6.doris进阶
6.1修改表
6.1.1修改表名
示例:
- 将名为 table1 的表修改为 table2
| SQL |
- 将表 example_table 中名为 rollup1 的 rollup index 修改为 rollup2
| SQL |
- 将表 example_table 中名为 p1 的 partition 修改为 p2
| SQL |
6.1.2表结构的变更
用户可以通过 Schema Change 操作来修改已存在表的 Schema。目前 Doris 支持以下几种修改:
- 增加、删除列
- 修改列类型
- 调整列顺序
- 增加、修改 Bloom Filter index
- 增加、删除 bitmap index
6.1.2.1原理介绍
执行 Schema Change 的基本过程,是通过原 Index 的数据,生成一份新 Schema 的 Index 的数据。其中主要需要进行两部分数据转换:
一是已存在的历史数据的转换;
二是在 Schema Change 执行过程中,新到达的导入数据的转换。
| SQL |
6.1.2.2创建作业
Schema Change 的创建是一个异步过程,作业提交成功后,用户需要通过 SHOW ALTER TABLE COLUMN 命令来查看作业进度。
语法:
| SQL |
schema change 的 alter_clause 支持如下几种修改方式:
- 向指定 index 的指定位置添加一列
| SQL |
注意:
- 聚合模型如果增加 value 列,需要指定 agg_type
- 非聚合模型(如 DUPLICATE KEY)如果增加key列,需要指定KEY关键字
- 不能在 rollup index 中增加 base index 中已经存在的列(如有需要,可以重新创建一个 rollup index)
示例:
| SQL |
- 向指定 index 添加多列
| SQL |
- 从指定 index 中删除一列
| SQL |
注意:
- 不能删除分区列
- 如果是从 base index 中删除列,则如果 rollup index 中包含该列,也会被删除
- 修改指定 index 的列类型以及列位置
| SQL |
注意:
- 聚合模型如果修改 value 列,需要指定 agg_type
- 非聚合类型如果修改key列,需要指定KEY关键字
- 分区列和分桶列不能做任何修改
- 对指定 index 的列进行重新排序
| SQL |
注意:
- index 中的所有列都要写出来
- value 列在 key 列之后
示例:
- 向 example_rollup_index 的 col1 后添加一个key列 new_col(非聚合模型)
| SQL |
- 向example_rollup_index的col1后添加一个value列new_col(非聚合模型)
| SQL |
- 向example_rollup_index的col1后添加一个key列new_col(聚合模型)
| SQL |
- 向example_rollup_index的col1后添加一个value列new_col SUM聚合类型(聚合模型)
| SQL |
- 向 example_rollup_index 添加多列(聚合模型)
| SQL |
- 从 example_rollup_index 删除一列
| SQL |
- 修改 base index 的 key 列 col1 的类型为 BIGINT,并移动到 col2 列后面。
| SQL |
| 注意:无论是修改 key 列还是 value 列都需要声明完整的 column 信息 |
- 修改 base index 的 val1 列最大长度。原 val1 为 (val1 VARCHAR(32) REPLACE DEFAULT "abc")
| SQL |
- 重新排序 example_rollup_index 中的列(设原列顺序为:k1,k2,k3,v1,v2)
| SQL |
- 同时执行两种操作
| SQL |
6.1.2.3查看作业
SHOW ALTER TABLE COLUMN 可以查看当前正在执行或已经完成的 Schema Change 作业。当一次 Schema Change 作业涉及到多个 Index 时,该命令会显示多行,每行对应一个 Index
| SQL |
6.1.2.4参数说明
- JobId:每个 Schema Change 作业的唯一 ID。
- TableName:Schema Change 对应的基表的表名。
- CreateTime:作业创建时间。
- FinishedTime:作业结束时间。如未结束,则显示 "N/A"。
- IndexName: 本次修改所涉及的某一个 Index 的名称。
- IndexId:新的 Index 的唯一 ID。
- OriginIndexId:旧的 Index 的唯一 ID。
- SchemaVersion:以 M:N 的格式展示。其中 M 表示本次 Schema Change 变更的版本,N 表示对应的 Hash 值。每次 Schema Change,版本都会递增。
- TransactionId:转换历史数据的分水岭 transaction ID。
- State:作业所在阶段。
- PENDING:作业在队列中等待被调度。
- WAITING_TXN:等待分水岭 transaction ID 之前的导入任务完成。
- RUNNING:历史数据转换中。
- FINISHED:作业成功。
- CANCELLED:作业失败。
- Msg:如果作业失败,这里会显示失败信息。
- Progress:作业进度。只有在 RUNNING 状态才会显示进度。进度是以 M/N 的形式显示。其中 N 为 Schema Change 涉及的总副本数。M 为已完成历史数据转换的副本数。
- Timeout:作业超时时间。单位秒。
6.1.2.5取消作业
在作业状态不为 FINISHED 或 CANCELLED 的情况下,可以通过以下命令取消Schema Change作业:
| SQL |
| 注意事项
|
6.1.3 partition的增减
- 增加分区, 使用默认分桶方式:现有分区 [MIN, 2013-01-01),增加分区 [2013-01-01, 2014-01-01)
| SQL |
- 增加分区,使用新的分桶数
| SQL |
- 增加分区,使用新的副本数
| SQL |
- 修改分区副本数
| SQL |
- 批量修改指定分区
| SQL |
- 批量修改所有分区
| SQL |
- 删除分区
| SQL |
- 增加一个指定上下界的分区
| SQL |
6.1.4 rollup的增减
- 创建 index: example_rollup_index,基于 base index(k1,k2,k3,v1,v2)。列式存储。
| SQL |
- 创建 index: example_rollup_index2,基于 example_rollup_index(k1,k3,v1,v2)
| SQL |
- 创建 index: example_rollup_index3, 基于base index (k1,k2,k3,v1), 自定义rollup超时时间一小时
| SQL |
- 删除 index: example_rollup_index2
| SQL |
6.2动态分区和临时分区
6.2.1动态分区
旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
目前实现了动态添加分区及动态删除分区的功能。只支持 Range 分区。
6.2.1.1原理
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。通过动态分区功能,用户可以在建表时设定动态分区的规则。FE 会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
6.2.1.2使用方式
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则
建表时指定:
| SQL |
运行时修改:
| SQL |
6.2.1.3动态分区规则参数
- dynamic_partition.enable:是否开启动态分区特性。默认是true
- dynamic_partition.time_unit:动态分区调度的单位。可指定为 HOUR、DAY、WEEK、MONTH。分别表示按小时、按天、按星期、按月进行分区创建或删除。
- dynamic_partition.time_zone:动态分区的时区,如果不填写,则默认为当前机器的系统的时区
- dynamic_partition.start:动态分区的起始偏移,为负数。以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。如果不填写,则默认为 -2147483648,即不删除历史分区。
- dynamic_partition.end:动态分区的结束偏移,为正数。根据 time_unit 属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区。
- dynamic_partition.prefix:动态创建的分区名前缀。
- dynamic_partition.buckets:动态创建的分区所对应的分桶数量
- dynamic_partition.replication_num:动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量
- dynamic_partition.start_day_of_week:当 time_unit 为 WEEK 时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点。
- dynamic_partition.start_day_of_month:当 time_unit 为 MONTH 时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月1号,28 表示每月28号。默认为 1,即表示每月以1号位起始点。暂不支持以29、30、31号为起始日,以避免因闰年或闰月带来的歧义
- dynamic_partition.create_history_partition:为 true 时代表可以创建历史分区,默认是false
- dynamic_partition.history_partition_num:当 create_history_partition 为 true 时,该参数用于指定创建历史分区数量。默认值为 -1, 即未设置。
- dynamic_partition.hot_partition_num:指定最新的多少个分区为热分区。对于热分区,系统会自动设置其 storage_medium 参数为SSD,并且设置 storage_cooldown_time 。hot_partition_num:设置往前 n 天和未来所有分区为热分区,并自动设置冷却时间
我们举例说明
| 举例: 假设今天是 2021-05-20,按天分区,动态分区的属性设置为: hot_partition_num=2, end=3, start=-3。 则系统会自动创建以下分区,并且设置 storage_medium 和 storage_cooldown_time 参数: p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59 |
- dynamic_partition.reserved_history_periods:需要保留的历史分区的时间范围。
| 类似于开后门儿,其他的都删了,就留我指定的几个分区 time_unit="DAY/WEEK/MONTH", end=3, start=-3, reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"。 则系统会自动保留: ["2020-06-01","2020-06-20"], ["2020-10-31","2020-11-15"] |
历史分区创建示例:
| 假设今天是 2021-05-20,按天分区,动态分区的属性设置为: create_history_partition=true, end=3, start=-3, dynamic_partition.create_history_partition:true -- 可以创建(保留)多少个历史分区 history_partition_num=1,则系统会自动创建以下分区: p20210519 history_partition_num=5,其余属性与 1 中保持一致,则系统会自动创建以下分区: p20210517 history_partition_num=-1 即不设置历史分区数量,其余属性与 1 中保持一直,则系统会自动创建以下分区: p20210517 |
示例:
表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近7天的分区,并且预先创建未来3天的分区。
| SQL |
假设当前日期为 2020-05-29。则根据以上规则,tbl1 会产生以下分区:
| SQL |
6.2.1.4修改动态分区属性
| SQL |
某些属性的修改可能会产生冲突。假设之前分区粒度为 DAY,并且已经创建了如下分区:
| SQL |
如果此时将分区粒度改为 MONTH,则系统会尝试创建范围为 ["2020-05-01", "2020-06-01") 的分区,而该分区的分区范围和已有分区冲突,所以无法创建。而范围为 ["2020-06-01", "2020-07-01") 的分区可以正常创建。因此,2020-05-22 到 2020-05-30 时间段的分区,需要自行填补。
6.2.1.5查看动态分区表调度情况
通过以下命令可以进一步查看当前数据库下,所有动态分区表的调度情况:
| SQL |
- LastUpdateTime: 最后一次修改动态分区属性的时间
- LastSchedulerTime: 最后一次执行动态分区调度的时间
- State: 最后一次执行动态分区调度的状态
- LastCreatePartitionMsg: 最后一次执行动态添加分区调度的错误信息
- LastDropPartitionMsg: 最后一次执行动态删除分区调度的错误信息
6.2.2临时分区
6.2.2.1规则
- 临时分区的分区列和正式分区相同,且不可修改。
- 一张表所有临时分区之间的分区范围不可重叠,但临时分区的范围和正式分区范围可以重叠。
- 临时分区的分区名称不能和正式分区以及其他临时分区重复。
6.2.2.2操作
临时分区支持添加、删除、替换操作。
6.2.2.2.1添加临时分区
可以通过 ALTER TABLE ADD TEMPORARY PARTITION 语句对一个表添加临时分区:
| SQL |
添加操作的一些说明:
- 临时分区的添加和正式分区的添加操作相似。临时分区的分区范围独立于正式分区。
- 临时分区可以独立指定一些属性。包括分桶数、副本数、是否是内存表、存储介质等信息。
6.2.2.2.2删除临时分区
可以通过 ALTER TABLE DROP TEMPORARY PARTITION 语句删除一个表的临时分区:
| SQL |
删除操作的一些说明:
- 删除临时分区,不影响正式分区的数据。
6.2.2.2.3替换分区
可以通过 ALTER TABLE REPLACE PARTITION 语句将一个表的正式分区替换为临时分区。
| SQL |
- strict_range:默认为 true。
- 对于 Range 分区,当该参数为 true 时,表示要被替换的所有正式分区的范围并集需要和替换的临时分区的范围并集完全相同。当置为 false 时,只需要保证替换后,新的正式分区间的范围不重叠即可。
- 对于 List 分区,该参数恒为 true。要被替换的所有正式分区的枚举值必须和替换的临时分区枚举值完全相同。
- use_temp_partition_name:默认为 false。当该参数为 false,并且待替换的分区和替换分区的个数相同时,则替换后的正式分区名称维持不变。如果为 true,则替换后,正式分区的名称为替换分区的名称。
示例:
| SQL |
替换操作的一些说明:
- 分区替换成功后,被替换的分区将被删除且不可恢复。
6.2.2.3数据的导入和查询
6.2.2.3.1导入临时分区
根据导入方式的不同,指定导入临时分区的语法稍有差别。这里通过示例进行简单说明
查询结果用insert导入
| SQL |
6.2.2.3.2查看数据
| SQL |
6.3 doris中join的优化原理
6.3.1 Shuffle Join(Partitioned Join)
和mr中的shuffle过程是一样的,针对每个节点上的数据进行shuffle,相同数据分发到下游的节点上的join方式叫shuffle join

订单明细表:
| SQL |
商品表:
| SQL |
Sql示例:
| SQL |
适用场景:不管数据量,不管是大表join大表还是大表join小表都可以用
优点:通用
缺点:需要shuffle内存和网络开销比较大,效率不高
6.3.2 Broadcast Join
当一个大表join小表的时候,将小表广播到每一个大表所在的每一个节点上(以hash表的形式放在内存中)这样的方式叫做Broadcast Join,类似于mr里面的一个map端join

订单明细表:
| SQL |
商品表:
| SQL |
- 显式使用 Broadcast Join:
| SQL |
他一般用在什么场景下:左表join右表,要求左表的数据量相对来说比较大,右表数据量比较小
优点:避免了shuffle,提高了运算效率
缺点:有限制,必须右表数据量比较小
6.3.3 Bucket Shuffle Join
利用建表时候分桶的特性,当join的时候,join的条件和左表的分桶字段一样的时候,将右表按照左表分桶的规则进行shuffle操作,使右表中需要join的数据落在左表中需要join数据的BE节点上的join方式叫做Bucket Shuffle Join。

使用
从 0.14 版本开始默认为 true,新版本可以不用设置这个参数了!
| SQL |
订单明细表:
| SQL |
商品表:
| SQL |
通过 explain 查看 join 类型
| SQL |
| 注意事项
|
6.3.4 Colocation Join
中文意思叫位置协同分组join,指需要join的两份数据都在同一个BE节点上,这样在join的时候,直接本地join计算即可,不需要进行shuffle。
6.3.4.1 名词解释
- Colocation Group(位置协同组CG):在同一个 CG内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布(满足三个条件)。
- Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息。包括分桶列类型,分桶数以及分区的副本数等。

6.3.4.2 使用限制
- 建表时两张表的分桶列的类型和数量需要完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
- 同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应
- 同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
6.3.4.4 使用案例
建两张表,分桶列都为 int 类型,且桶的个数都是 5 个。副本数都为默认副本数。
| SQL |
编写查询语句,并查看执行计划
| SQL |
查看 Group
| SQL |
当 Group 中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过DROP TABLE 命令删除后,会在回收站默认停留一天的时间后,再删除),该 Group 也会被自动删除。
修改表 Colocate Group 属性
| SQL |
| 如果被修改的表原来有group,那么会直接将原来的group删除后创建新的group 如果原来没有组,就直接创建 |
删除表的 Colocation 属性
| SQL |
| 当对一个具有 Colocation 属性的表进行增加分区(ADD PARTITION)、修改副本数时,Doris 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝。 |
6.3.5 Runtime Filter
Runtime Filter会在有join动作的 sql运行时,创建一个HashJoinNode和一个ScanNode来对join的数据进行过滤优化,使得join的时候数据量变少,从而提高效率。
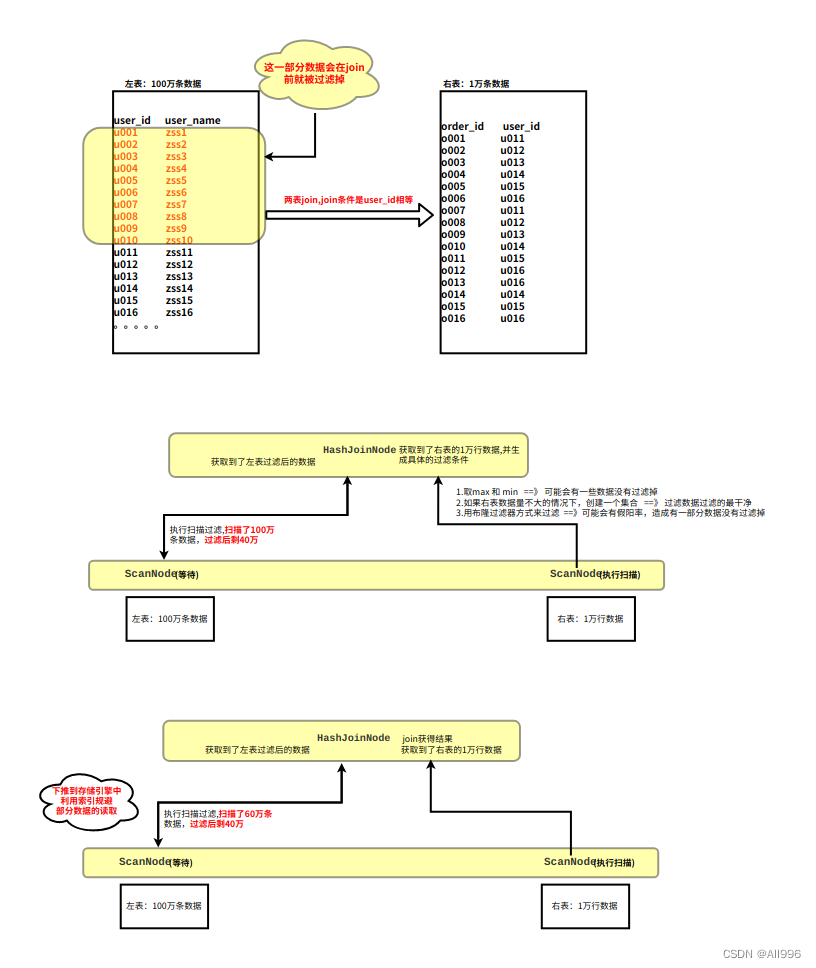
使用
指定 RuntimeFilter 类型
| SQL |
参数解释:
- runtime_filter_type: 包括Bloom Filter、MinMax Filter、IN predicate、IN Or Bloom Filter
- Bloom Filter: 针对右表中的join字段的所有数据标注在一个布隆过滤器中,从而判断左表中需要join的数据在还是不在
- MinMax Filter: 获取到右表表中数据的最大值和最小值,看左表中查看,将超出这个最大值最小值范围的数据过滤掉
- IN predicate: 将右表中需要join字段所有数据构建一个IN predicate,再去左表表中过滤无意义数据
- runtime_filter_wait_time_ms: 左表的ScanNode等待每个Runtime Filter的时间,默认1000ms
- runtime_filters_max_num: 每个查询可应用的Runtime Filter中Bloom Filter的最大数量,默认10
- runtime_bloom_filter_min_size: Runtime Filter中Bloom Filter的最小长度,默认1M
- runtime_bloom_filter_max_size: Runtime Filter中Bloom Filter的最大长度,默认16M
- runtime_bloom_filter_size: Runtime Filter中Bloom Filter的默认长度,默认2M
- runtime_filter_max_in_num: 如果join右表数据行数大于这个值,我们将不生成IN predicate,默认102400
示例实操:
建表
| SQL |
查看执行计划
| SQL |