State of GPT
- 演讲信息:
- 演讲人:Andrej Karpathy (现在OpenAI任职),之前是特斯拉视觉研发负责人,斯坦福深度学习入门课程 CS231N 讲师
- 演讲主题:受到微软 BUILD2023 邀请,介绍 GPT 的原理及研发现状,介绍大语言模型应用生态
- 第一部分介绍如何训练 ChatGPT (本演讲中有个更通用的名字: GPT Assistant)
- 第二部分介绍如何将 ChatGPT 用于定制化应用程序
演讲视频
- 英文原版:https://www.youtube.com/watch?v=bZQun8Y4L2A
- 中文字幕版:https://www.bilibili.com/video/BV1ts4y1T7UH/?spm_id_from=333.337.search-card.all.click&vd_source=fdb0030f08e2dfd486e197c76c07672b
演讲内容的重点记录
Part1:GPT Assistant 是如何研发的
整体流程
- GPT Assistant 的训练流程,分为 4 个阶段
- Pretraining:整体训练时间的 99%
- Supervised Finetuning
- Reward Modeling
- Reinforcement Learning

Pretraining 阶段
- 预训练训练数据,以 LLaMA 的训练数据集为例,共 1.4T tokens

- 文本数据 tokenization 操作,该操作是无损失的数据变换(将文本片段转换为整数)

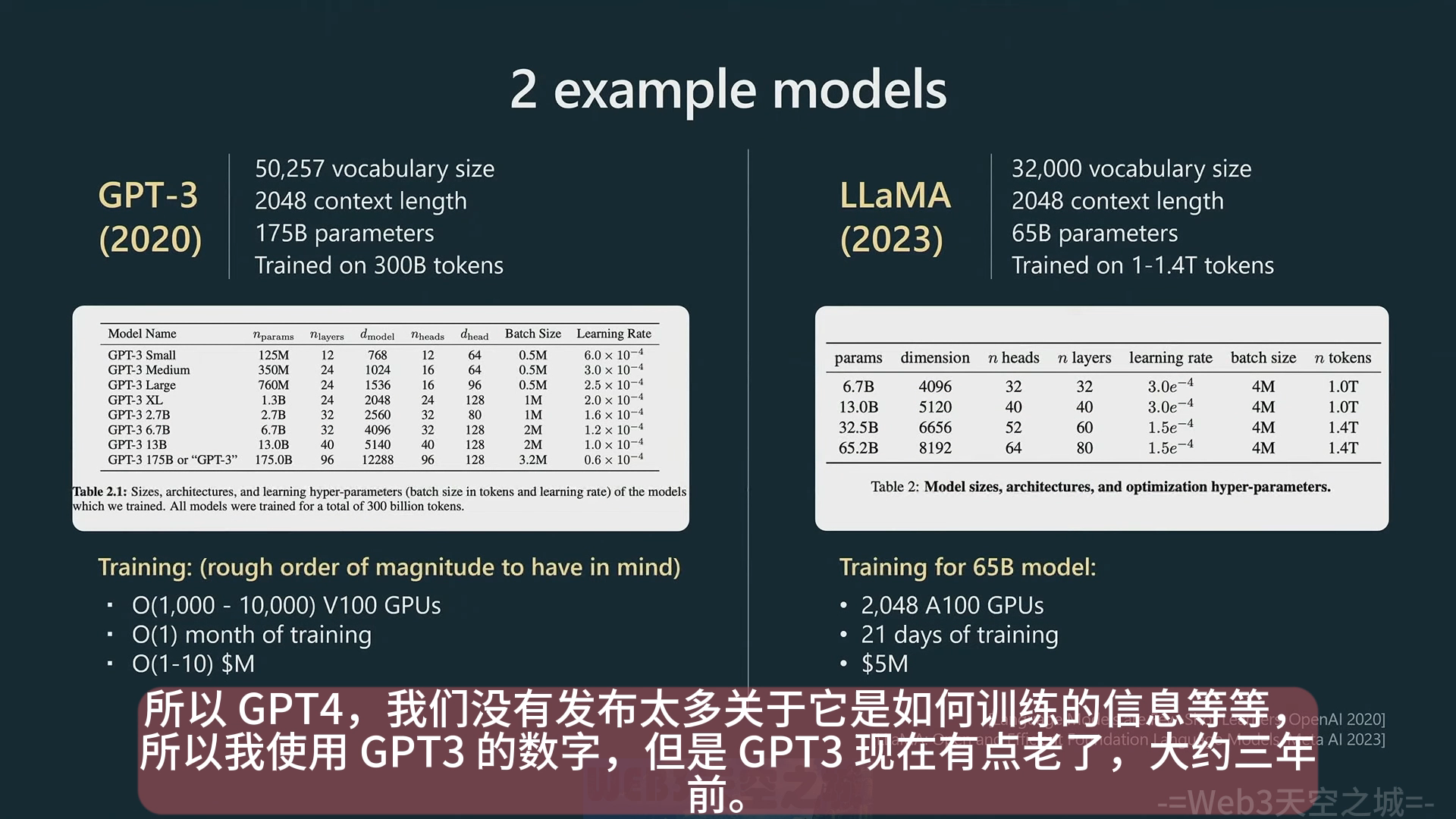
- 两个主流大语言模型的参数量介绍,因为 GPT4 的细节不公开,这里主要介绍了 GPT3 (2020) 和 LLaMA (2023)。尽管与 GPT3 的 1750 亿参数量比起来 LLaMA 的 650 亿参数量并没有优势,但是 LLaMA 实际上更强大,因为使用了更多的训练数据(300B -> 1.4T)。所以不能仅通过模型的参数量来定义模型的能力
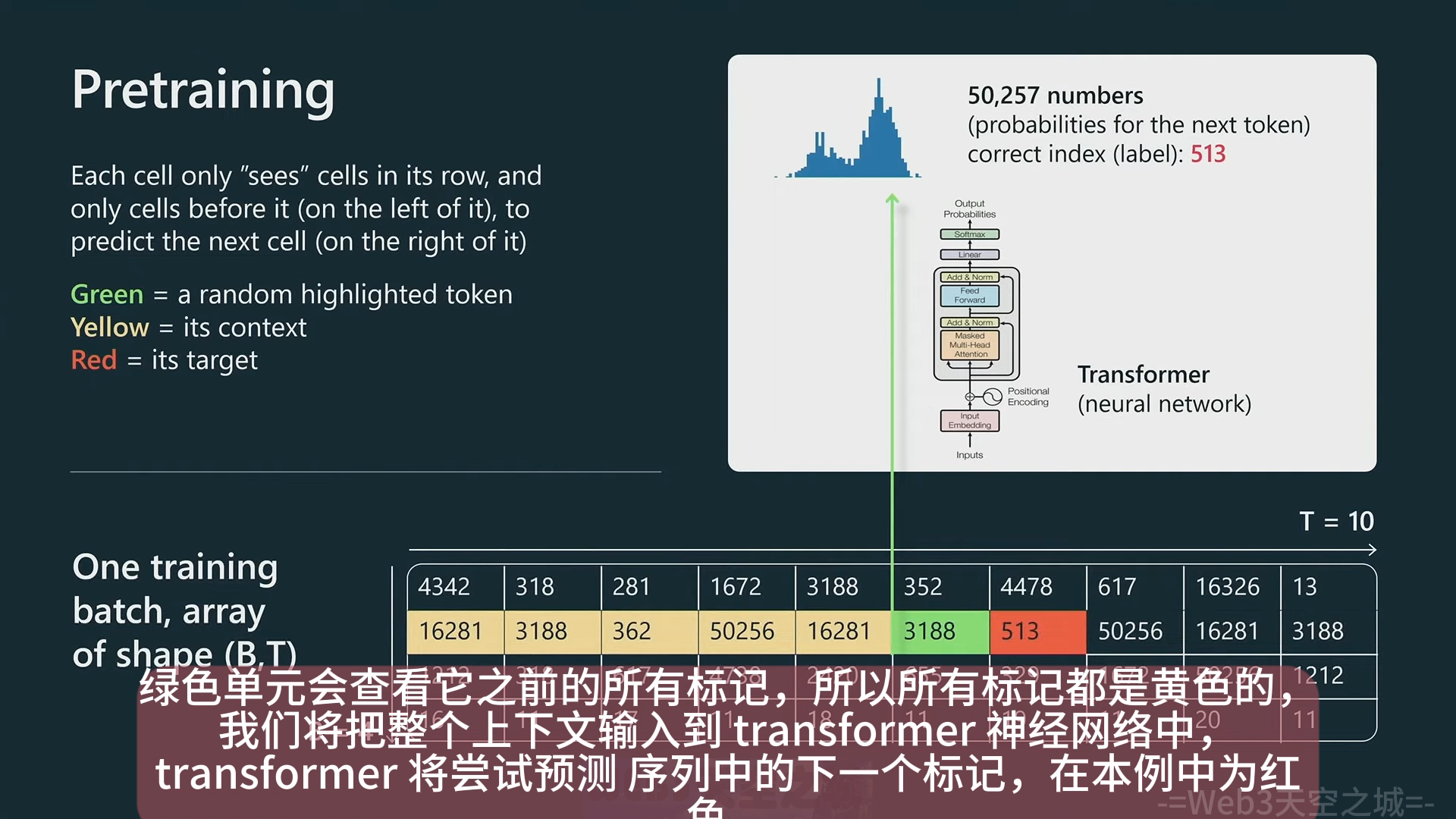
 - 预训练的模型输入,获取 tokenize 处理后的文本,打包成行,用
- 预训练的模型输入,获取 tokenize 处理后的文本,打包成行,用 <|endoftext|>来对不同的文档进行分隔

- 通过预测下一个 token 的方式来对模型进行预训练
- 以莎士比亚的作品数据集训练过程作为示例,模型刚开始训练随机初始化参数,预测的结果也是完全随机的,但是随着一定训练的迭代,模型就能预测连贯和一致的文本

使用预训练模型的方式
- 下游数据集微调,预训练能极大降低微调需要的数据量(类似 GPT1)
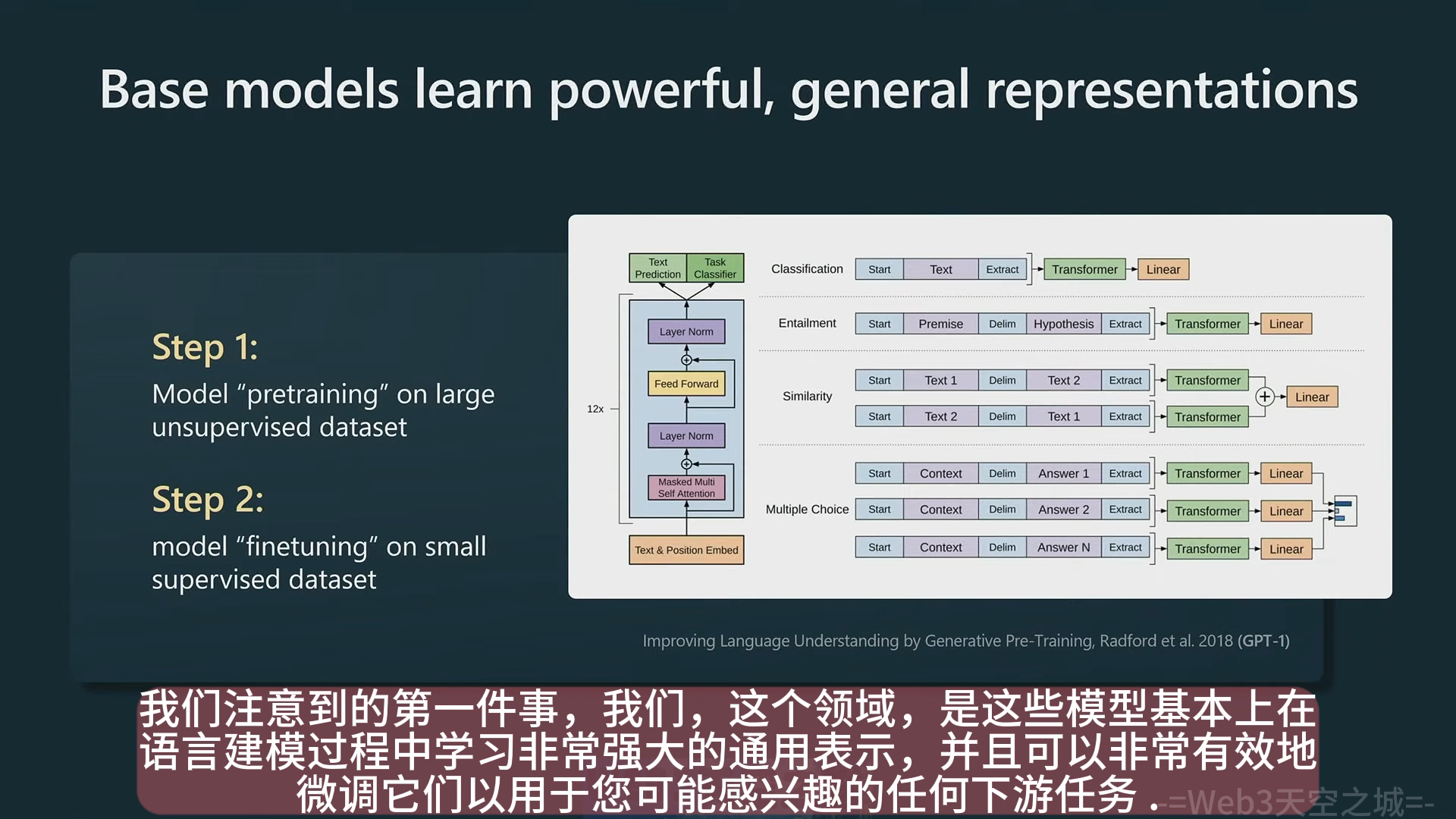
- zero-shot prompting (类似 GPT2),开启了不需要微调的时代,不需要训练模型

- 预训练模型汇总,google 和 openai 占了大半边天
基于 prompt engineering 的 GPT Assistant (效果一般,非 OpenAI 的 ChatGPT 实现方案)
- GPT Assistant 需要模型对人类的指令或问题进行回复,但预训练模型主要用于文本补全,无法直接回答问题,比如这里会出现生成与问题相关的更多问题(左图)。可以通过给预训练模型一些例子来促使模型对问题生成回复(右图)

- 通过上面的方法来使得预训练模型做 GPT Assistant
GPT Assistant 微调方法步骤一:SFT (OpenAI 的 ChatGPT 实现方案)
- 首先进行 SFT (supervised finetuning),基于少量人工标注的数据进行微调,数据主要是 prompt 和 response 对 (1 万到10 万量级)

- SFT 数据示例,prompt 是人类指令,response 是标注员写得针对人类指令的示例回复。标注文档还是很复杂的(需要满足 helpful、truthful、harmless 等约束)

GPT Assistant 微调方法步骤二:Reward Modeling (OpenAI 的 ChatGPT 实现方案)
- 准备对比数据集(10万 到 100 万量级),进行二分类训练

- RM 数据集示例。给定一个 prompt (写一个判断字符串是否是回文字符串的 python 程序),基于 SFT 模型生成多个回复,比如下面生成了三个回复后让标注员来对生成结果进行排名(排名难度较大,一个 prompt 的答案甚至可能需要几个小时来标注)

- RM 训练,这里的模型实现方法比较有信息量(和大部分开源方案加 linear head 的实现不太一样),通过在 completion token 后增加一个 reward token 来预测 reward,这样 transformer 会根据 prompt 的完成程度预测 reward

GPT Assistant 微调方法步骤三:RL learning (OpenAI 的 ChatGPT 实现方案)
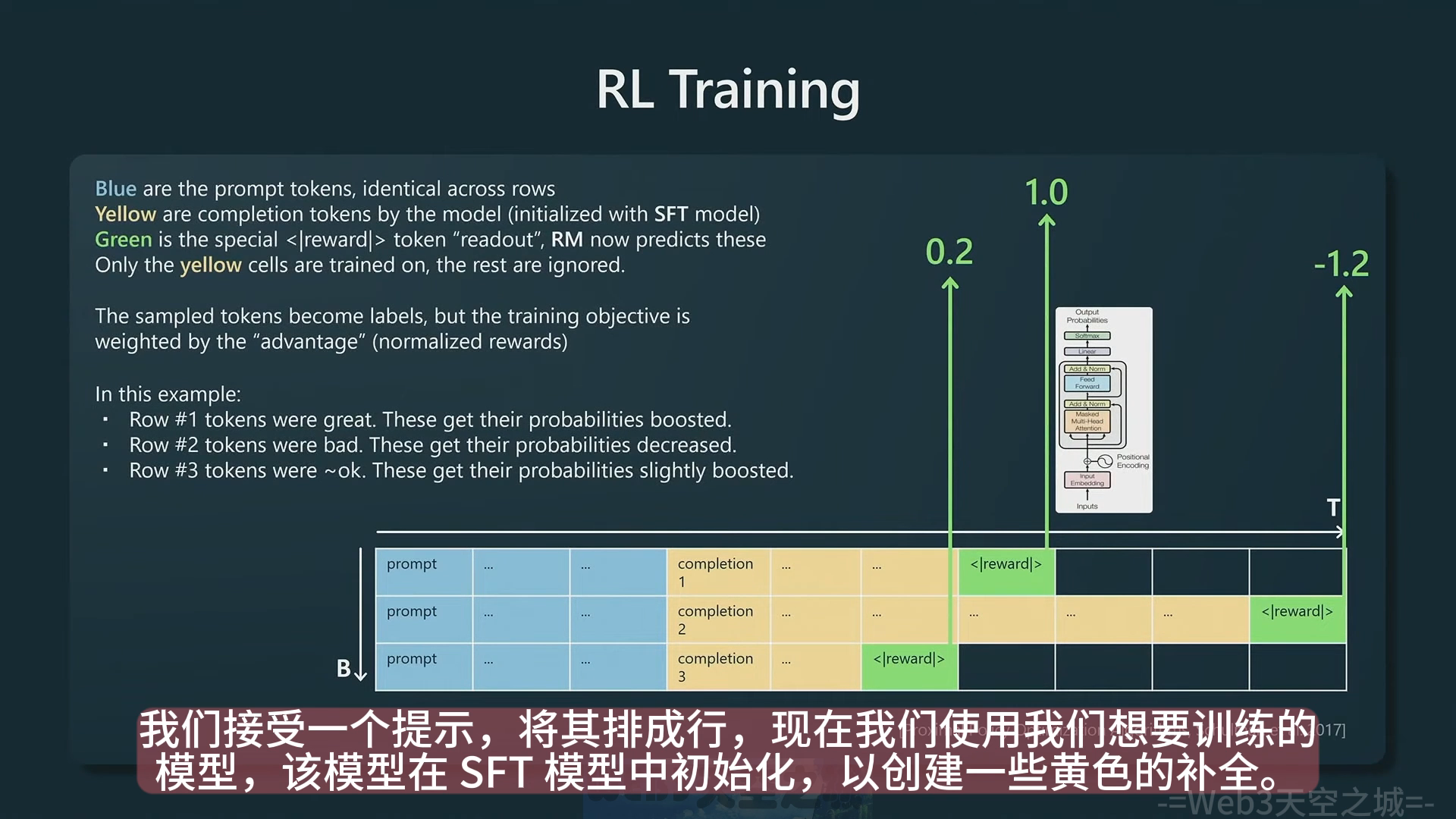
- 该过程是 openai 使用的 RLHF,基于上一步的 RM 模型进行强化学习训练。基于奖励模型指示的奖励来权衡语言建模的目标,比如下面第一行的 reward 高,第一行采样的所有 token 将得到强化,未来将会获得更高的采样概率,第二行的所有 token 之后会获得更低的采样概率
为什么需要 RLHF
-
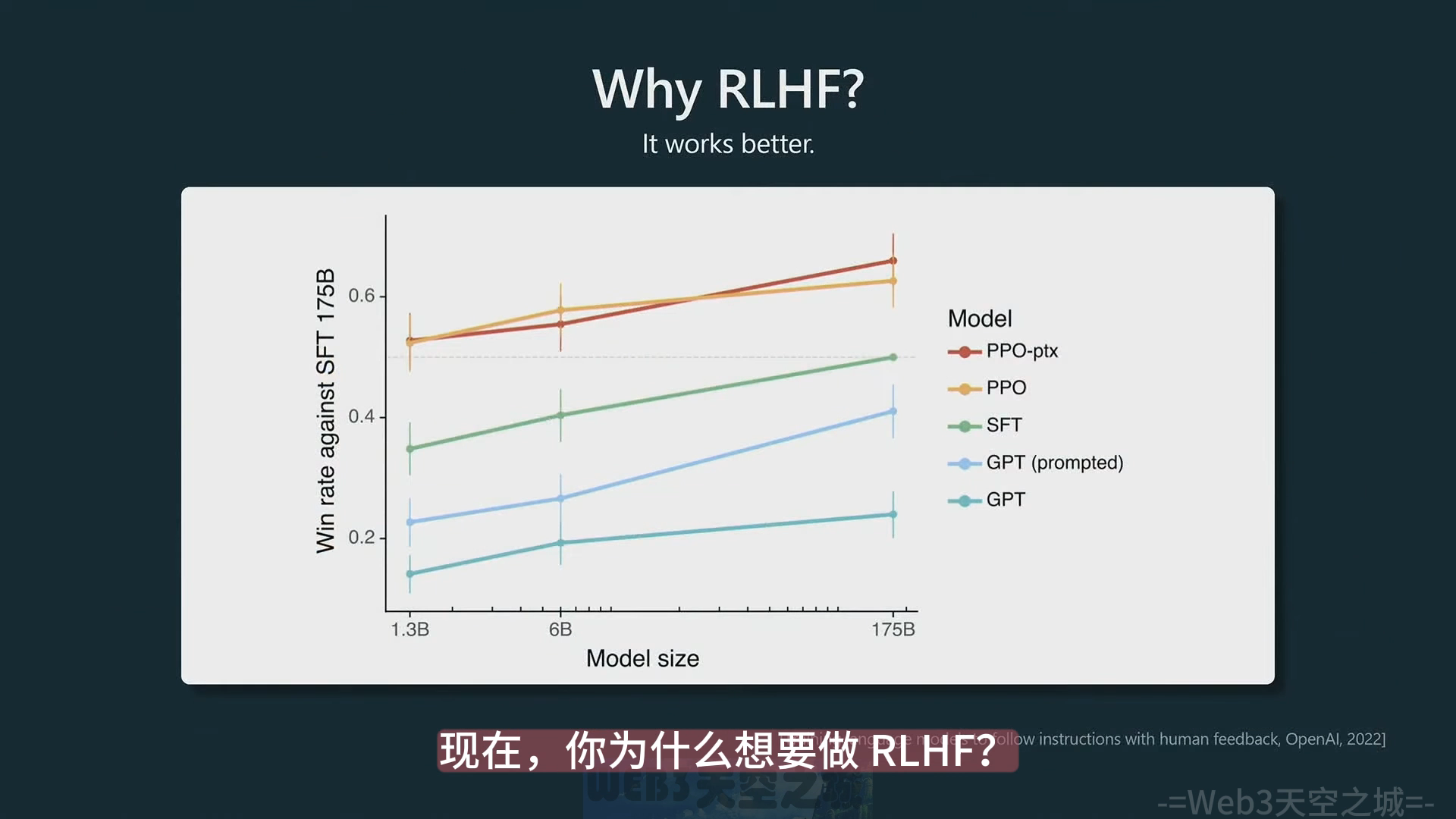
预训练模型,SFT 模型和 RLHF 模型理论上都可以用于 GPT Assistant 部署。要用 RLHF 的一个简单的原因就是 RLHF 模型效果更好,下面的图来源于 InstructGPT 论文,PPO (RLHF 算法) 后的模型生成的答案更被人类喜欢
-
karpathy 认为 RLHF 有用的原因是判别比生成更容易,让标注员去写一些 SFT 的 QA 数据对是比较难的,如果有一个 SFT 模型生成一些数据让标注员判断哪个更好就简单很多

-
RLHF 模型降低了熵,对输出文本的确定性更强,SFT 模型更善于给出有区分度的回答

-
伯克利做的模型评测榜单 Leaderboard,GPT4 最强,前三个都是 RLHF 模型,其他模型都是 SFT 模型

基于 GPT Assistant 的应用
人类文本生成对比语言模型文本生成
- 人类生成文本的方式,一步接一步思考,甚至借用外部工具(使用计算器做算数),并且会对回答进行正确性验证

- 语言模型生成文本的方法,逐步生成 token,每个 token 计算时间一样,不确定自己回复的正确性(不会对自己的回答进行正确性确认)

Chain of thought
- 需要推理的任务可以使用 CoT,transformer 需要更多的 token 来思考,使用 few-shot prompt 作为示例,让模型以 step-by-step 的方式对问题进行回复。目前也有 zero-shot-CoT,最经典的方式就是使用
Let's think step by step作为提示词

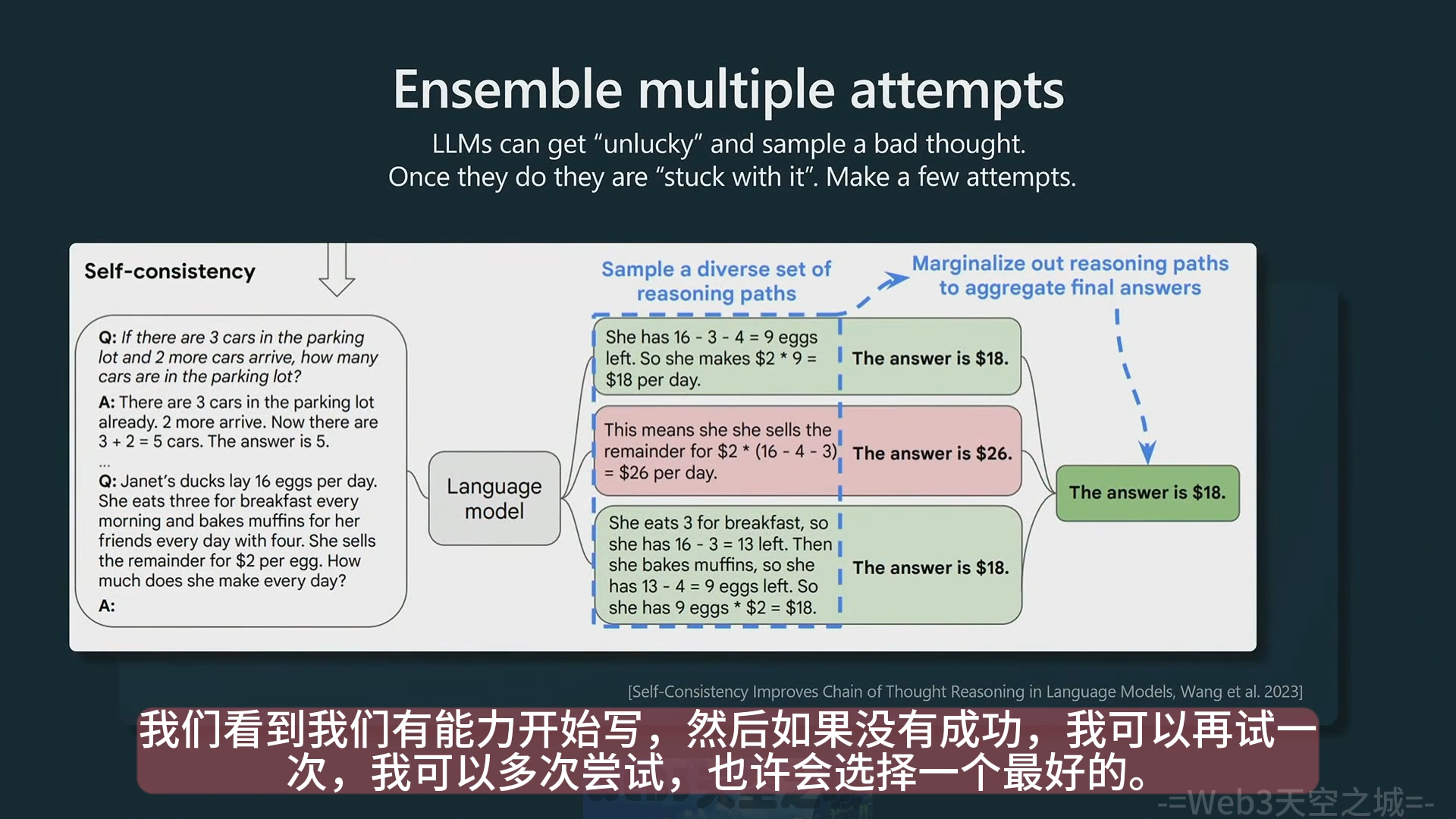
self-consistency
- 多次对一个问题进行回复,进行多数表决。比如 transformer 在采样到一个不好的 token 后就很难恢复,这样能尽量避免错误的发生。
Ask for reflection
- 通过问 “你完成任务了吗?” 这个问题,让 ChatGPT 对不好的问题进行反思并生成更好的回复

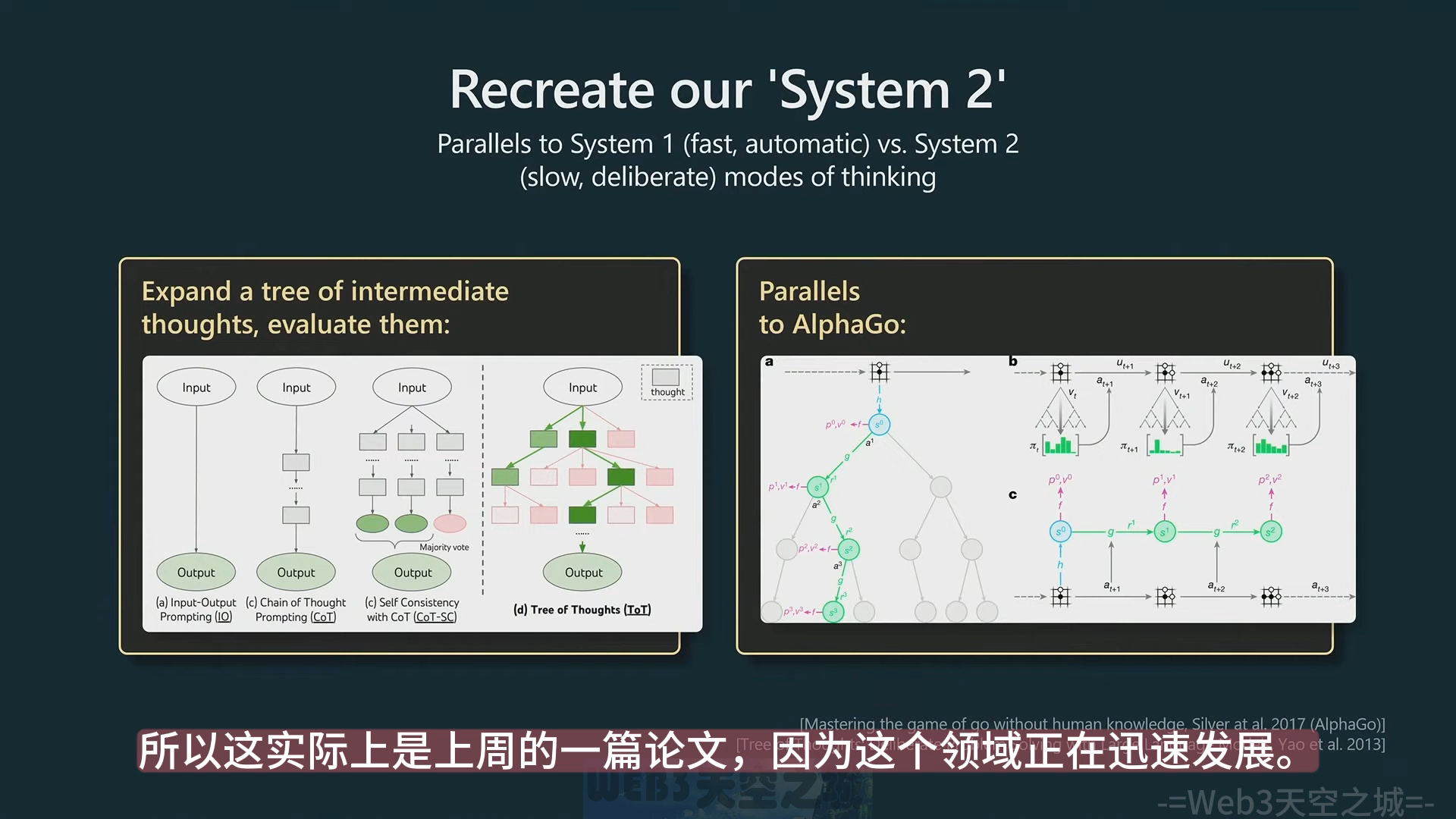
Recreat our ‘System 2’
- Tree of Thoughts(思想树):建议为任何给定的 prompt 多个 completion,然后在整个过程中对它们进行评分,并保留进展顺利的
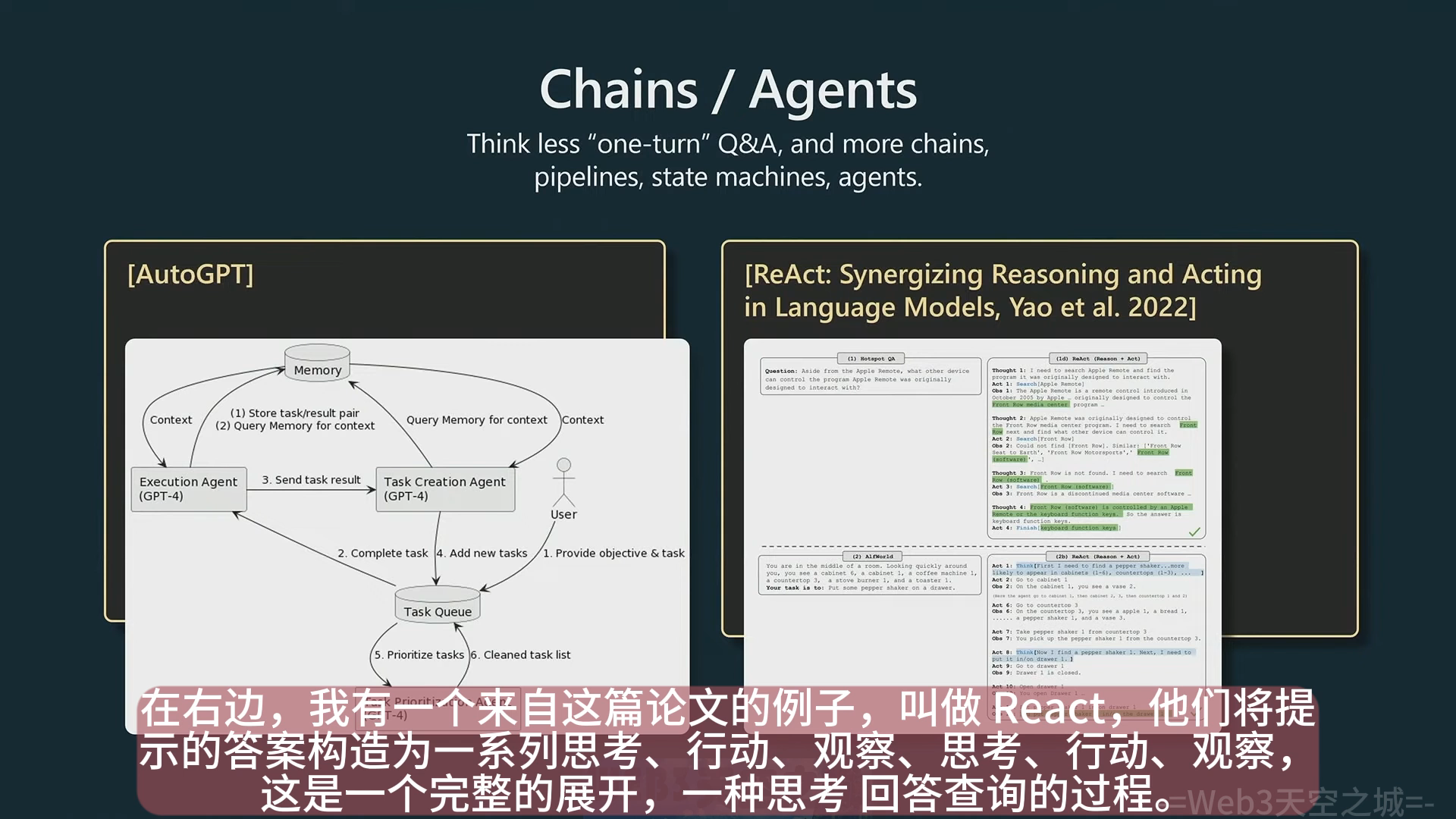
Chains/Agents
- React:将 prompt 构造成一系列思考、行动、观察、思考、行动、观察的展开,通过思考来进行问题回复,这个过程中模型一般被允许调用其他工具,比如 google 搜索 API;下图左边的 AutoGPT 最近很火热,不过 Karpathy 觉得效果一般,只建议从中汲取灵感
Condition on good performance
- LLM 只想模仿训练集,不想回复正确答案,如果希望 LLM 回复正确答案应该在 prompt 中明确说明,能在 CoT 的基础上进一步涨点

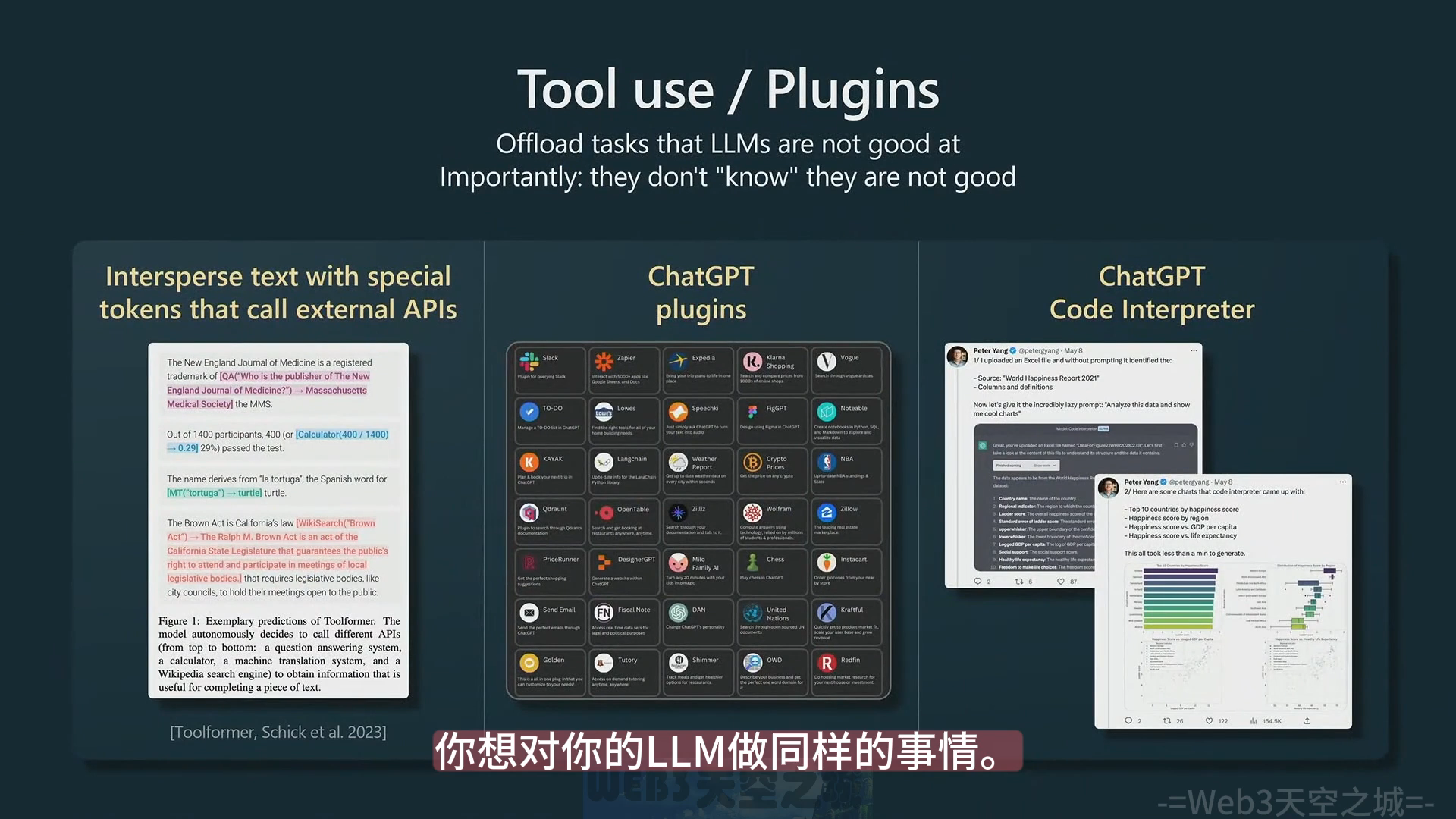
使用外部工具 (ChatGPT Plugins)
- 为 ChatGPT 提供计算器、代码解释器、搜索等工具,协助做 LLM 不擅长的事情。因为模型不知道自己不擅长什么,所以需要调用工具的位置需要人为标注出来
- 基于检索增强 LLM 能力,参考 LlamaIndex:
- 获取相关文档,将文档分为块,提取得到数据的 embedding 向量,将其存储到向量存储中
- 在测试时,对矢量存储进行查询,即能获取到与测试任务相关的文档,然后将文档填充到 prompt 中

约束提示(Constrained prompting)
- 参考微软的 guidance,在 LLM 的输出中强制使用特定模板的技术。以下的例子是让 LLM 填写一个 json 模板中的内容,其中 json 的 key 是写死的,LLM 负责填补一些空白的 key,这些 key 也可以提前进行一些约束,让 LLM 的采样空间收到限制,即能让 LLM 的输出符合预设定的格式

模型微调
- 利用 PEFT (如 LoRA) 等技术降低模型的可训练参数
- 低精度推理(比如 bitsandbytes)
- 又又又推荐了一波 LLaMA (怪不得 OpenAI 现在有计划推 GPT3 的开源…)
- SFT 相对容易;RLHF 很难,非常不稳定,很难训练,对初学者不友好,而且可能变化快,不推荐一般人来做

Karpathy 的默认建议
- 针对取得最佳表现的建议
- 使用 GPT4
- 提示词工程
- 考虑 LLM 的心理
- 提供上下文信息,提供一些样例
- 使用外部工具
- 提示词工程已经做到头的话可以尝试 SFT
- RLHF 难度大,但是理论上能优化到比 SFT 好一点
- 针对优化成本的建议
- 使用容量更小的 GPT3.5,更简短的 prompts 等

- 使用容量更小的 GPT3.5,更简短的 prompts 等
应用场景样例
- 【问题】模型可能有偏见,捏造幻觉信息,推理错误,知识截止(只知道 2021 9 月之前的知识)
- 【推荐】在低风险应用程序中使用 LLM,与人工监督结合起来;将 LLM 作为灵感和建议的来源

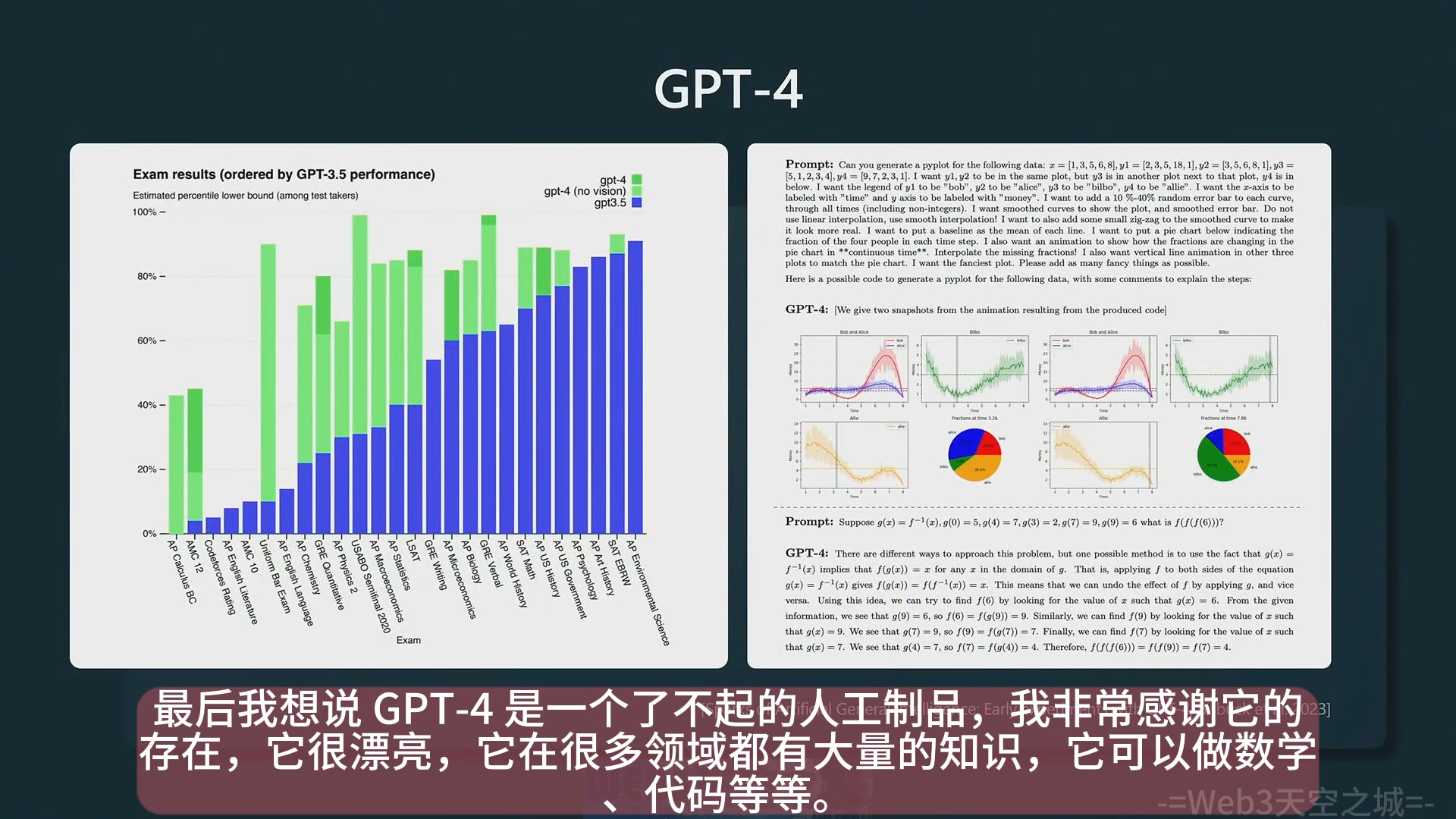
GPT4
- 推荐 GPT4 的强大能力和丰富的配套
- 使用 GPT4 的 API 问 “你能说些什么来激励 Microsoft BUILD 2023 的观众吗?”,GPT4 回复了如下的话

- 完结撒花

Thoughts
- 很典型的 Karpathy 演讲风格,将目前最高级的人工智能模型(ChatGPT)的研发流程用简单易懂的方式进行讲解。但因为 GPT4 细节不方便公开,整体干货并不太多,前半段看下来甚至感觉在给观众传递一个理念:我们的 GPT4 不方便公开细节,大家要不去用 LLaMA 吧…
- 应用方面主要介绍了一些前沿的公开工作,ChatGPT 具体有什么改良没有过多介绍