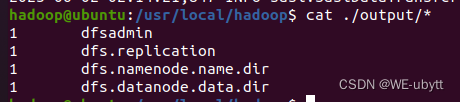
一.安装Kafka
1.1下载安装包
通过百度网盘分享的文件:复制链接打开「百度网盘APP 即可获取」
链接:https://pan.baidu.com/s/1vC6Di3Pml6k1KMbnK0OE1Q?pwd=huan
提取码:huan
也可以访问官网,下载kafka2.4.0的安装文件
1.2解压到“D:\”目录下
因为Kafka的运行依赖于 Zookeeper,因此,还需要下并安装Zookeeper,当然Kafka也内置了Zookeeper服务,因此,也可以不额外安装Zookeep,直接使用内置的Zookeeper服务。
这里为简单起见,直接使用Kafka内置的Zookeeper服务
二.使用Kafka
2.1启动zookeeper
2.1.1新建第一个cmd命令窗口
在Windows操作系统中找到解压的kafka_2.12-2.4.0
在这里输入cmd--->然后回车
会出现一个小黑窗(黑窗口1)
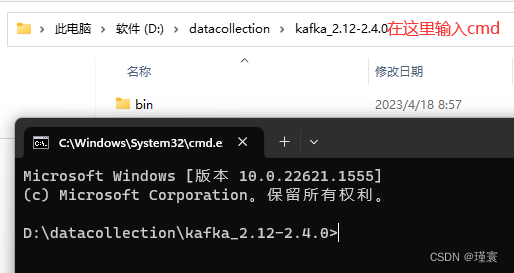
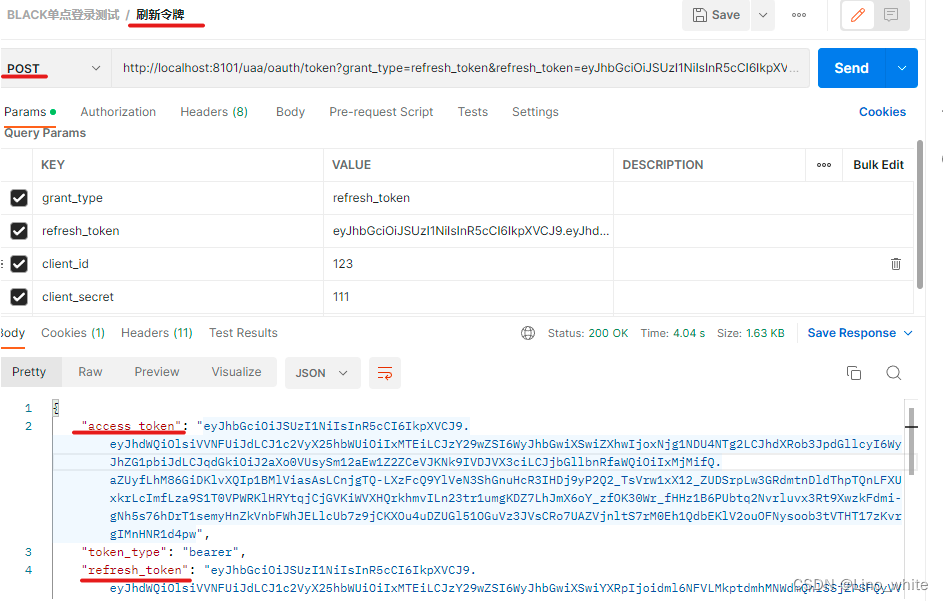
2.1.2在黑窗中1中输入.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties然后回车
出现下图表示zookeeper启动成功

2.2启动Kafka
2.2.1新建第二个cmd命令窗口
在Windows操作系统中找到解压的kafka_2.12-2.4.0(这里跟上面是一样的)
在这里输入cmd--->然后回车
会出现一个小黑窗(黑窗口2)
2.2.2在小黑窗2中输入.\bin\windows\kafka-server-start.bat .\config\server.properties然后回车(注:跟启动zookeeper的命令不一样)
出现下图表示Kafka启动成功

[注意:两个小黑窗都不能关闭]
2.3创建名为“test004”的主题,其包含一个分区,只有一个副本
2.3.1新建第三个cmd命令窗口
在Windows操作系统中找到解压的kafka_2.12-2.4.0(跟上面的一样)
在这里输入cmd--->然后回车
会出现一个小黑窗(黑窗口3)
2.3.1.1在小黑窗3中输入.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test004然后回车
(若出现Created topic topic_test001表示成功)
2.3.2查看是否创建成功
在黑窗口3中输入.\bin\windows\kafka-topics.bat -list -zookeeper localhost:2181然后回车
如果显示有test004表示创建成功

三、安装Flume
1.1访问Flume的官网(http://flume.apache.org/download.html),下载Flume安装apache-flume-1.9.0-bin.tar.gz。或者下载我的百度网盘资源。把安装文件解压缩到windows操作“D:\”目录下,然后执行如下命令测试是否安装成功:
>e: 切换盘符
> cd E:\bigdataCol\apache-flume-1.9.0-bin\bin 切换到flume的bin目录
> flume-ng version 执行该命令测试
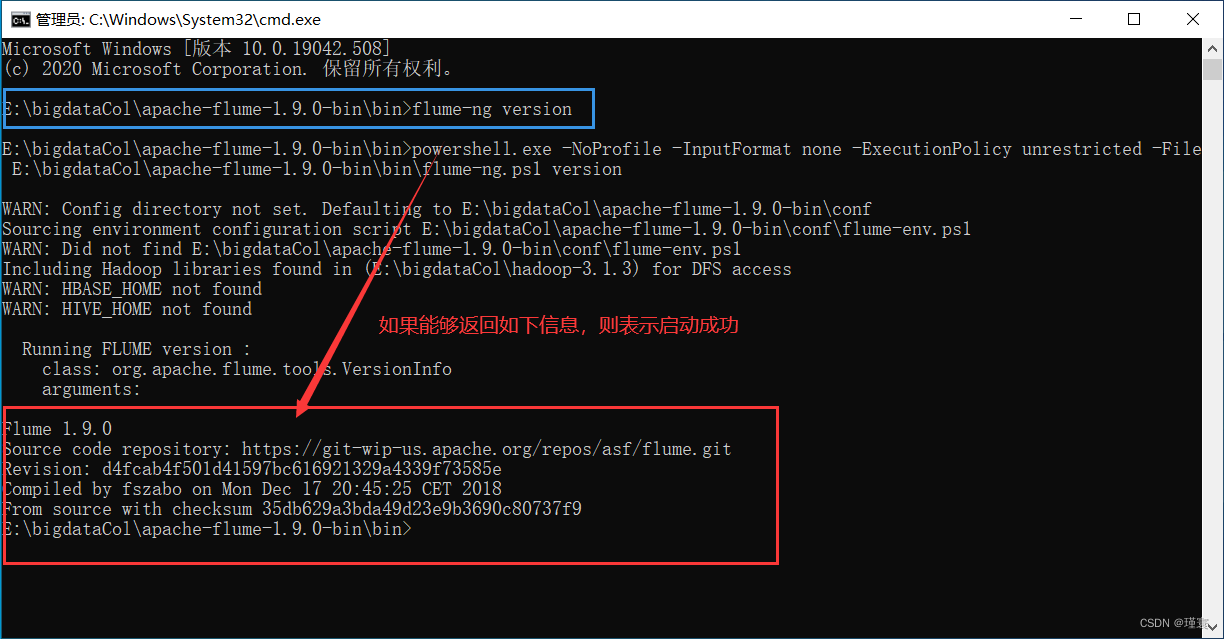
如果启动中提示PathNotFount: java.exe,则需要配置java的环境变量,JAVA_HOME=java的安装路径,在Path中配置%JAVA_HOME%\bin。注意:java的安装路径中尽量不要有空格。
1.2在Flume的安装目录的conf子目录下创建一个配置文件kafka.conf,内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
1.3打开第4个cmd窗口,执行如下命令启动Flume:
> cd E:\bigdataCol\apache-flume-1.9.0-bin
> .\bin\flume-ng agent --conf .\conf --conf-file .\conf\kafka.conf --name a1 -property flume.root.logger=INFO,console

1.4打开第5个cmd窗口,执行如下命令:
> telnet localhost 44444
执行上面命令以后,在该窗口内用键盘输入一些单词,比如“hadoop”。这个单词会发送给Flume,然后,Flume发送给Kafka。

1.5打开第6个cmd窗口,执行如下命令:
>cd E:\bigdataCol\kafka_2.12-2.4.0
>.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
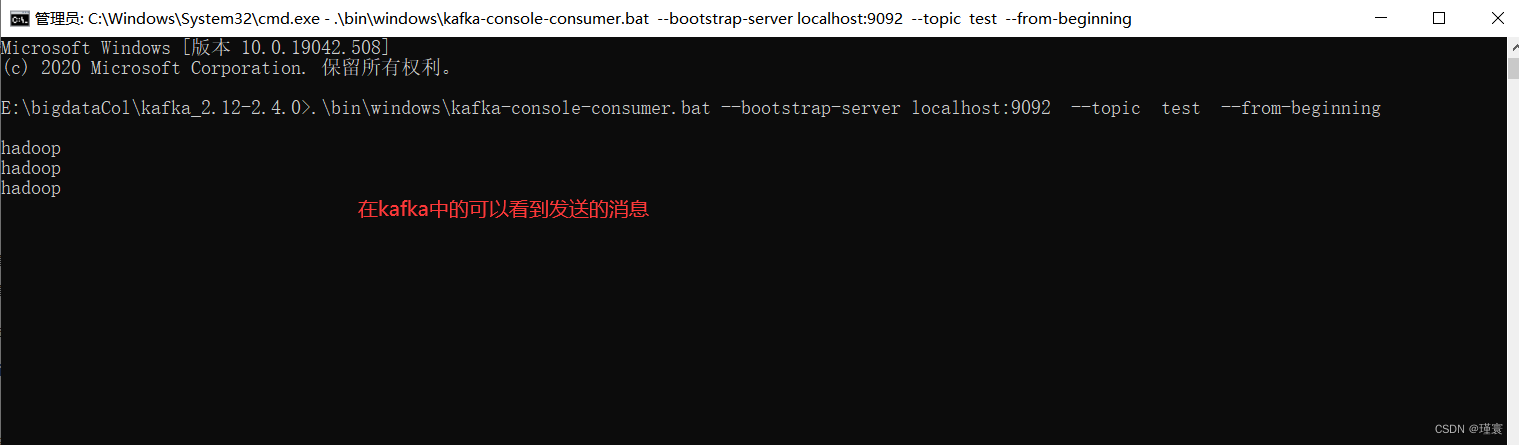
执行成功后在kafka中可以看到hadoop