tiktoken是OpenAI于近期开源的Python第三方模块,该模块主要实现了tokenizer的BPE(Byte pair encoding)算法,并对运行性能做了极大的优化。本文将介绍tiktoken模块的使用。
tiktoken简介
BPE(Byte pair encoding)算法是NLP中常见的tokenizer方式,关于其介绍和实现原理,读者可参考深入理解NLP Subword算法:BPE、WordPiece、ULM。
tiktoken已开源至Github,访问网址为:https://github.com/openai/tiktoken,tiktoken会比其它开源的tokenizer库运行快3-6倍,以下是它与hugging face的tokenizer库的性能比较:

以上结果是使用GPT-2 tokenizer在1G文本上进行的性能测试,使用的GPT2TokenizerFast来源于tokenizers==0.13.2, transformers==4.24.0 , tiktoken==0.2.0。
简单使用
tiktoken的Encodings(编码方式)用于展示文本是如何被转化为token的。不同的模型使用不同类型的编码方式。tiktoken支持如下三种OpenAI模型的编码方式:
| 编码方式 | OpenAI模型 |
|---|---|
| cl100k_base | gpt-4, gpt-3.5-turbo, text-embedding-ada-002 |
| p50k_base | Codex模型,如 text-davinci-002, text-davinci-003 |
| r50k_base (或gpt2) | GPT-3模型,如davinci |
可以通过如下代码来获取模型的编码方式:
# -*- coding: utf-8 -*-
import tiktoken
# get encoding name
print(tiktoken.encoding_for_model('gpt-3.5-turbo'))
输出结果为:
<Encoding 'cl100k_base'>
注意,p50k_base与r50k_base基本类似,在非代码应用中,它们通常会给出相同的token。
cl100k_base中的100k代码该编码方式中的词汇表数量大约为100k,词汇表文件为cl100k_base_vocab.json,下载网址为:https://raw.githubusercontent.com/weikang-wang/ChatGPT-Vocabulary/main/cl100k_base_vocab.json,词汇数量为100256,如此庞大的词汇数量使得OpenAI模型在多种语言上都有不俗的表现。
编码与解码
编码(encode)是指将文本映射为token的数字列表,解码(decode)是指将token的数字列表转化为文本。参看以下的Python代码实现:
# -*- coding: utf-8 -*-
import tiktoken
# simple test
enc = tiktoken.get_encoding("cl100k_base")
print(enc.encode("hello world") == [15339, 1917])
print(enc.decode([15339, 1917]) == "hello world")
print(enc.encode("hello <|endoftext|>", allowed_special="all") == [15339, 220, 100257])
# encode
tokens = enc.encode("tiktoken is great!")
print(tokens)
print(len(tokens))
# decode
print(enc.decode([83, 1609, 5963, 374, 2294, 0]))
# chinese encode
tokens = enc.encode("大模型是什么?")
print(tokens)
print(len(tokens))
# chinese decode
print(enc.decode([27384, 54872, 25287, 21043, 6271, 222, 82696, 11571]))
输出结果如下:
True
True
True
[83, 1609, 5963, 374, 2294, 0]
6
tiktoken is great!
[27384, 54872, 25287, 21043, 6271, 222, 82696, 11571]
8
大模型是什么?
计算token数量
OpenAI模型中token数量较为关键,毕竟,OpenAI接口调用的收费方式是按照token数量来的。关于OpenAI接口调用的收费方式,可以参考网站:https://openai.com/pricing。
下面是用tiktoken来计算token数量的Python代码:
# -*- coding: utf-8 -*-
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
# Returns the number of tokens in a text string.
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
print(num_tokens_from_string('tiktoken is great!', 'cl100k_base'))
print(num_tokens_from_string('大模型是什么?', 'cl100k_base'))
输出结果为:
6
8
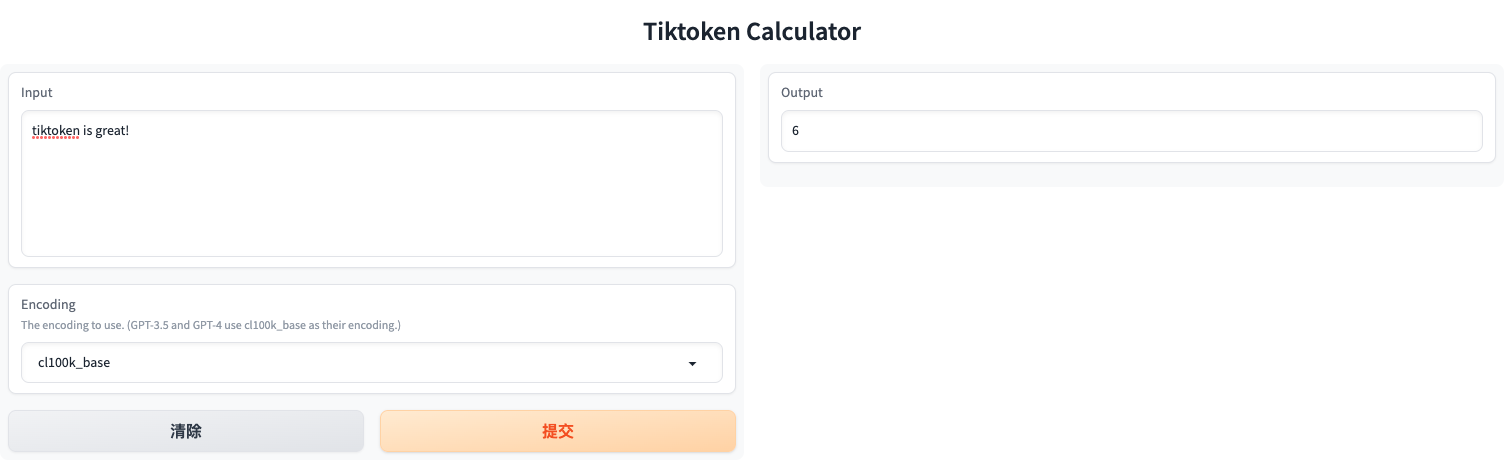
在hugging face网站上,已经有人实现了tiktoken的token数量计算,访问网站为:https://huggingface.co/spaces/JacobLinCool/tiktoken-calculator ,页面如下:
在对话补全(chat completion)场景中计算token数量,以模型gpt-3.5-turbo为例,实现Python代码如下:
# -*- coding: utf-8 -*-
import tiktoken
import openai
def num_tokens_from_messages(messages):
# Returns the number of tokens used by a list of messages.
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
tokens_per_name = -1 # if there's a name, the role is omitted
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens
example_messages = [
{
"role": "system",
"content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.",
},
{
"role": "system",
"name": "example_user",
"content": "New synergies will help drive top-line growth.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Things working well together will increase revenue.",
},
{
"role": "system",
"name": "example_user",
"content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Let's talk later when we're less busy about how to do better.",
},
{
"role": "user",
"content": "This late pivot means we don't have time to boil the ocean for the client deliverable.",
},
]
# example token count from the function defined above
print(f"{num_tokens_from_messages(example_messages)} prompt tokens counted by num_tokens_from_messages().")
# example token count from the OpenAI API
openai.api_key = ""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=example_messages,
temperature=0,
max_tokens=1
)
print(f'{response["usage"]["prompt_tokens"]} prompt tokens counted by the OpenAI API.')
输出结果如下:
127 prompt tokens counted by num_tokens_from_messages().
127 prompt tokens counted by the OpenAI API.
可见,在num_tokens_from_messages中,对于输入messages中的每条message,token数量先加上4,然后对字典中的value值进行token数量统计,如果此时对应的key为name,则token数量减1,因为要忽略role字段的token数量。在模型gpt-3.5-turbo中,num_tokens_from_messages函数与OpenAI对话补全中的token数量计算方式是一致的。
总结
本文介绍了tiktoken模型和它的简单使用,以及token数量计算方式。
参考文献
- 深入理解NLP Subword算法:BPE、WordPiece、ULM: https://zhuanlan.zhihu.com/p/86965595
- tiktoken的Github网址:https://github.com/openai/tiktoken
- tiktoken-calculator: https://huggingface.co/spaces/JacobLinCool/tiktoken-calculator
- How_to_count_tokens_with_tiktoken.ipynb: https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb