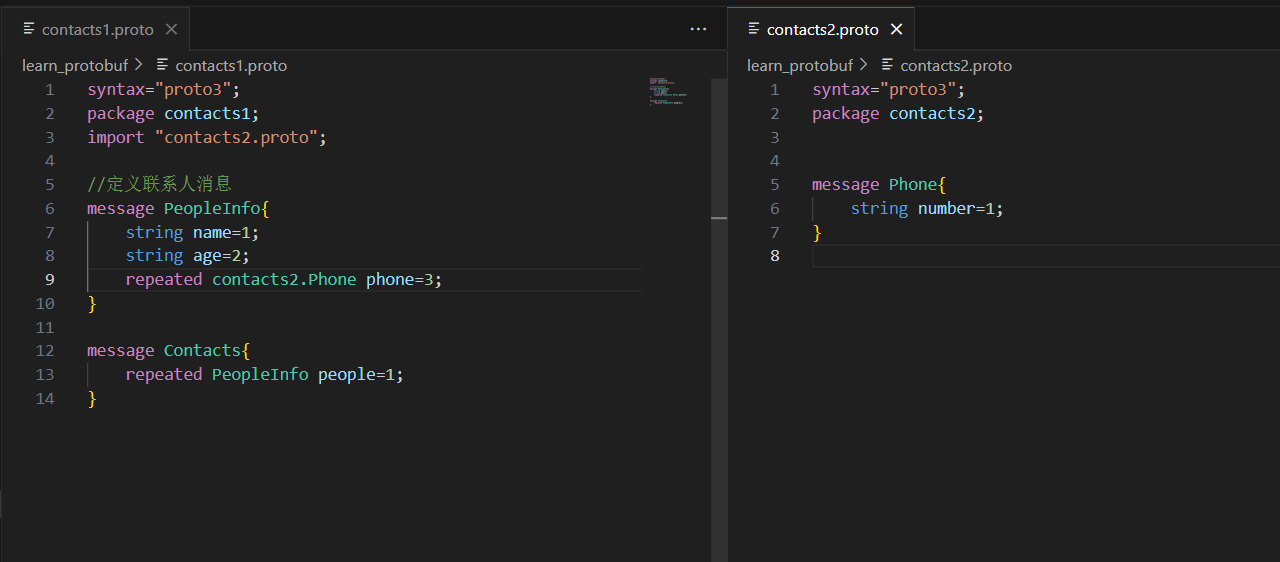
如果contacts2.proto文件中并没有定义package contacts2,那么文件1在使用message phone时,也不需要带上contacts2.。

实现通讯录v0.2
实现write.cc:向通讯录中写入内容
void AddPeopleInfo(contacts1::Contacts *contacts_ptr)
{
for (int j = 0;; j++)
{
std::cout << "--------- 新增联系人(输入“退出”即可结束新增联系人) --------" << std::endl;
std::cout << " 请输入联系人姓名: ";
string name;
getline(std::cin, name);
if(name=="退出"){
break;
}
contacts1::PeopleInfo *peopleinfo = contacts_ptr->add_people(); //添加一个people消息
peopleinfo->set_name(name);
std::cout << " 请输入联系人年龄: ";
string age;
getline(std::cin, age);
peopleinfo->set_age(age);
for (int i = 0;; i++)
{
std::cout << " 请输入联系人电话 " << i + 1 << "(只输入回车完成电话的新增): ";
string number;
getline(std::cin, number);
if (number.empty())
{
break;
}
contacts1::Phone *phone = peopleinfo->add_phone(); //添加一个phone信息
phone->set_number(number);
}
}
}
int main()
{
contacts1::Contacts contacts;
// 读取本地已经存在的联系人文件
fstream input("contacts.bin", ios::in | ios::binary);
if (!input)
{
std::cout << " contacts.bin not find,create new file! " << std::endl;
}
else if (!contacts.ParseFromIstream(&input))
{
std::cerr << " Failed to parse contacts.bin " << std::endl;
input.close();
return -1;
}
AddPeopleInfo(&contacts);
// 向文件中覆盖写入新的内容
fstream output("contacts.bin", ios::out | ios::binary | ios::trunc);
if (!contacts.SerializeToOstream(&output))
{
std::cerr << " Failed to serialize ,write error! " << std::endl;
output.close();
input.close();
return -1;
}
std::cout << " write success! " << std::endl;
output.close();
input.close();
/*
在程序结束时调⽤ ShutdownProtobufLibrary(),为了删除 Protocol Buffer 库分配的所
有全局对象。对于⼤多数程序来说这是不必要的,因为该过程⽆论如何都要退出,并且操作系统将负责
回收其所有内存。但是,如果你使⽤了内存泄漏检查程序,该程序需要释放每个最后对象,或者你正在
编写可以由单个进程多次加载和卸载的库,那么你可能希望强制使⽤ Protocol Buffers 来清理所有
内容。
*/
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
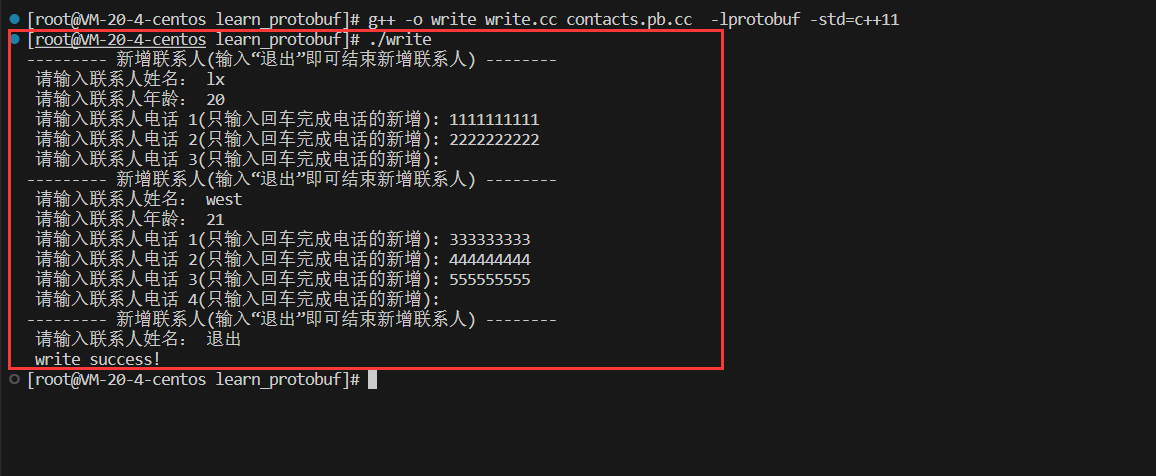
可以看到contacts.bin中以二进制的方式写入了内容:
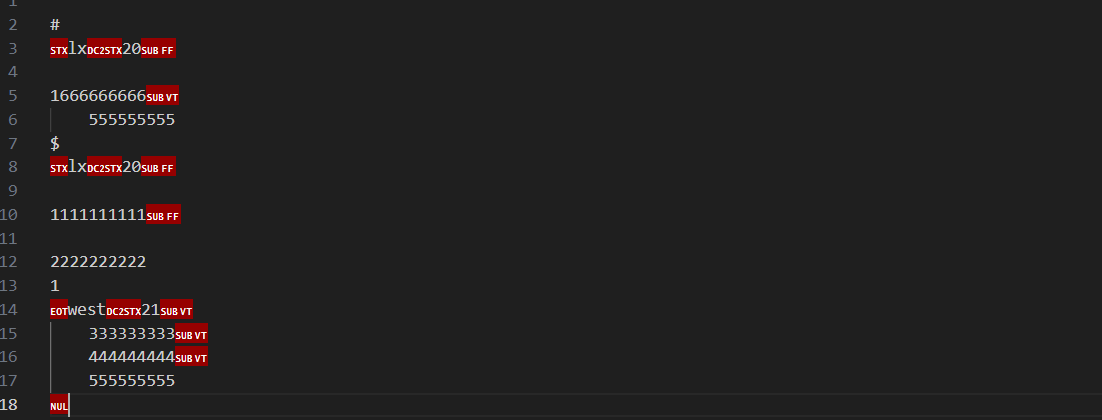
hexdump程序
hexdump:是Linux下的⼀个⼆进制⽂件查看⼯具,它可以将⼆进制⽂件转换为ASCII、⼋进制、⼗进制、⼗六进制格式进⾏查看。
参数:
- -C: 表⽰每个字节显⽰为16进制和相应的ASCII字符
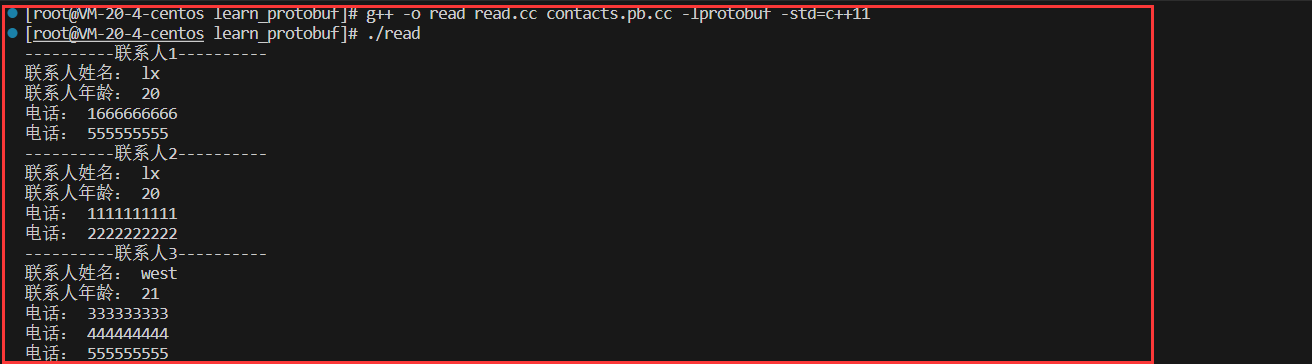
实现read.cc:反序列化二进制文件的内容
void PrintContacts(contacts1::Contacts& contacts){
for(int i=0;i<contacts.people_size();i++){
contacts1::PeopleInfo peopleinfo=contacts.people(i); //通过下标获取people
std:cout<<"----------联系人"<<i+1<<"----------"<<std::endl;
std::cout<<"联系人姓名: "<<peopleinfo.name()<<std::endl;
std::cout<<"联系人年龄: "<<peopleinfo.age()<<std::endl;
int j=1;
for(;j<=peopleinfo.phone_size();j++){
std::cout<<"电话: "<<peopleinfo.phone(j-1).number()<<std::endl;
}
}
}
int main(){
contacts1::Contacts contacts;
fstream input("contacts.bin",ios::binary | ios::in);
if(!input){
std::cout << " contacts.bin not find,create new file! " << std::endl;
}
else if(!contacts.ParseFromIstream(&input)){
std::cerr<<" Failed to Parse contacts.bin !"<<std::endl;
input.close();
return -1;
}
PrintContacts(contacts);
input.close();
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
输出结果:
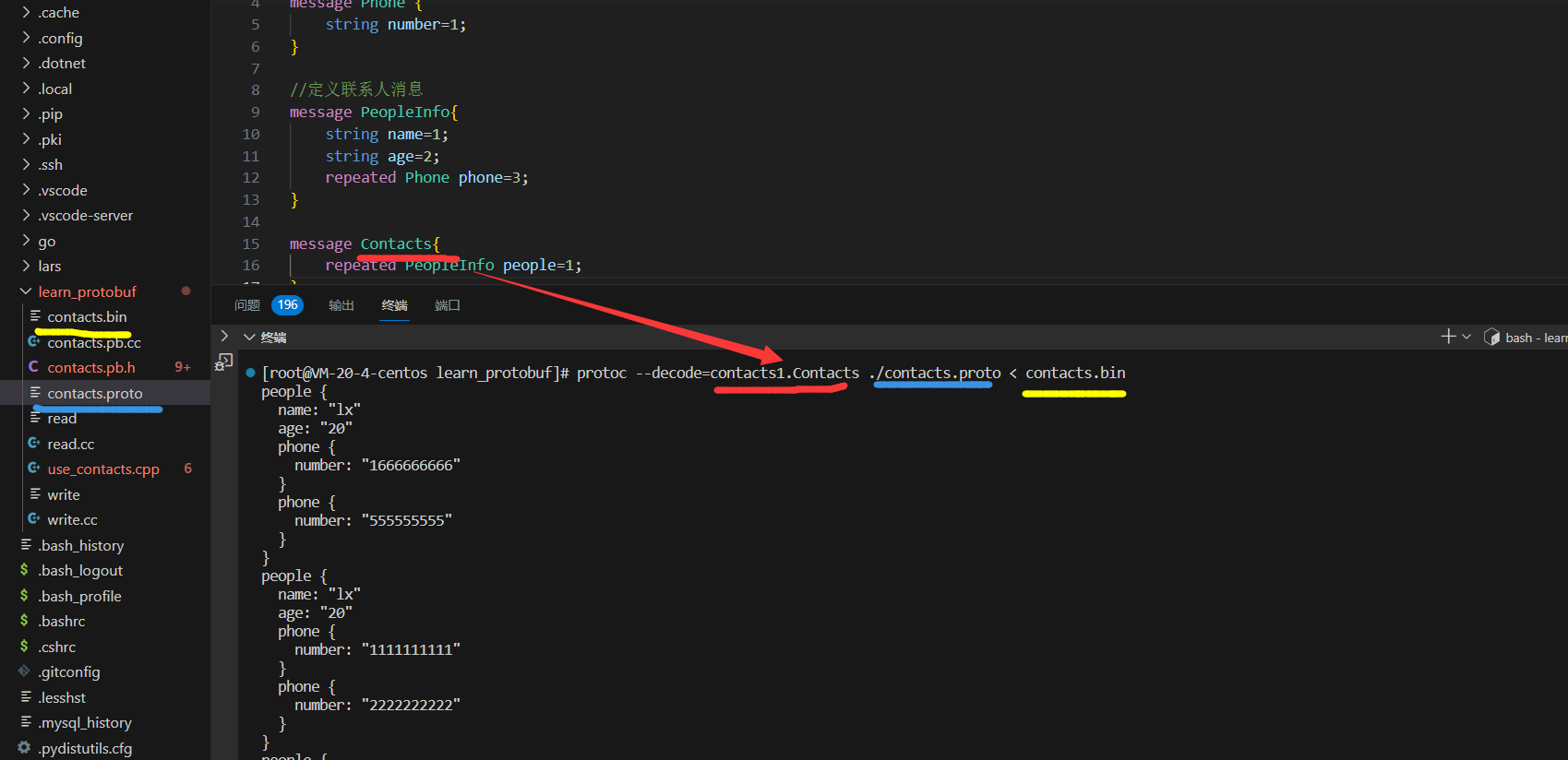
decode命令
我们可以⽤protoc -h命令来查看ProtoBuf为我们提供的所有命令option。
其中ProtoBuf提供⼀个命令选项 --decode ,表⽰从标准输⼊中读取给定类型的⼆进制消息,并将其以⽂本格式写⼊标准输出。消息类型必须在.proto⽂件或导⼊的⽂件中定义。
protoc --decode=MESSAGE_TYPE TYPE_PATH < STD_IN
可以指定解码一种消息类型,后面需要指明消息类型的路径 已经输入文件
protoc --decode=contacts.Contacts ./contacts.proto < contacts.bin