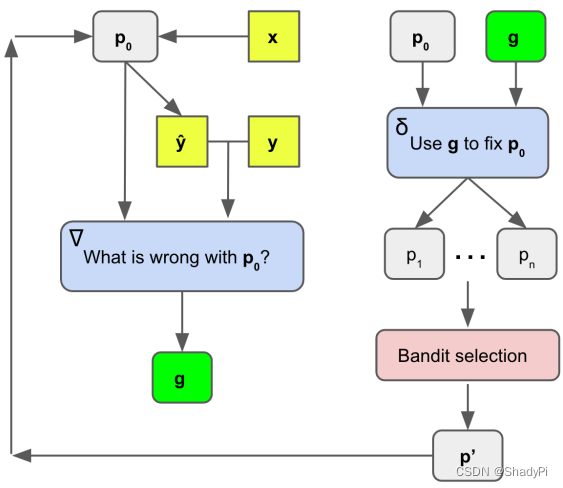
在“自然语言域”使用类似梯度下降的方法优化prompt
整篇文章比较精髓的思想在于
- 利用LLM本身去寻找prompt的瑕疵。将语言模型的输出 y ^ \hat{y} y^与正确答案(label) y y y还有prompt p p p 一起送入LLM,并通过类似“What is wrong with p p p? ”这样的问题让LLM自己找出prompt的问题所在,并将这次输出当作prompt在“自然语言域”的“梯度” g g g。
- 根据梯度 g g g让LLM自己对prompt做调整。把 p , g p, g p,g一起输入给LLM,并通过类似 “Use g g g to fix p p p”的指令让LLM生成新的prompt。原文在此基础之上,还使用LLM多次paraphrase新的prompt从而“拓宽蒙特卡洛搜索空间”。
- 结合Beam search和Bandit selection在生成的新prompt里寻找最优解。每次做完前面所述的1.2.两步以后,就会产生许多候选prompt,文章使用beam search的方式,每次用bandit selection找到比较好的几个prompt,在此基础之上继续迭代,若干次后挑选其中最好的prompt。
Beam search过程

B
i
B_i
Bi为每个beam search步产生的prompt候选集,
C
C
C是储存候选集的临时变量。(PS:这里的
i
i
i是不是该从0开始来着)
在每个搜索步中,先对当前步的候选集 B i B_i Bi中的每个prompt做一次Expand操作,扩充候选集。Expand过后用Select算法进行筛选,找到最好的 b b b个保留到下一步的候选集里。最后从 B r B_r Br挑出最好的prompt。
Expand

第一步,从整个训练集
D
t
r
\mathcal{D_{tr}}
Dtr中抽出一个小样本集合
D
m
i
n
i
\mathcal{D_{mini}}
Dmini,。
第二步,
D
m
i
n
i
\mathcal{D_{mini}}
Dmini进行测试,把出错的样本收集起来,称为有错的样例集合
e
e
e。
第三步,将
p
,
e
p, e
p,e一起送入LLM让LLM挑错,得到
g
g
g。
第四步,将
p
,
g
,
e
p,g,e
p,g,e送入LLM让LLM优化
p
p
p,得到
p
′
p'
p′。
第五步,paraphase
p
′
p'
p′,得到
p
′
′
p''
p′′。
第六步,
p
′
,
p
′
′
p',p''
p′,p′′一起送回去。
Select
本文把选择看作了一个“多臂老虎机”问题,可以参考这篇文章。简单说来,每个生成的新prompt就像老虎机的摇臂,可能会带来收益,但收益的分布是不确定的。多臂老虎机问题就是通过最少次“拉臂”操作找到带来收益最高的摇臂。放到这个prompt optimization问题里,拉臂操作就是以新的prompt作为输入做一次实验看效果,要做到用最少的实验找到最好的prompt。
本文描述了两种多臂老虎机问题的算法,UCB和Successive Rejects

均值越大,标准差越小,被选中的概率会越来越大。

简单理解就是打淘汰赛。
实验
在4个数据集上做了实验,都是偏向网络安全类的,而且都是分类问题。
Jailbreak:用户尝试绕过LLM的一些安全限制
Ethos:辨别英语仇恨言论
Liar:辨别英语fake news
Sarcasm:辨别阿拉伯语讽刺言论
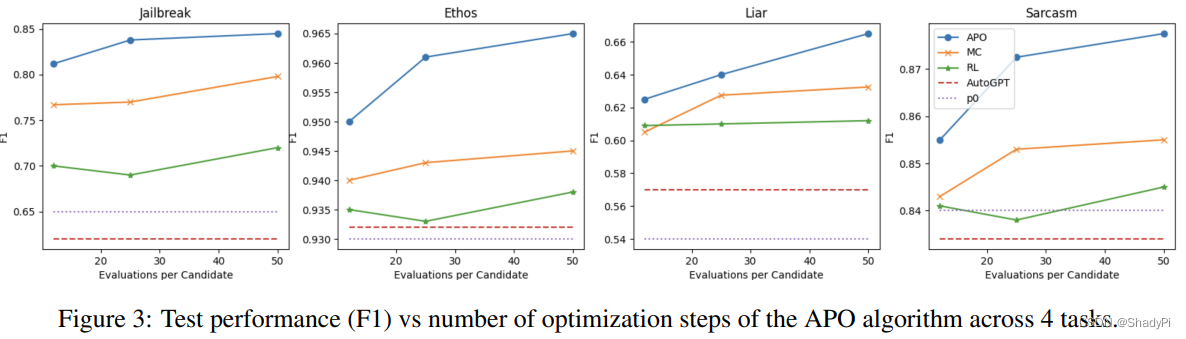
看上去是吊打Monte-Carlo (MC),Reinforcement Learning (RL)和AutoGPT。

Beam search有效果,比
r
=
1
r=1
r=1(No iteration)和
b
=
1
b=1
b=1(Greedy)要好。
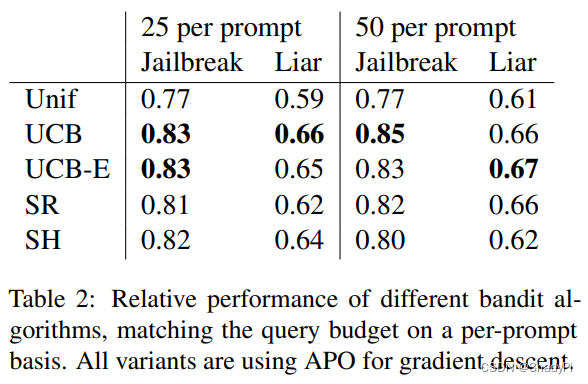
又比了几个多臂老虎机算法,UCB和其变种UCB-E好。
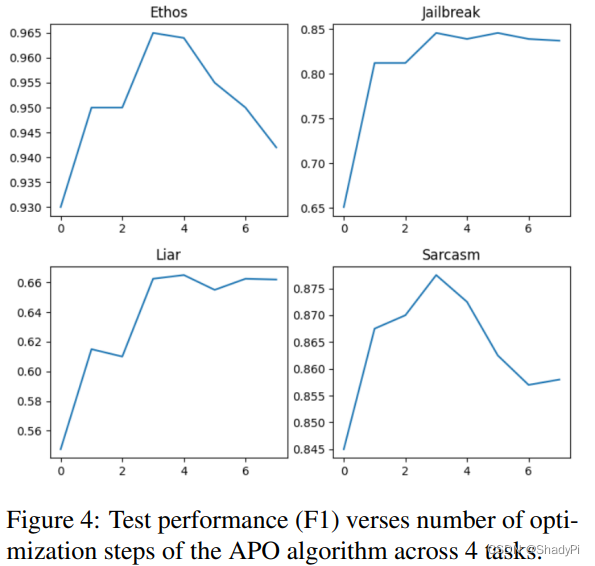
学习曲线表明这玩意儿很容易过拟合,整个流程跑3遍差不多就到最优了。
一些优化结果展示: