-
OpenMMLab 是一个用于学术研究和工业应用的开源算法体系,于2018年年中开始,由 MMLab(香港中文大学多媒体实验室)和商汤科技联合启动。
-
如果第一接触的话,还是建议参考官方环境配置教程:Windows 环境配置 - OpenMMLab 贡献者成长体系教程
-
安装之前,首先需要明确自己的配置信息:
-
操作系统(windows,Linux,macOS等)
-
是否是台式(notebook显卡和独立显卡是有区别的,尽管型号相同也有可能需要配置不同的cuda版本);
-
GPU(一般为N卡,根据型号到英伟达官网查看对应CUDA版本以及CUDAToolkit信息,显卡驱动信息,显存建议6G起步);
-
CPU(虽然GPU做了大部分运算,一块较好的CPU非常有必要)…
-
-
python,pytorch,cuda,CUDAToolkit,显卡驱动版本,mmcv,mmXXX需要版本对应(细致且繁杂)。
-
安装顺序依次为:python,pytorch,mmcv,按需求选择对应的算法库。
-
-
严格来说其实openmmlab还算不上框架,更像是第三方库,基于pytorch结合设计模式做的一个开源工程,它有以下特点:
-
模块化组合设计。将网络框架分解为不同组件,将数据集构建、模型搭建、训练过程设计等过程封装为模块,在统一而灵活的架构上,用户能够轻松组合调用不同的模块,构建自定义计算机视觉网络框架;
-
高性能。基于底层库MMCV,OpenMMLab中几乎所有基本运算操作都在GPU上运行,训练速度快;
-
可扩展性强。开源框架中集成计算机视觉各个领域最新的先进算法,并且不断更新,使用者能够轻松使用新方法并进行改进。OpenMMLab系列项目的核心组件是MMCV,它是用于计算机视觉研究的基础Python库,支持OpenMMLab旗下其他开源库,是上述一系列上层框架的基础支持库,提供底层通用组件,灵活性强,可扩展性好。
-
-
OpenMMLab 不仅实现并开源了许多前沿的人工智能模型,MMDeploy 将强势打通从算法模型到应用程序这 “最后一公里”!模型部署是指把机器学习训练生成的算法模型,部署到各类云、边、端设备上去, 并使之高效运行,从而将算法模型实际地应用到现实生活中的各类任务中去,从而实现AI+的智能化转型。GitHub 链接:open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework (github.com)
-
• 全面对接 OpenMMLab 各算法体系,提供算法快速落地的通道 • 建立了统一管理、高效运行、多后端支持的模型转换框架 • 实现了高度可扩展的组件式 SDK 开发框架 • 拥有灵活、开放、多样化的输出,满足不同用户的需求
-
-
模型部署:
-
模型部署:指把训练好的模型在特定环境中运行的过程。MMDeploy实现了OpenMMLab中目标检测、图像分割、超分辨率等多个视觉任务模型的部署,支持ONNX Runtime,TensorRT,ncnn,openppl,OpenVINO等多个推理引擎。
-
模型部署的常见流水线是"深度学习框架–中间表示–推理引擎"。其中比较常用的一个中间表示是ONNX。
-
深度学习模型实际上就是一个计算图。模型部署时通常把模型转换成静态的计算图,即没有控制流(分支语句、循环语句)的计算图。
-
PyTorch框架自带对ONNX的支持,只需要构造一组随机的输入,并对模型调用torch.onnx.export即可完成PyTorch到ONNX的转换。
-
推理引擎ONNX Runtime对ONNX模型有原生的支持。给定一个.onnx文件,只需要简单使用ONNX Runtime的Python API就可以完成模型推理。
-
模型部署中常见的几类困难有:模型的动态化;新算子的实现;框架间的兼容。
-
PyTorch转ONNX,实际上就是把每一个操作转化成ONNX定义的某一个算子。比如对于PyTorch中的Upsample和interpolate,在转ONNX后最终都会成为ONNX的Resize算子。
-
通过修改继承自torch.autograd.Function的算子的symbolic方法,可以改变该算子映射到ONNX算子的行为。
-
-
MMDeploy 以各算法库的模型为输入,把模型转换成推理后端要求的模型格式,运行在多样的设备中。从具体模块组成看,MMDeploy 包含 2 个核心要素:模型转换器 ( Model Converter ) 和应用开发工具包(SDK)。千行百业智能化落地,MMDeploy 助你一“部”到位 - 知乎 (zhihu.com)
-
模型转换器的具体步骤为:
-
把 PyTorch 转换成 ONNX 模型;
-
对 ONNX 模型进行优化;
-
把 ONNX 模型转换成后端推理引擎支持的模型格式;
-
把模型转换中的 meta 信息和后端模型打包成 SDK 模型(可选)。
-
-
在传统部署流水线中,兼容性是最难以解决的瓶颈。针对这些问题,MMDeploy 在模型转换器中添加了模块重写、模型分块和自定义算子这三大功能:
-
针对部分 Python 代码无法直接转换成 ONNX 的问题,MMDeploy 使用重写机制实现了函数、模块、符号表等三种粒度的代码替换,有效地适配 ONNX。
-
针对部分模型的逻辑过于复杂,在后端里无法支持的问题,MMDeploy 使用了模型分块机制,能像手术刀一样精准切除掉模型中难以转换的部分,把原模型分成多个子模型,分别转换。这些被去掉的逻辑会在 SDK 中实现。
-
OpenMMLab 实现了一些新算子,这些算子在 ONNX 或者后端中没有支持。针对这个问题,MMDeploy 把自定义算子在多个后端上进行了实现,扩充了推理引擎的表达能力。
-
-
应用开发工具包 SDK
-
在设计阶段,我们定义了 MMDeploy 两个核心功能:模型转换、C/C++推理(即 SDK)。在实现方法上,大量使用了工厂模式和 Adapter 模式,做好模块封装,消除推理引擎、设备差异。
-
MMDeploy 高度模块化。可以被当作一个整体,进行端到端的模型部署。也可以只使用其中的部分模块,灵活地服务自己的项目或者产品。
-
适用场景:快速搭建模型部署 demo,验证部署结果的正确性。如下面的例子所示,输入匹配的部署配置、算法配置、checkpoint、图像、工作目录等,即可通过一条命令将 torch 模型转换为推理引擎要求的模型格式。目前,MMDeploy 支持了 6 种推理引擎:TensorRT、ONNXRuntime、PPL.NN、ncnn、OpenVINO 和 libtorch。执行示例命令
-
# 将 MMDet 中的 Faster-RCNN 模型,转换为 TensorRT engine 格式 ## ${MMDEPLOY_DIR}: git clone mmdeploy 后,源码存放的路径 ## ${MMDET_DIR}: git clone mmdetection 后,源码存放的路径 ## ${CHECKPOINT_DIR}: 存放 checkpoint 的目录 ## ${INPUT_IMG}: 一张图像的路径 ## ${WORK_DIR}: 用来存放转换结果的目录 python ${MMDEPLOY_DIR}/tools/deploy.py \ ${MMDEPLOY_DIR}/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py \ ${MMDET_DIR}/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \ ${CHECKPOINT_DIR}/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ ${INPUT_IMG} \ --work-dir ${WORK_DIR} \ --device cuda:0 \ --dump-info
-
-
MMDeploy 定义的模型部署流程,如下图所示:操作概述 — mmdeploy 1.1.0 文档
-

-
支持的平台及设备
-

-
Linux-x86_64:mmdeploy/get_started.md at master · open-mmlab/mmdeploy · GitHub
-
# 1. install MMDeploy model converter pip install mmdeploy==0.14.0 # 2. install MMDeploy sdk inference # you can install one to install according whether you need gpu inference # 2.1 support onnxruntime pip install mmdeploy-runtime==0.14.0 # 2.2 support onnxruntime-gpu, tensorrt pip install mmdeploy-runtime-gpu==0.14.0 # 3. install inference engine # 3.1 install TensorRT # !!! If you want to convert a tensorrt model or inference with tensorrt, # download TensorRT-8.2.3.0 CUDA 11.x tar package from NVIDIA, and extract it to the current directory pip install TensorRT-8.2.3.0/python/tensorrt-8.2.3.0-cp38-none-linux_x86_64.whl pip install pycuda export TENSORRT_DIR=$(pwd)/TensorRT-8.2.3.0 export LD_LIBRARY_PATH=${TENSORRT_DIR}/lib:$LD_LIBRARY_PATH # !!! Moreover, download cuDNN 8.2.1 CUDA 11.x tar package from NVIDIA, and extract it to the current directory export CUDNN_DIR=$(pwd)/cuda export LD_LIBRARY_PATH=$CUDNN_DIR/lib64:$LD_LIBRARY_PATH # 3.2 install ONNX Runtime # you can install one to install according whether you need gpu inference # 3.2.1 onnxruntime wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-1.8.1.tgz tar -zxvf onnxruntime-linux-x64-1.8.1.tgz export ONNXRUNTIME_DIR=$(pwd)/onnxruntime-linux-x64-1.8.1 export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH # 3.2.2 onnxruntime-gpu pip install onnxruntime-gpu==1.8.1 wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-gpu-1.8.1.tgz tar -zxvf onnxruntime-linux-x64-gpu-1.8.1.tgz export ONNXRUNTIME_DIR=$(pwd)/onnxruntime-linux-x64-gpu-1.8.1 export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH -
Windows-x86_64:mmdeploy/prebuilt_package_windows.md at master · open-mmlab/mmdeploy · GitHub
-
-
TorchScript是PyTorch模型(torch.nn.Module的子类)的中间表示,是一种从PyTorch代码创建可序列化和可优化模型的方法,可以在C++等高性能环境(high-performance environment)中运行。任何TorchScript程序都可以从Python进程中保存并加载到没有Python依赖项的进程中。
-
torch.onnx.export中需要的模型实际上是一个torch.jit.ScriptModule。而要把普通PyTorch模型转一个这样的TorchScript模型,有跟踪(trace)和脚本化(script)两种导出计算图的方法。如果给torch.onnx.export传入了一个普通PyTorch模型(torch.nn.Module),那么这个模型会默认使用跟踪的方法导出。
-
跟踪法只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环);脚本化则能通过解析模型来正确记录所有的控制流。
-
函数torch.onnx.export的声明如下:
-
def export(model, args, f, export_params=True, verbose=False, training=None, input_names=None, output_names=None, operator_export_type=None, opset_version=None, do_constant_folding=True, dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None, export_modules_as_functions=False) -
前三个必选参数为模型、模型输入、导出的onnx文件名。
-
exprot_params:模型中是否存储模型权重。一般中间表示包含两大类信息:模型结构和模型权重,这两类信息可以在同一个文件里存储,也可以分文件存储。ONNX是用同一个文件表示记录模型的结构和权重。部署时一般都默认这个参数为 True。如果onnx文件是用来在不同框架间传递模型(比如PyTorch到Tensorflow)而不是用于部署,则可以令这个参数为False。
-
input_names, output_names:设置输入和输出张量的名称。如果不设置的话,会自动分配一些简单的名字(如数字)。ONNX模型的每个输入和输出张量都有一个名字。很多推理引擎在运行ONNX文件时,都需要以"名称–张量值"的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证ONNX和推理引擎中使用同一套名称。
-
opset_version:转换时参考哪个ONNX算子集版本,onnx/Operators.md at main · onnx/onnx · GitHub。
-
dynamic_axes:指定输入输出张量的哪些维度是动态的。为了追求效率,ONNX默认所有参与运算的张量都是静态的(张量的形状不发生改变)。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。因此,我们需要显式地指明输入输出张量的哪几个维度的大小是可变的。
-
ONNX在底层是用Protobuf定义的。Protobuf,全称Protocol Buffer,是Google提出的一套表示和序列化数据的机制。一个ONNX模型可以用ModelProto类表示。ModelProto包含了版本、创建者等日志信息,还包含了存储计算图结构的graph。GraphProto类则由输入张量信息、输出张量信息、节点信息组成。张量信息ValueInfoProto类包括张量名、基本数据类型、形状。节点信息NodeProto类包含了算子名、算子输入张量名、算子输出张量名。
-
ONNX中的onnx.utils.extract_model()可以从原模型中取出部分节点,和新定义的输入、输出边构成一个新的子模型。利用子模型提取功能,我们可以输出原ONNX模型的中间结果,实现对ONNX模型的调试。
-
使用conda安装一个mmdeploy的虚拟环境,ONNX Runtime仅支持CPU,TensorRT仅支持CUDA。
-
在linux上通过源码编译mmdeploy要求:
-
安装cmake:版本>=3.14.0;fengbingchun/PyTorch_Test: PyTorch’s usage (github.com)
-
安装gcc 7+:mmdeploy sdk中使用了C++17特性,因此需要安装gcc 7+以上的版本;
-
安装依赖包:conda、pytorch(>=1.8.0)、mmcv;
-
安装mmdeploy sdk依赖:opencv(>=3.0)、pplcv(可选,仅cuda下需要);
-
安装推理引擎:onnxruntime(>=1.8.1)、tensorRT(要保证和你机器的cpu架构及cuda版本是匹配的)、cudnn(要保证和你机器的cpu架构、cuda版本及tensorrt版本是匹配的)、ppl.nn、openvino、ncnn、libtorch、cann。
-
-
树莓派就是基于Linux系统的。
再识openmmlab,用mmDeploy实现部署的前期需要了解一些内容
news2026/3/11 7:54:32

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/598990.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

Midjourney万能高清咒语,真正的近看也美
明明我都拿人家的图垫图了,为什么质量还是很差? 明明别人都把咒语分享出来了,为什么质量还是很差? 今天我们就来解决这两个问题,看到就是缘分,点点手指来个小心心不过分吧,哈哈 什么你在怀疑我的…
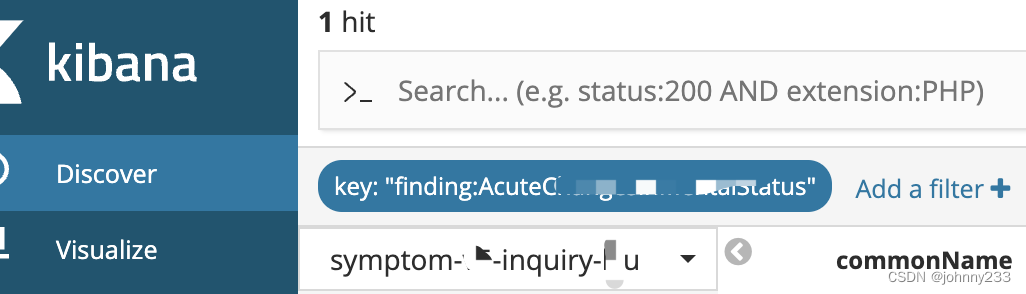
Spring Boot + ElasticSearch实战之CRUD及多数据源配置
概述
本文记录工作中使用Spring Boot ElasticSearch的实战,Spring Boot版本:2.1.6.RELEASE。
基础
Spring Boot已是Java开发标配,使用SB提供的starter,简单高效。
配置
引入依赖:
<dependency><groupI…
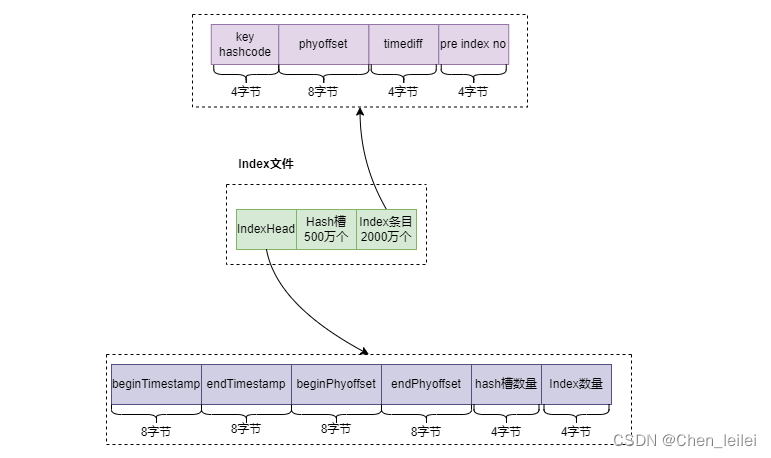
Rocketmq如何保证消息不丢失
如果想要保证消息不丢失就要知道,消息可能出现丢失得地方。 1.producer发送消息
2.Broker存储消息
3.Consumer消费消息
4.Broker主从切换
下面一共有9个维度可以保证消息不丢失。
目录
维度一:同步发送
维度二.异步发送
维度三.刷盘策略
维度四…
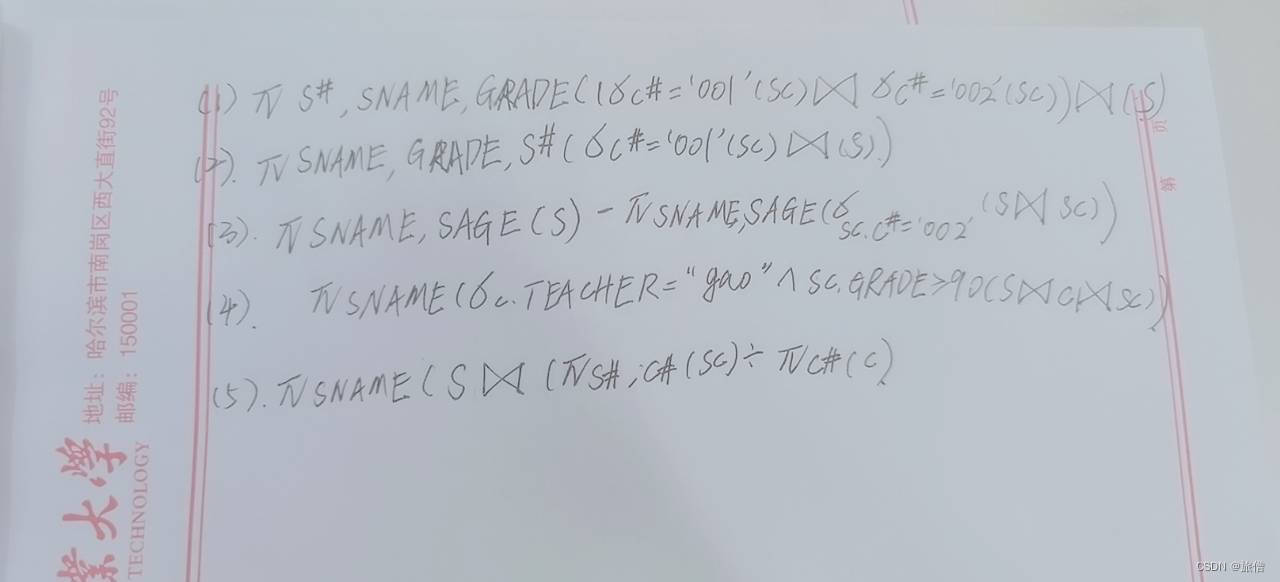
数据库期末复习(2)
关系数据库 图1 上图为思考题1的答案
\d student #查看完整性约束 模式和实例
关系的模式:关系有哪些、关系又什么类型、关系的约束时什么,一般来说关系的模式一般比较稳定,不会随着动态的变化而变化。
关系的实例:关系的实例一般随着变化的次数比较…
体验 InsCode AI,原来 AI 也扛不住互联网黑话
CSDN AI写作助手上线了!InsCode AI 创作助手不仅能够帮助用户高效创作文章,而且能够作为对话式AI回答你想知道的问题。成倍提高生产力!以下是我的体验分享
一、你平时会使用这类AI工具吗?你对这类型的工具有什么看法?…

RPC(2):RPC简介
1 RFC
RFC(Request For Comments) 是由互联网工程任务组(IETF)发布的文件集。文件集中每个文件都有自己唯一编号,例如:rfc1831。目前RFC文件由互联网协会(Internet Society,ISOC)赞助发行。
RPC就收集到了rfc 1831中。可以通过下面网址查看…
微信小程序websocket使用protobuf,发送arraybuffer
❤️砥砺前行,不负余光,永远在路上❤️ 目录 前言一、如何在小程序websocket中使用 Protobuf 发送buffer二、使用过程遇到的坑(版本问题)1、需要注意下Protobuf版本 使用 protobufjs6.8.6最好,我在使用的时候安装7.多 …
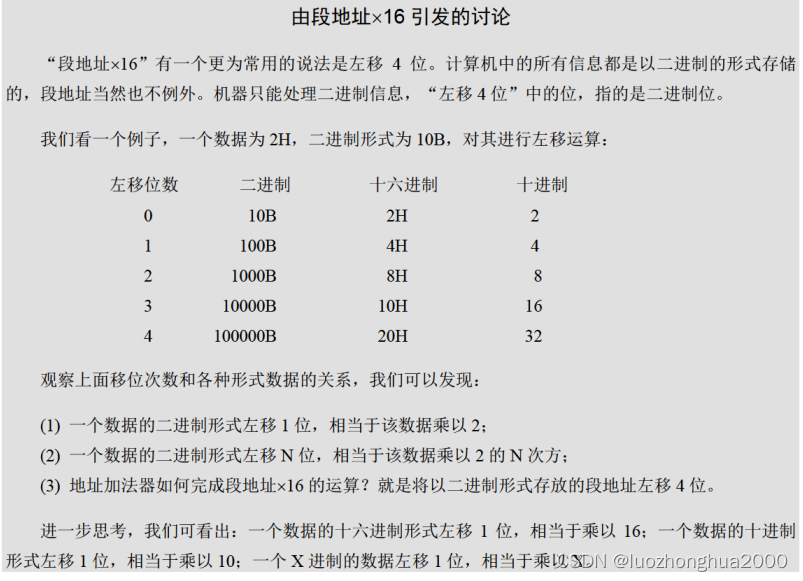
寄存器-汇编复习(2)
通过阅读本文小节内容,可以清楚的明白汇编承接的能力和机器语言,高级语言之间的表达关系。文中虽然讨论16位cpu,最新的64或以后的128理论都一样的,类推就好了。 继续将 通用寄存器-汇编复习(1)_luozhonghua2000的博客-CSDN博客 …

很多人打商标的主意,悄悄埋伏
很多人在打商标的主意,等着抢劫呢 等你的品牌结了果实,然后出手勒索 趣讲大白话:鬼子进村,打枪的不要 【趣讲信息科技183期】 **************************** 有些公司申请几千件商标 有公司一个月申请100件 春江水暖贼先知 有一条…

基于小脑模型神经网络的轨迹跟踪研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…

模拟退火算法(附简单案例及详细matlab源码)
作者:非妃是公主 专栏:《智能优化算法》 博客地址:https://blog.csdn.net/myf_666 个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩 文章目录 专栏推荐序一、概论二、物理退火1. 加温…
MyBatis - CRUD 操作
文章目录 1.环境配置1.1 导入相关依赖1.2 基本配置1.3 数据模型 2.基于 XML 开发2.1 创建 Mapper 接口2.2 创建 XML 映射文件2.3 insert2.4 select2.5 delete2.6 update2.7 编写单元测试 3.基于注解开发3.1 常用注解3.2 创建 Mapper 接口 MyBatis 支持通过 XML 和注解两种方式来…

chatgpt赋能python:Python运行程序没反应怎么办?
Python运行程序没反应怎么办?
Python作为一种高级编程语言,已经成为了很多开发者的首选语言。然而,在使用Python编写程序时,有时候会出现运行程序却没有任何反应的情况。这是什么原因导致的呢?本文将为大家介绍Python…

单例模式的饿/懒汉模式
目录 1. 什么是单例模式2. 饿汉模式2.1 饿汉模式概念2.2 饿汉模式代码 3. 懒汉模式3.1 懒汉模式概念3.2 单线程情况下的懒汉模式3.3 单例模式的写法(保证线程安全) 4. wait 和 sleep 的区别 1. 什么是单例模式
保证某个类在程序中只存在一份实例,而不会创建多个实例…

Apache Kafka - 跨集群数据镜像 MirrorMaker
文章目录 概述跨集群数据镜像的原理MirrorMaker配置小结 概述
在分布式系统中,数据镜像是一项重要的功能,它可以将数据从一个集群复制到另一个集群,以保证数据的高可用性和容错性。Apache Kafka是一个流处理平台,它提供了一种跨集…
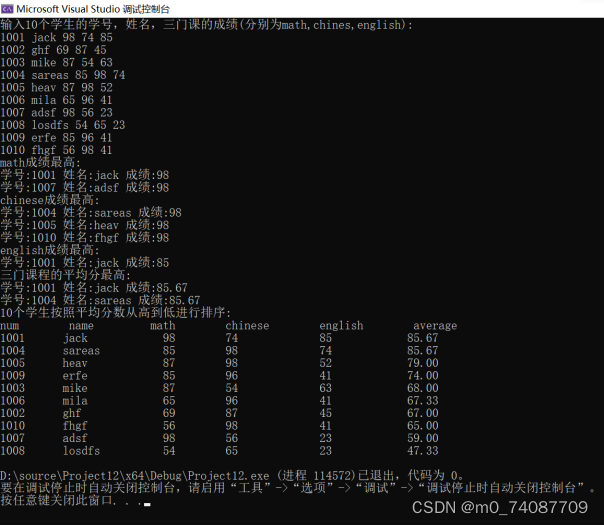
程序设计综合实习(C语言):学生成绩单制作
一、目的 1.掌握结构体变量及数组的定义、赋值、初始化、输入、输出 2.结构体数组的操作。 二、实习环境
Visual Stdio 2022
三、实习内容、步骤与要求 1.定义一个结构体数组,存放10个学生的学号,姓名,三…

Linux 设备树文件手动编译的 shell 脚本
前言 前面通过 Makefile 实现手动编译 Linux 设备树 dts 源文件及其 设备树依赖 dtsi、.h 头文件,如何写成一个 shell 脚本,直接编译呢? 其实就是 把 Makefile 重新编写为 shell 脚本即可
编译设备树 shell 脚本
脚本内容如下:…

【六一 iKun】Happy LiuYi, iKuns
六一了,放松下。
Python iKun from turtle import *
screensize(1000,1000)
speed(6)#把衣服画出来,从右肩膀开始#领子
penup()
goto(-141,-179)
pensize(3)
fillcolor("black")
pencolor("black")
begin_fill()
pendown()
left(1)…