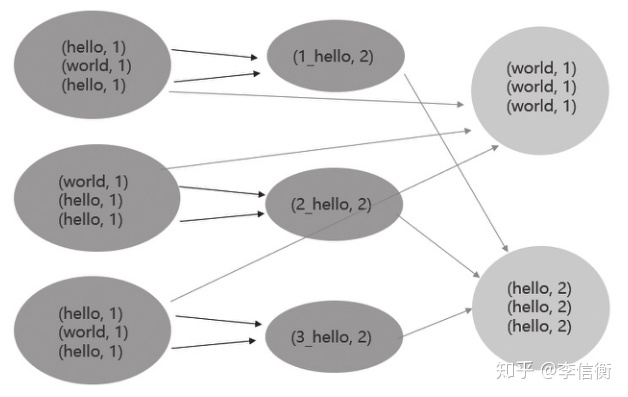
背景
正如我之前的文章里所解释的那样,B+树的深度决定了MySQL在仅考虑使用索引的情况下的最坏查询性能。在SSD的帮助下,拥有一个比4层更深的B+树应该是可以接受的。
那么下一个问题是:性能可能有多糟糕?在这里,我有意设计了一张表,使用非常长的字符串作为主键和索引,这将导致非常深的B+树,最多达到9层,以测试在SSD上的最差性能,这在实际生产中是不太可能遇到的。
环境
— 数据库
MySQL 版本:8.0.25
实例类型:AWS db.r5.large (2vCPUs, 16GiB RAM)
EBS 存储类型:通用 SSD (gp2)
— 测试客户端
Linux 内核版本:6.1
实例类型:AWS t2.micro (1 vCPU,1GiB 内存)
实验设计
1. 使用长字符串作为主键,并使用另一个长字符串列作为索引创建表格。我创建了9个表格,分别有5、25、125、625、3125、15625、78125和390625行。
为什么将表格的行数设置为等比数列,并且每个数字在另一个数字后乘以5?原因是在MySQL 8.0.25中,主键的大小应该小于3072字节,相当于3k。由于每个页面大小为16k,一个页面最多可以容纳5个键。因此,您可以期望在我们的索引B+树中,每个非分支节点最多有5个子节点。拥有5行的表格深度为2,25行的表格深度为3,依此类推...但在实际情况中可能更加复杂,因为页面目录的大小未确定,一些B+树的非分支节点可能只能容纳4个节点,使得树比理论更深。
CREATE TABLE `5_big_pk_test` (
`big_pk` varchar(768) NOT NULL,
`big_index_key` varchar(768) DEFAULT NULL,
`id` int NOT NULL DEFAULT '0',
PRIMARY KEY (`big_pk`),
KEY `query_by_big_key_index` (`big_index_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;这里我使用charset=utf8mb4,所以每个字符会占用4个字节。因此,长度为 768 的字符串足以达到主键大小限制的上限。
2. 插入不同行的表格。我使用测试客户端和复制来创建这些表。脚本可以在这里找到。
# test client
INSERT INTO {table} (big_pk, big_index_key) VALUES ({pk}, {pk})big_key 和 big_index_key 的值是随机的长字符串。为了方便起见,该字符串由前 10 个字符的随机头和其余字符的固定尾组成。
3.使用测试客户端执行以下sql查询来测试性能。脚本可以在这里找到。
select * from {table} where big_pk = \"{target_key}\" --query by primary key
select * from {table} where big_index_key = \"{target_key}\" --query by index, but cause 2-times index tree lookup4.查看innodb缓冲池状态
SHOW STATUS LIKE 'innodb_buffer_pool_pages%'5.每次在表上测试完一定要重启数据库!刷新 innodb 缓冲池以避免读取旧缓存并得到错误结果!还需要设置以下变量以避免在重启期间缓冲池转储/加载。
# Stop saving the buffer pool to disk at shutdown
SET GLOBAL innodb_buffer_pool_dump_at_shutdown=OFF;
# Stop loading the buffer pool from disk at startup
SET GLOBAL innodb_buffer_pool_load_at_startup=OFF;
# Check the status of the dump and load
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_dump_status';
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_load_status';结果
查询 1。select * from {table} where big_pk = \"{target_key}\"


正如我们所见,B+ 树的深度按设计上升了。查询运行时最坏的情况是表有 390,625 行,大约需要 8ms 和 9 倍的 I/O 来查询其主键。
查询 2。select * from {table} where big_index_key = \"{target_key}\"


这个查询需要两次索引树查找,因为两次索引树都很深,所以会触发很多 I/O 步骤。最坏的情况仍然是 390,625 行的表,大约 15ms 和 14 倍的 I/O。
讨论
与浅树相比,在深 B+ 树上查询(8-15 毫秒)很慢。更糟糕的是,查询会消耗大量的I/O资源,其每秒查询率将受到IOPS/<每次查询的I/O操作数>的限制。以我的实例为例,IOPS基准是每秒3600次。因此,在390,625行表上进行的查询的每秒查询率将限制在250次/秒,更不用说我们还有其他需要同时进行I/O的查询。
此外,我从我的同事那里听说,当他们将大字符串(10个字符,40字节)用作索引时,数据库的CPU使用率非常高,因为它必须进行大量的字符串比较,这是CPU密集型操作。结果,团队不得不重新设计索引并执行DDL操作。他观察到在MongoDB上也存在这种情况,MongoDB也使用B-Tree索引。
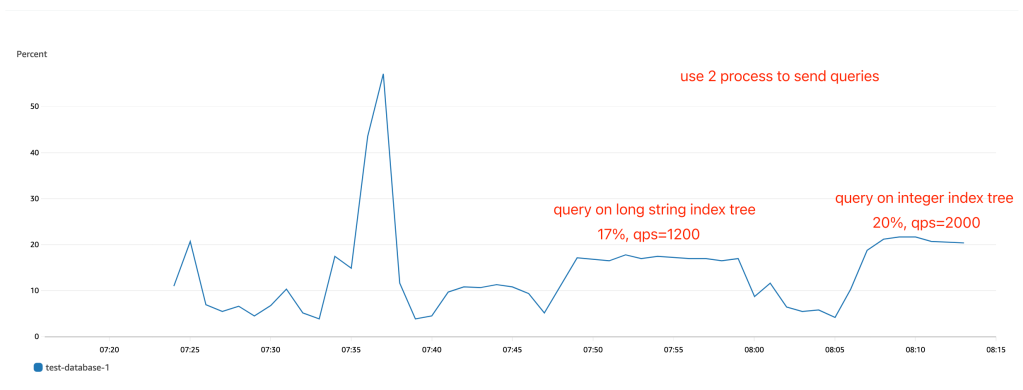
我可以在MySQL上重现这个情况:在运行具有查询语句的两个进程后,当每秒查询率为1200时,CPU使用率已经达到17%。相比之下,对于整数键索引树上的查询语句,每秒查询率为2100时CPU使用率约为20%。


通常会创建集群索引(辅助索引)以加快某些查询的速度。在这些索引中,键的值被连接在一起以形成新的键,这可能导致索引的键变得很大。
结论
-
保持主键/索引键尽可能小。切勿使用长字符串作为主键/索引键。
-
设计集群索引时要小心。确保连接键足够小。
作者:YISHENG GONG
更多技术干货请关注公号“云原生数据库”
squids.cn,基于公有云基础资源,提供云上 RDS,云备份,云迁移,SQL 窗口门户企业功能,
帮助企业快速构建云上数据库融合生态。