最近达摩院放出了目前最能打的yolo算法,时间和精度都得到了提升

目前代码已经开源:
代码地址:GitHub - tinyvision/DAMO-YOLO: DAMO-YOLO: a fast and accurate object detection method with some new techs, including NAS backbones, efficient RepGFPN, ZeroHead, AlignedOTA, and distillation enhancement.
代码预设仅支持分布式训练,对于硬件资源有限的小伙伴来说,算法的训练就不是太友好了,但是对于想要尝试的小伙伴还是有办法的
一、修改train中的代码
#!/usr/bin/env python
# Copyright (C) Alibaba Group Holding Limited. All rights reserved.
import argparse
import copy
import os
import torch
from loguru import logger
from damo.apis import Trainer
from damo.config.base import parse_config
from damo.utils import synchronize
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12345'
def make_parser():
"""
Create a parser with some common arguments used by users.
Returns:
argparse.ArgumentParser
"""
parser = argparse.ArgumentParser('Damo-Yolo train parser')
parser.add_argument(
'-f',
'--config_file',
default=r'G:\xxx\DAMO-YOLO\configs\damoyolo_tinynasL20_T.py', # xxx自己的路径
type=str,
help='plz input your config file',
)
parser.add_argument('--local_rank', type=int, default=0)
parser.add_argument('--tea_config', type=str, default=None)
parser.add_argument('--tea_ckpt', type=str, default=None)
parser.add_argument(
'opts',
help='Modify config options using the command-line',
default=None,
nargs=argparse.REMAINDER,
)
return parser
@logger.catch
def main():
args = make_parser().parse_args()
torch.cuda.set_device(args.local_rank)
# torch.distributed.init_process_group(backend='nccl', init_method='env://', world_size=torch.cuda.device_count(), rank=args.local_rank)
try:
world_size = torch.cuda.device_count() # int(os.environ["WORLD_SIZE"])
rank = args.local_rank # int(os.environ["RANK"])
# distributed.init_process_group("nccl")
torch.distributed.init_process_group("gloo",rank=rank,world_size=world_size)
except KeyError:
world_size = torch.cuda.device_count()
rank = args.local_rank
torch.distributed.init_process_group(
backend="nccl",
init_method='env://',
rank=rank,
world_size=world_size,
)
synchronize()
if args.tea_config is not None:
tea_config = parse_config(args.tea_config)
else:
tea_config = None
config = parse_config(args.config_file)
config.merge(args.opts)
trainer = Trainer(config, args, tea_config)
trainer.train(args.local_rank)
if __name__ == '__main__':
main()
1、增加
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12345'
否则会报:
ValueError: Error initializing torch.distributed using env:// rendezvous: environment variable MASTER_ADDR expected, but not set
or
ValueError: Error initializing torch.distributed using env:// rendezvous: environment variable MASTER_PORT expected, but not set
2、windows不支持nccl backbone所以init_process_group中改为‘gloo’
二、改配置configs\xxx.py
如damoyolo_tinynasL20_T.py找到代码17行的
self.train.batch_size = 256 --->调小即可
ps:建议设置为8, 训练过程中占用显存较大
三、改数据集路径
damo\config\paths_catalog.py
找到代码的第8行修改
DATA_DIR = r'G:\xxx\train_data'
同时还要修改第38行的路径,改成绝对路径即可,否则也会报如下错误
ImportError: G:\xxx\DAMO-YOLO\configs\damoyolo_tinynasL20_T.py doesn't contains class named 'Config'
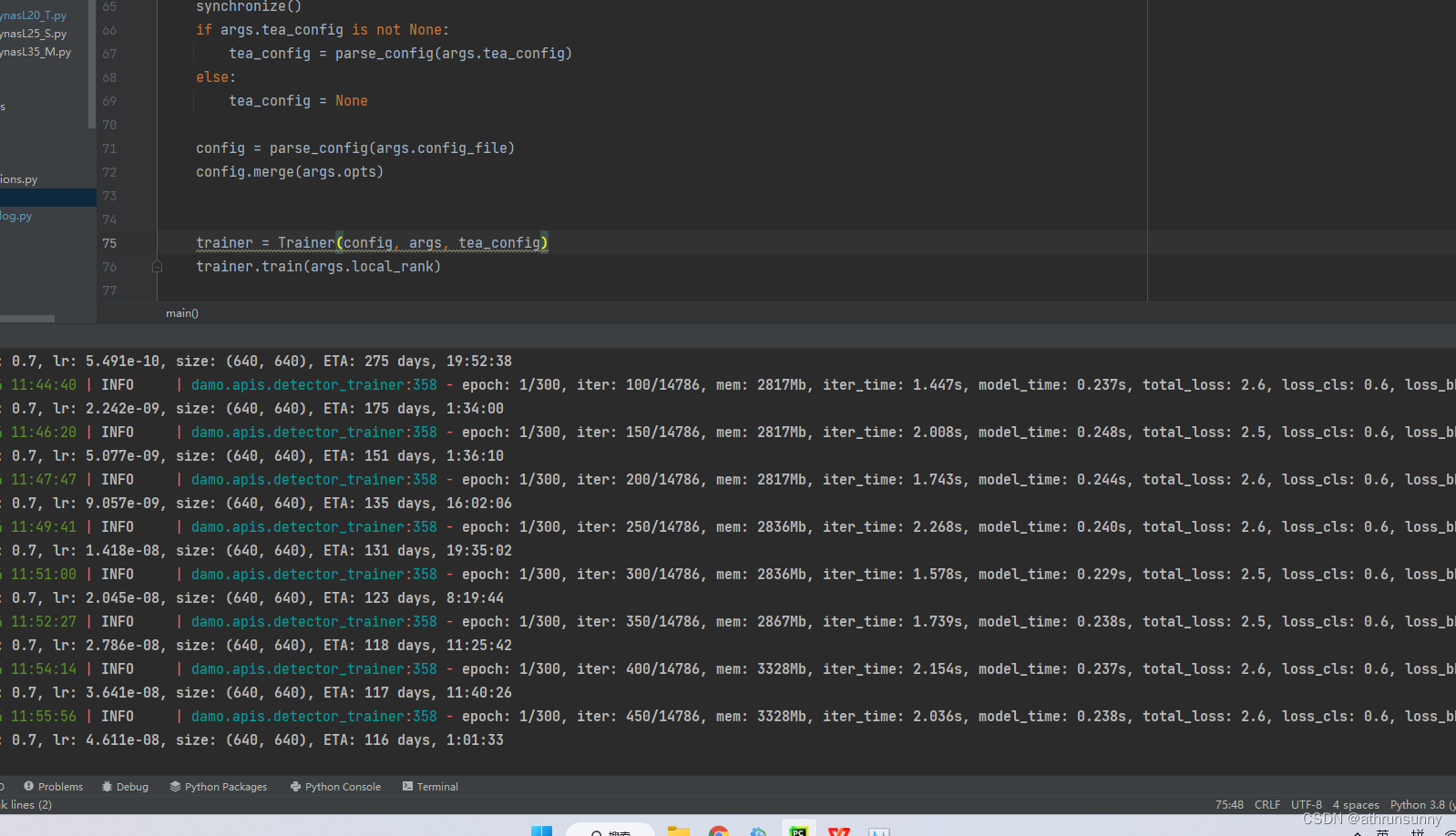
到这里基本上就能在windows端使用单卡运行起来了




![[附源码]JAVA毕业设计框架的电脑测评系统(系统+LW)](https://img-blog.csdnimg.cn/28d7120757514faab44a7c785fac3ffe.png)



![[附源码]计算机毕业设计基于Springboot的物品交换平台](https://img-blog.csdnimg.cn/9a871b2a856548ce8269de27954d50fd.png)

