Python关联规则——挖掘数据中的隐藏关系
在数据分析和挖掘中,我们经常需要找到数据集中的关联规则,以便更好地理解数据背后的隐藏关系和趋势。Python关联规则是一种经典的关联规则挖掘算法,它能够识别和发现数据中的有意义的关联性,从而使得数据分析更加深入和精准。
什么是Python关联规则?
Python关联规则(Association Rules)是一种数据挖掘方法,它用于标识数据集中的经常出现在一起的项目集合。这些项目集合被称为“频繁项集”,而它们之间的关联关系被称为“关联规则”或“频繁模式”。
Python关联规则根据数据集中不同项目之间的关系度量它们之间的相关性。它使用两个指标来描述这种关系:支持度和置信度。
支持度表示在数据集中所有事务中同时包含一个项集I和一个项集J的频率。而置信度则表示当一个项集I出现时,另外一个项集J也一定会出现的概率。
如何挖掘数据中的关联规则?
Python关联规则挖掘算法的基本思想是找到频繁项集,并为其生成置信度大于设定阈值的关联规则。它由两个步骤组成:支持度计算和规则生成。
支持度计算阶段通过扫描整个数据集,识别出经常出现在一起的项集。然后,根据设定的阈值,选取支持度大于阈值的项集,这些项集被称为“频繁项集”。
规则生成阶段从频繁项集中,对每个项集构造关联规则,并计算其置信度。通过设定置信度阈值,筛选出置信度大于阈值的关联规则。
Python关联规则算法的一个重要特点是,它能够在大规模数据集上进行高效快速的分析,并且具有很好的可扩展性,能够处理大型且稀疏的数据集。
一个实例
下面我们通过一个实例来展示Python关联规则的应用。假设我们有一个超市的购物清单数据集,其中每个事务表示一个客户购买的商品项。我们要找到经常在一起销售的商品项集,并构造其关联规则。
我们首先将数据集读入Python中,并进行“one-hot编码”,将每个商品转化为二进制变量。下面是Python代码:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
dataset = [['milk', 'bread', 'butter'],
['butter', 'cheese'],
['milk', 'bread', 'cheese'],
['milk', 'bread', 'butter', 'cheese'],
['bread', 'butter']]
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
接下来,我们使用mlxtend库中的apriori函数,找到支持度大于0.5的频繁项集。下面是Python代码:
from mlxtend.frequent_patterns import apriori
freq_items = apriori(df, min_support=0.5, use_colnames=True)
然后,我们使用mlxtend库中的association_rules函数,根据频繁项集找到置信度大于0.7的关联规则。下面是Python代码:
from mlxtend.frequent_patterns import association_rules
rules = association_rules(freq_items, metric="confidence", min_threshold=0.7)
最后,我们可以打印出找到的关联规则。下面是Python代码:
print(rules)
输出结果为:
antecedents consequents antecedent support consequent support support confidence lift leverage conviction
0 (bread) (butter) 0.8 0.6 0.6 0.750000 1.250000 0.12 1.6
1 (butter) (bread) 0.6 0.8 0.6 1.000000 1.250000 0.12 inf
2 (cheese) (bread) 0.6 0.8 0.6 1.000000 1.250000 0.12 inf
3 (bread) (cheese) 0.8 0.6 0.6 0.750000 1.250000 0.12 1.6
4 (butter) (cheese) 0.6 0.6 0.6 1.000000 1.666667 0.24 inf
5 (cheese) (butter) 0.6 0.6 0.6 1.000000 1.666667 0.24 inf
从结果中可以看出,经常一起销售的商品项集为“面包和黄油”、“面包和奶酪”、“黄油和奶酪”,其中“面包和黄油”的置信度为0.75,意味着在购买了面包的情况下,有75%的概率会购买黄油。
结论
在数据分析和挖掘的应用中,Python关联规则是一种非常有效的算法,它能够识别出数据中的隐藏关系和趋势,帮助我们深入理解数据集。通过Python关联规则,我们可以找到经常一起销售的商品、疾病之间的关联性、用户行为的关联规律等等,这些发现能够为我们提供更好的决策支持和业务优化建议。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
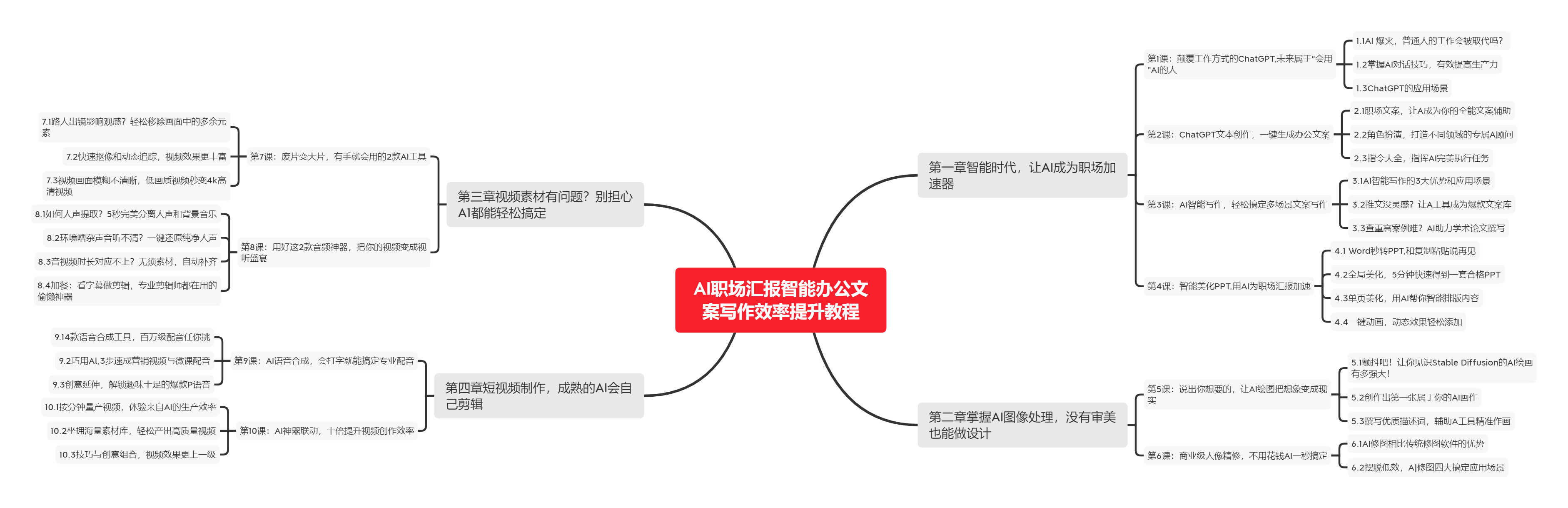
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |