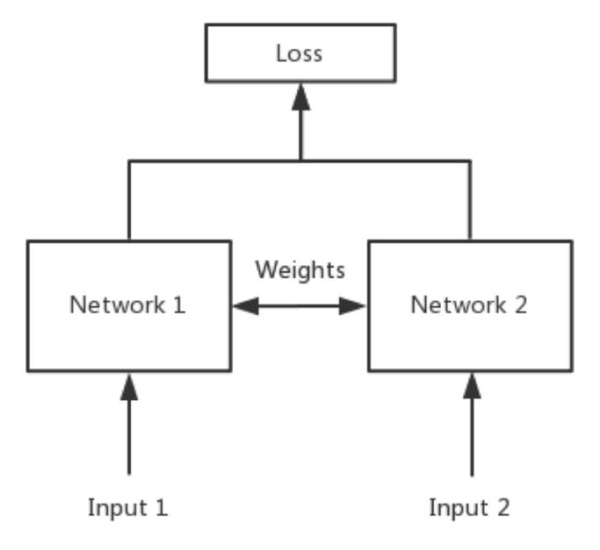
孪生神经网络
孪生神经网络(Siamese network)主要用途是比较两图片的相似程度,其核心思想就是权值共享。
卷积神将网络是通过卷积运算提取图像的特征进行训练的,如果想比较两个图像的相似程度,也要对两个图像分别进行特征提取,只判断特征的相似度就可以了。然而不同的卷积核运算后得到的特征很有可能不在一个域中,所以要使用同一个网络进行特征提取。
孪生神经网络的优点:对于类别不平衡问题鲁棒性更强,更易于做集成学习,可以从语义相似性上学习来估测两个输入的距离。
孪生神经网络的缺点,由于有两个输入,两个子网,其训练相对于常规网络运算量更大,需要的时间更长。输出的结果是两个类间的距离而不是概率
训练过程
训练集
孪生神经网络不需要每一类都有很多图片,其训练集叫做support set,数据集的类别可以很多,每个类别只需几张图片即可。
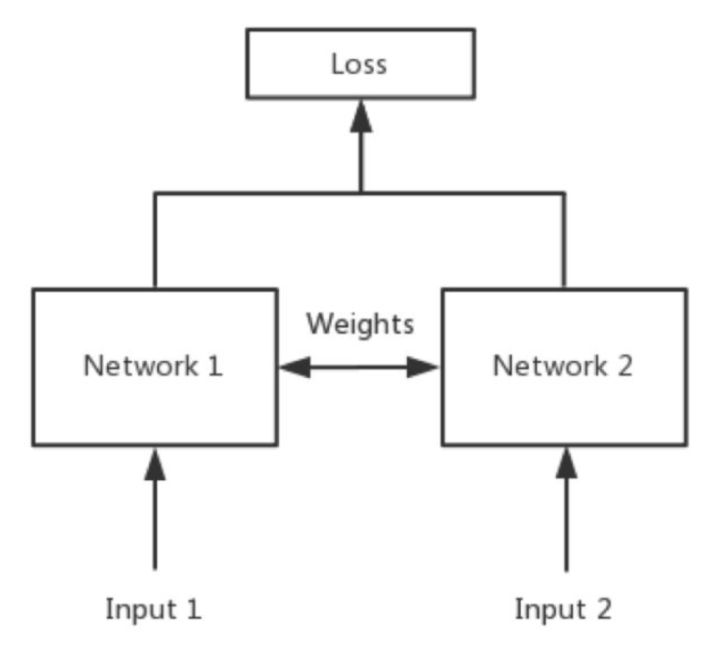
首先选择一个神经网络f,对输入图像进行特征提取,提取结果为h1和h2,z表示两个向量之间的区别,再加上全连接层处理z向量,最后用sigmoid函数输出为一个标量(如果两个图片是同一类,则输出应该接近1,如果不是同一类则应该接近0)。
损失函数
`Triplet Loss
Triplet Loss三元组损失函数,其应用见谷歌2015年发表在CVPR上的做人脸验证的论文facenet。该损失函数定义一个三元组作为输入,分别是
(
X
a
n
c
h
o
r
,
X
p
o
s
i
t
i
v
e
,
X
n
e
g
a
t
i
v
e
)
(X_{anchor},X_{positive},X_{negative})
(Xanchor,Xpositive,Xnegative)
这三个输入的通过如下方式构成,先从训练数据集中随机选一个样本作为Anchor,再随机选取一个和Anchor属于同一类的样本作为正样本
X
p
o
s
i
t
i
v
e
X_{positive}
Xpositive,和一个不同类的样本作为负样本
X
n
e
g
a
t
i
v
e
X_{negative}
Xnegative ,通过这种方式定义一个输入的三元组
X
a
n
c
h
o
r
,
X
p
o
s
i
t
i
v
e
,
X
n
e
g
a
t
i
v
e
X_{anchor},X_{positive},X_{negative}
Xanchor,Xpositive,Xnegative,将其输入到网络可以得到对应的特征向量
[
f
(
X
a
n
c
h
o
r
)
,
f
(
X
p
o
s
i
t
i
v
e
)
,
f
(
X
n
e
g
a
t
i
v
e
)
]
[f(X_{anchor}),f(X_{positive}),f(X_{negative})]
[f(Xanchor),f(Xpositive),f(Xnegative)]
Triplet Loss的目的是通过训练,使得同种类别的距离更近,不通类别的距离更大,即拉近anchor与positive;推远anchor和negative。
通过这种相似度比较式的学习,模型不仅与同类别更像,还学会了与不同类别增大区分度的信息。通常定义一个 α \alpha α,使得Anchor距离Negative的距离比距离Positive大 α \alpha α, 公式化表示为:
∣ f ( X a n c h o r ) − f ( X n e g a t i v e ) ∣ ∣ − ∣ ∣ f ( X a n c h o r ) − f ( X p o s i t i v e ) ∣ ∣ > α |f(X_{anchor}) - f(X_{negative})|| - ||f(X_{anchor}) - f(X_{positive})|| \gt \alpha ∣f(Xanchor)−f(Xnegative)∣∣−∣∣f(Xanchor)−f(Xpositive)∣∣>α
定义为:
L ( X a n c h o r , X p o s i t i v e , X n e g a t i v e ) = m a x ( ∣ ∣ f ( X a n c h o r ) − f ( X p o s i t i v e ) ∣ ∣ − ∣ ∣ f ( X a n c h o r ) − f ( X n e g a t i v e ) ∣ ∣ + α , 0 ) L(X_{anchor}, X_{positive}, X_{negative}) = max(||f(X_{anchor}) - f(X_{positive})|| - ||f(X_{anchor}) - f(X_{negative})|| + \alpha, 0) L(Xanchor,Xpositive,Xnegative)=max(∣∣f(Xanchor)−f(Xpositive)∣∣−∣∣f(Xanchor)−f(Xnegative)∣∣+α,0)
Contrastive Loss
Contrastive Loss的输入是一对样本,基于相似的一对对象特征距离应该更小,不相似的一对对象特征距离应该较大来计算。从数据中选一对样本 ( X a , X b ) (X_a, X_b) (Xa,Xb),这两个样本的欧式距离表示为$d=||X_a-X_b||_2=\sqrt{({X_a-X_b})^2}d=∣∣X $
则Contrastive Loss可表示为:
L
(
X
a
,
X
b
)
=
(
1
−
Y
)
1
2
d
2
+
Y
1
2
{
m
a
x
(
0
,
m
−
d
)
}
2
L(X_a,X_b) = (1-Y)\frac{1}{2}d^2 + Y\frac{1}{2}\{max(0, m-d)\}^2
L(Xa,Xb)=(1−Y)21d2+Y21{max(0,m−d)}2
Y表示 X a , X b ) X_a,X_b) Xa,Xb)是否匹配,匹配为1不匹配为0
m是设置的安全距离,当 ( X a , X b ) (X_a, X_b) (Xa,Xb)的距离小于m 时,Contrasive Loss将变成0,这使得 X a X_a Xa
与 X b X_b Xb 相似而不是相同,能保证算法的泛化能力
有了损失函数就可以通过反向传播进行参数更新了


![[附源码]JAVA毕业设计框架的电脑测评系统(系统+LW)](https://img-blog.csdnimg.cn/28d7120757514faab44a7c785fac3ffe.png)



![[附源码]计算机毕业设计基于Springboot的物品交换平台](https://img-blog.csdnimg.cn/9a871b2a856548ce8269de27954d50fd.png)


![[附源码]Python计算机毕业设计Django抗疫医疗用品销售平台](https://img-blog.csdnimg.cn/e5d393bbff274b15946da187968d683a.png)