作者:高文峰 | 神州数码云基地TiDB团队成员
目录
一、前言
二、升级架构图
三、升级流程
1.下游TiDB集群部署过程
2. 上游TiCDC节点的扩容
3. 上游数据全备恢复到下游
4. TiCDC启用正向同步任务
5. 应用停服务,tidb 无业务会话连接
6. 确认数据已完全同步,停止正向同步任务
7. 数据校验
8. 开启回退库的反向TiCDC同步
9. 创建业务用户,取消只读,F5切换到(v6.1.0)集群
10. 业务接入服务,验证服务正常
四、回退方案
1. 回退前提条件
2. 回退操作步骤
五、总结
一、前言
本操作手册描述了 xx 用户 TiDB 集群基于TiCDC进行大版本升级的操作过程、操作方法与注意事项,用于指导 xx 用户完成TiDB 集群基于TiCDC进行大版本异机升级以及回退方案。
二、升级架构图
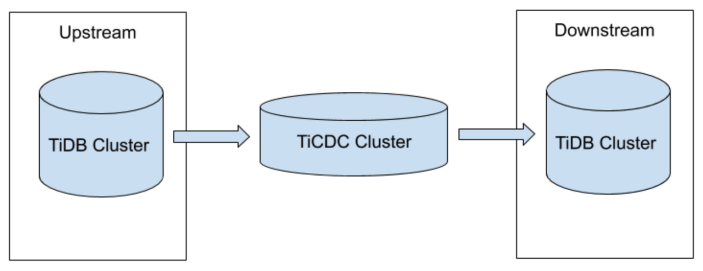
TiCDC的系统架构如上图所示:
部署一套所需升级版本的下游TiDB集群,上游数据通过dumpling+lightning全备恢复到下游,再通过 TiCDC 实时同步增量数据到下游。
系统角色
• TiKV CDC 组件:只输出 key-value (KV) change log。
○ 内部逻辑拼装 KV change log。
○ 提供输出 KV change log 的接口,发送数据包括实时 change log 和增量扫的 change log。
• capture:TiCDC 运行进程,多个 capture 组成一个 TiCDC 集群,负责 KV change log 的同步。
○ 每个 capture 负责拉取一部分 KV change log。
○ 对拉取的一个或多个 KV change log 进行排序。
○ 向下游还原事务或按照 TiCDC Open Protocol 进行输出。
三、升级流程
本过程中,详细描述了将 TiDB 集群基于TiCDC进行大版本升级的过程,具体操作步骤如下:
1.下游TiDB集群部署过程
1) 下游v6.1.0版本TiDB集群配置文件
Bash
config2.yaml:
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb-deploy"
data_dir: "/data/tidb-data"
arch: "amd64"
monitored:
node_exporter_port: 9101
blackbox_exporter_port: 9116
pd_servers:
- host: 192.168.2.81
client_port: 2479
peer_port: 2480
- host: 192.168.2.82
client_port: 2479
peer_port: 2480
- host: 192.168.2.83
client_port: 2479
peer_port: 2480
tidb_servers:
- host: 192.168.2.80
port: 4001
status_port: 10081
tikv_servers:
- host: 192.168.2.81
port: 20161
status_port: 20181
- host: 192.168.2.82
port: 20161
status_port: 20181
- host: 192.168.2.83
port: 20161
status_port: 201812) TiDB集群的部署
tiup cluster deploy tidb-test v6.1.0 config2.yaml
tiup cluster start tidb-test2
tiup cluster display tidb-test2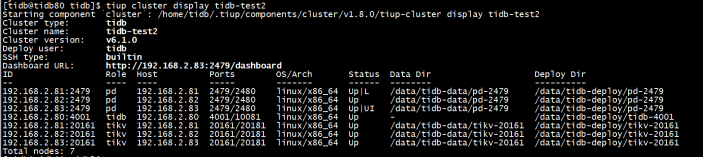
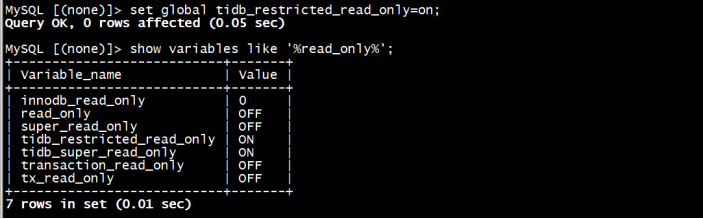
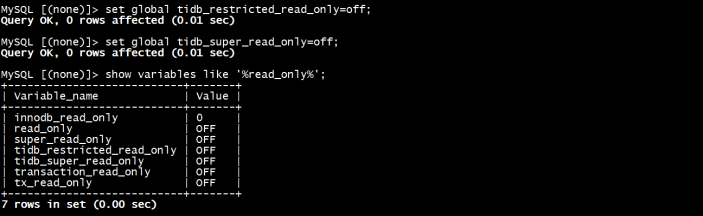
3)配置tidb只读,防止业务修改写入(可选)
2. 上游TiCDC节点的扩容
1) 配置文件
Bash
scale-ticdc.yaml:
cdc_servers:
- host: 192.168.2.80
ssh_port: 22
port: 8300
deploy_dir: "/tidb-deploy/cdc-8300"
log_dir: "/tidb-deploy/cdc-8300/log"
2) TiCDC节点的扩容
tiup cluster scale-out tidb-test1 /tidb/scale-ticdc.yaml
tiup cluster display tidb-test1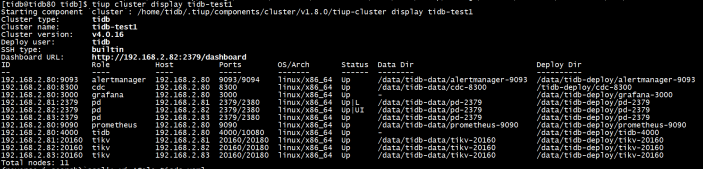
3) 确认业务表都有唯一键或者主键
Bash
SELECT
t.table_schema AS database_name,
t.table_name
FROM
information_schema.TABLES t
LEFT JOIN information_schema.TABLE_CONSTRAINTS c ON t.TABLE_SCHEMA = c.TABLE_SCHEMA
AND t.table_name = c.TABLE_NAME
AND c.CONSTRAINT_TYPE = 'PRIMARY KEY'
WHERE
C.CONSTRAINT_TYPE IS NULL
AND T.TABLE_TYPE = 'BASE TABLE'
AND T.TABLE_SCHEMA NOT IN ( 'mysql', 'information_schema', 'performance_schema', 'sys' );3. 上游数据全备恢复到下游
1) dumpling全备
mkdir -p /tidb/backup
tiup dumpling --user root --port 4000 --host 192.168.2.80 -proot --filetype sql --threads 8 -r 200000 --filesize 256MiB --output /tidb/backup --database "db1,db2,db3,db4,db5" >> /tidb/backup/dumpling.log
cat /tidb/backup/metadata以上命令中:
-h、-P、-u 分别代表地址、端口、用户。
如果需要密码验证,可以使用 -p $YOUR_SECRET_PASSWORD 将密码传给 Dumpling。
-o用于选择存储导出文件的目录,支持本地文件路径或外部存储 URL 格式。
-t用于指定导出的线程数。增加线程数会增加 Dumpling 并发度提高导出速度,但也会加大数据库内存消耗,因此不宜设置过大。
-r用于指定单个文件的最大行数,指定该参数后 Dumpling 会开启表内并发加速导出,同时减少内存使用。
-F选项用于指定单个文件的最大大小,单位为 MiB,可接受类似 5GiB 或 8KB 的输入。如果你想使用 TiDB Lightning 将该文件加载到 TiDB 实例中,建议将 -F 选项的值保持在 256 MiB 或以下。
2) 用户和权限导出
3) lightning恢复
Bash
tidb-lightning.toml:
[lightning]
# 启动之前检查集群是否满足最低需求。
check-requirements = true
file = "tidb-lightning.log"
[checkpoint]
# 是否启用断点续传。
# 导入数据时,TiDB Lightning 会记录当前表导入的进度。
# 所以即使 TiDB Lightning 或其他组件异常退出,在重启时也可以避免重复再导入已完成的数据。
enable = true
# 存储断点的数据库名称。
#schema = "tidb_lightning_checkpoint"
# 存储断点的方式。
# - file:存放在本地文件系统。
# - mysql:存放在兼容 MySQL 的数据库服务器。
driver = "file"
# dsn 是数据源名称 (data source name),表示断点的存放位置。
# 若 driver = "file",则 dsn 为断点信息存放的文件路径。
dsn = "/tidb/backup/tidb_lightning_checkpoint.pb"
# 所有数据导入成功后是否保留断点。设置为 false 时为删除断点。
# 保留断点有利于进行调试,但会泄漏关于数据源的元数据。
keep-after-success = false
[tikv-importer]
# 选择后端:“importer” 或 “local” 或 “tidb”
# "local":通过在本地排序生成 SST 文件的方式导入数据,适用于快速导入大量数据,但导入期间下游 TiDB 无法对外提供服务,并且导入的目标表必须为空。
# "importer": 和 “local“ 原理类似,但需要额外部署 “tikv-importer“ 组件。如无特殊情况,推荐使用 “local” 后端。
# "tidb":通过执行 SQL 语句的方式导入数据,速度较慢,但导入期间下游 TiDB 可正常提供服务,导入的目标表可以不为空。
backend = "local"
# 当后端是 “local” 时,本地进行 KV 排序的路径。如果磁盘性能较低(如使用机械盘),建议设置成与 `data-source-dir` 不同的磁盘,这样可有效提升导入性能。
sorted-kv-dir = "/data/sort"
[mydumper]
# 设置文件读取的区块大小,确保该值比数据源的最长字符串长。
read-block-size = "64KiB" # 默认值
# 本地源数据目录或外部存储 URL
data-source-dir = "/tidb/backup"
[tidb]
# 目标集群的信息。tidb-server 的地址,填一个即可。
host = "192.168.2.80"
port = 4001
user = "root"
password = "root"
# 表结构信息从 TiDB 的“status-port”获取。
status-port = 10081
# pd-server 的地址,填一个即可。
pd-addr = "192.168.2.81:2479"
# tidb-lightning 引用了 TiDB 库,并生成产生一些日志。
# 设置 TiDB 库的日志等级。
log-level = "error"
vi /tidb/lightning.sh
#!/bin/bash
nohup tiup tidb-lightning -config /tidb/tidb-lightning.toml > nohup.out &chmod u+x /tidb/lightning.sh
sh /tidb/lightning.sh4) 用户和权限导入
修改/tidb/backup/mysql_exp_grants_out_xxxxxxxx.sql
cp /tidb/backup/mysql_exp_grants_out_xxxxxxxx.sql mysql_exp_grants_out_20220905.sql.bak
vi mysql_exp_grants_out_xxxxxxxx.sql
修改不导入root用户
mysql -h192.168.2.80 -P4001 -uroot -p
source /tidb/backup/mysql_exp_grants_out_xxxxxxxx.sql5) 验证下游已恢复数据和用户权限
4. TiCDC启用正向同步任务
从全量备份的 metadata 文件中获取 commit-ts,作为 TiCDC 同步的开始时间戳。

tiup cdc cli capture list --pd=http://192.168.2.81:2379
tiup cdc cli changefeed create --pd=http://192.168.2.81:2379 --sink-uri="mysql://root:root@192.168.2.80:4001/" --changefeed-id="replication-task-1" --sort-engine="unified" --start-ts=439108994059206663
tiup cdc cli changefeed list --pd=http://192.168.2.81:2379
tiup cdc cli changefeed query --pd=http://192.168.2.81:2379 --changefeed-id=replication-task-1
5. 应用停服务,tidb 无业务会话连接
• 停机窗口,应用停服务。
• 断开F5连接进程。
• 重启 tidb 节点,确保 tidb 无业务会话连接。
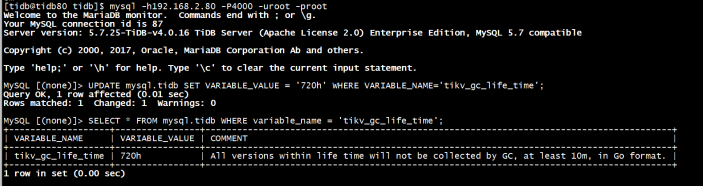
6. 确认数据已完全同步,停止正向同步任务
tiup cdc cli changefeed pause --pd=http://192.168.2.81:2379 --changefeed-id replication-task-17. 数据校验
Bash
sync-diff-inspector.toml:
# Diff Configuration.
######################### Global config #########################
# 日志级别,可以设置为 info、debug
log-level = "info"
# sync-diff-inspector 根据主键/唯一键/索引将数据划分为多个 chunk,
# 对每一个 chunk 的数据进行对比。使用 chunk-size 设置 chunk 的大小
chunk-size = 1000
# 检查数据的线程数量
check-thread-count = 4
# 抽样检查的比例,如果设置为 100 则检查全部数据
sample-percent = 100
# 通过计算 chunk 的 checksum 来对比数据,如果不开启则逐行对比数据
use-checksum = true
# 如果设置为 true 则只会通过计算 checksum 来校验数据,如果上下游的 checksum 不一致也不会查出数据再进行校验
only-use-checksum = false
# 是否使用上次校验的 checkpoint,如果开启,则只校验上次未校验以及校验失败的 chunk
use-checkpoint = true
# 不对比数据
ignore-data-check = false
# 不对比表结构
ignore-struct-check = false
# 保存用于修复数据的 sql 的文件名称
fix-sql-file = "fix.sql"
######################### Tables config #########################
# 配置需要对比的*目标数据库*中的表
[[check-tables]]
# 目标库中数据库的名称
schema = "db1"
# 下面的配置会检查配置库中所有的表
tables = ["~^"]
[[check-tables]]
# 目标库中数据库的名称
schema = "db2"
# 下面的配置会检查配置库中所有的表
tables = ["~^"]
[[check-tables]]
# 目标库中数据库的名称
schema = "db3"
# 下面的配置会检查配置库中所有的表
tables = ["~^"]
[[check-tables]]
# 目标库中数据库的名称
schema = "db4"
# 下面的配置会检查配置库中所有的表
tables = ["~^"]
[[check-tables]]
# 目标库中数据库的名称
schema = "db5"
# 下面的配置会检查配置库中所有的表
tables = ["~^"]
######################### Databases config #########################
# 源数据库实例的配置
[[source-db]]
host = "192.168.2.80"
port = 4000
user = "root"
password = "root"
# 源数据库实例的 id,唯一标识一个数据库实例
instance-id = "source-1"
# 使用 TiDB 的 snapshot 功能,如果开启的话会使用历史数据进行对比
# 目标数据库实例的配置
[target-db]
host = "192.168.2.80"
port = 4001
user = "root"
password = "root"./sync_diff_inspector --config /tidb/sync-diff-inspector.toml
8. 开启回退库的反向TiCDC同步
1) 下游TiCDC节点的扩容
Bash
scale-ticdc2.yaml:
cdc_servers:
- host: 192.168.2.80
ssh_port: 22
port: 8301
deploy_dir: "/tidb-deploy/cdc-8301"
log_dir: "/tidb-deploy/cdc-8301/log"tiup cluster scale-out tidb-test2 /tidb/scale-ticdc2.yaml
tiup cluster display tidb-test2
2) 开启TiCDC反向同步任务
tiup cdc cli capture list --pd=http://192.168.2.81:2479
tiup cdc cli changefeed create --pd=http://192.168.2.81:2479 --sink-uri="mysql://root:root@192.168.2.80:4000/" --changefeed-id="replication-task-1" --sort-engine="unified"
tiup cdc cli changefeed list --pd=http://192.168.2.81:2479
tiup cdc cli changefeed query --pd=http://192.168.2.81:2479 --changefeed-id=replication-task-19. 创建业务用户,取消只读,F5切换到(v6.1.0)集群
10. 业务接入服务,验证服务正常
启动应用,应用侧进行验证。
四、回退方案
1. 回退前提条件
回退前检查
- 生产库 (v6.x.x) 与回退库 (v4.0.x) 数据一致
- 数据追平
2. 回退操作步骤
- 确保数据追平
- 停止生产集群 (v6.x.x) 业务写入生产集群 (v6.x.x) 重启 tidb-server 节点,确认所有 tidb-server 均无连接
- 停止生产环境 (v6.x.x) 的 TiCDC 同步
- 搭建回退库 (v4.0.x) 到生产库 (v6.x.x) 的TiCDC 同步(可选)
- F5 修改地址,回退库 (v4.0.x) 中为业务用户重新赋权,验证业务。
- 修改应用指向到回退库 (v4.0.x)
- 查看回退集群 (v4.0.x) 状态
五、总结
- TiCDC开启之前需要确认业务是否有没主键或唯一键的表,对于没有有效索引的表,insert和 replace 等操作不具备可重入性,因此会有数据冗余的风险。TiCDC 在同步过程中只保证数据至少分发一次,因此开启该特性同步没有有效索引的表,一定会导致数据冗余出现。如果不能接受数据冗余,建议增加有效索引。查出来的没主键的表需提前和客户沟通进行增加主键或唯一键操作。
- 业务切换过程中可以把数据库设为只读状态,防止业务修改写入。
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,后台回复数据库,加入数据库技术交流群。