点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识本文首发于我的知乎:https://zhuanlan.zhihu.com/p/632776455
当你打开电脑,任何时候都在进行着IO的操作!
比如一次 API 接口调用、向磁盘写入日志信息,其实就是在跟 I/O 打交道。
一次 IO 操作分为等待资源、使用资源两个阶段,以下分别进行介绍。
先补充一下什么是阻塞与非阻塞 和同步与异步
同步阻塞IO(Blocking IO):即传统的IO模型
同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。在Java领域,也称为New I/O
IO多路复用(IO Multiplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型
异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO
具体展开来讲一下:
阻塞与非阻塞 I/O
阻塞与非阻塞 I/O 是对于操作系统内核而言的,发生在等待资源阶段,根据发起 I/O 请求是否阻塞来判断。
阻塞 I/O:这种模式下一个用户进程在发起一个 I/O 操作之后,只有收到响应或者超时才可进行处理其它事情,否则 I/O 将会一直阻塞。以读取磁盘上的一段文件为例,系统内核在完成磁盘寻道、读取数据、复制数据到内存中之后,这个调用才算完成。阻塞的这段时间对 CPU 资源是浪费的。
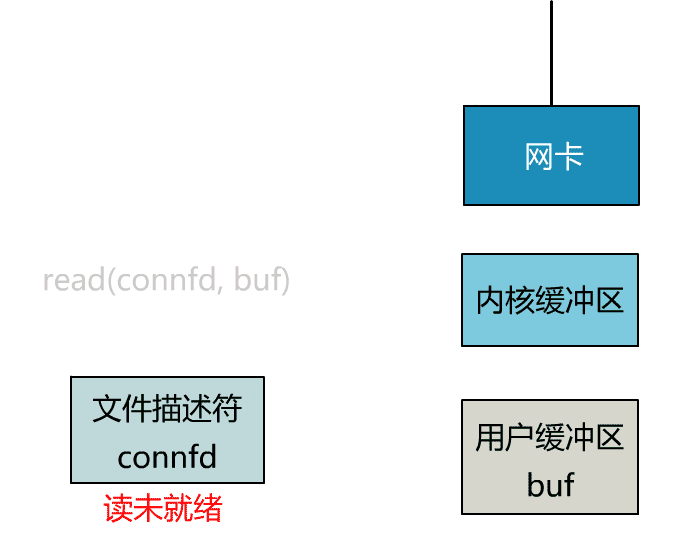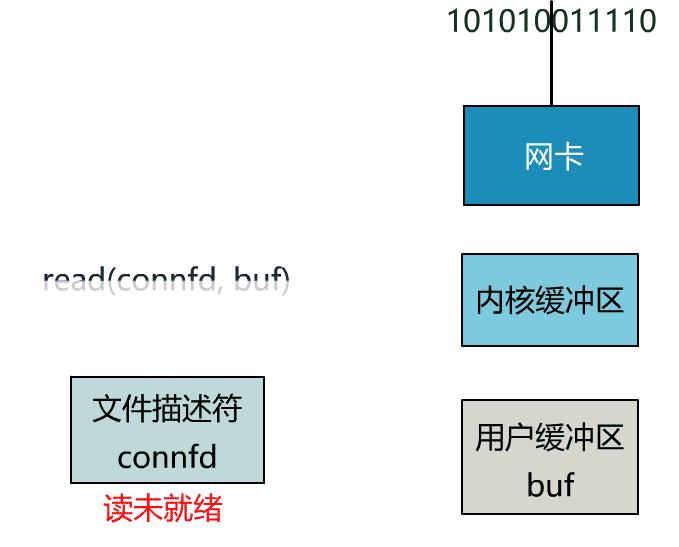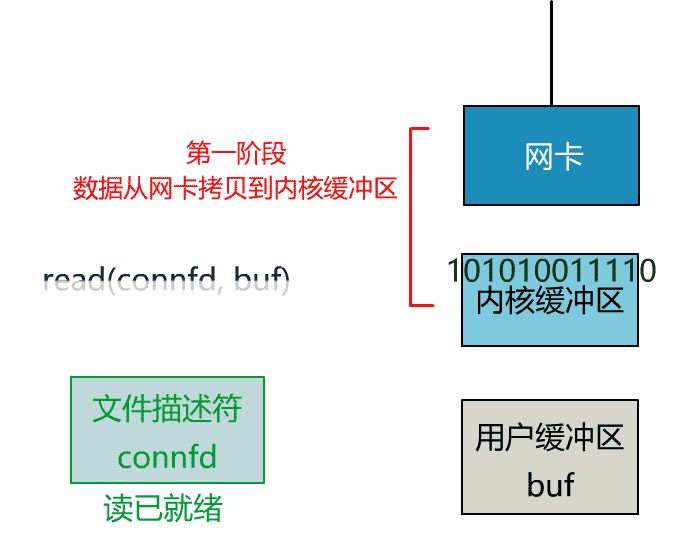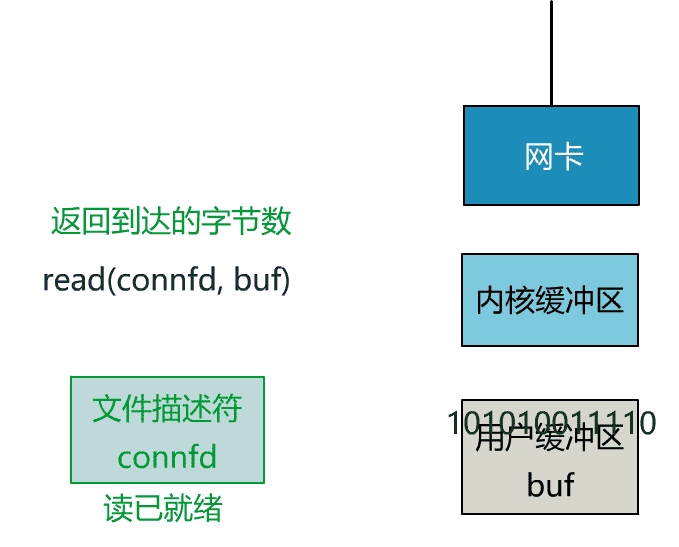
非阻塞 I/O:这种模式下一个用户进程发起一个 I/O 操作之后,如果数据没有就绪,会立刻返回(标志数据资源不可用),此时 CPU 时间片可以用来做一些其它事情。

同步与异步 I/O
同步与异步 I/O 发生在使用资源阶段,根据实际 I/O 操作来判断。
同步 I/O:应用发送或接收数据后,如果不返回,继续等待(此处发生阻塞),直到数据成功或失败返回。
异步 I/O:应用发送或接收数据后立刻返回,数据写入 OS 缓存,由 OS 完成数据发送或接收,并返回成功或失败的信息给应用。Node.js 就是典型的异步编程例子。
什么是IO多路复用
IO多路复用是一种同步IO模型,实现一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出cpu。多路是指网络连接,复用指的是同一个线程
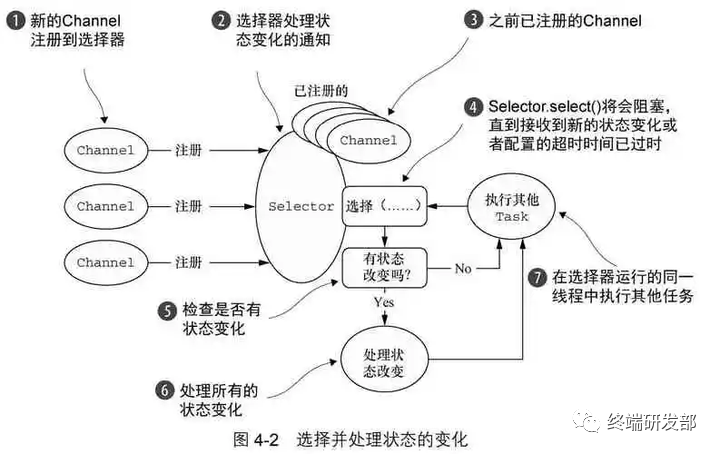
IO多路复用使用的模型
select模型
poll模型
epoll
具体展开来讲一下
select模型
select模型是最古老的IO多路复用机制之一,使用fd_set数据结构来保存文件描述符集合,并提供了select()函数来等待文件描述符的就绪状态。它有一个限制,即所监视的文件描述符数量有一个上限,通常是1024。

每次调用select()时,都需要将整个文件描述符集合从用户空间复制到内核空间,这可能带来性能问题。
poll模型
是对select的改进,它使用pollfd结构体数组来保存文件描述符和事件信息,并提供了poll()函数来等待文件描述符的就绪状态。相对于select,poll没有文件描述符数量的限制,因为它使用动态分配的数组来保存文件描述符信息。
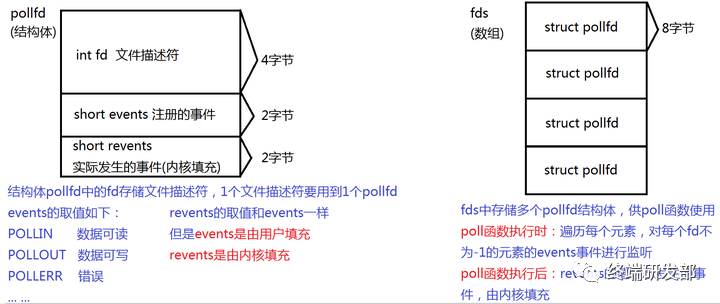
但与select类似,每次调用poll()时,也需要将整个结构体数组从用户空间复制到内核空间。
epoll模型
是Linux特有的IO多路复用机制,自从2.5.44内核版本引入后成为主流。它使用基于事件的方式来管理文件描述符,使用一个事件表(event table)来保存文件描述符和事件信息,并提供了epoll_create()、epoll_ctl()和epoll_wait()等函数来操作事件表。
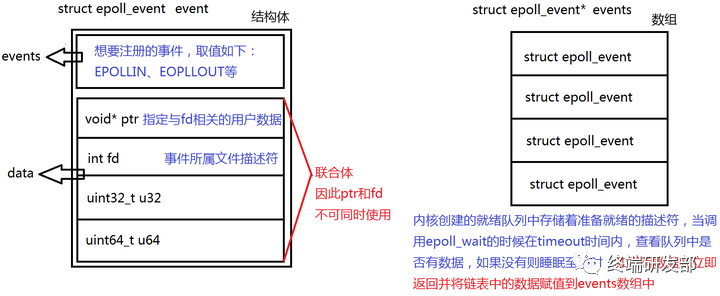
相对于select和poll,epoll具有更好的性能,因为它采用了事件驱动的方式,不需要在每次调用时复制整个事件表。
PS:很多文章在谈论到BIO、NIO、AIO的时候仅仅是抛出一堆定义,以及一些生动的例子。看似很好理解。但是并没有将最基础的本质原理显现出来,如果没有没有从IO的原理出发的话是很难理解这三者之间的区别的。所以本篇文章从Java是如何进行IO操作为开头进行分析。
终端研发部:这是我看过对bio,nio,aio解释的最透彻的文章!!!151 赞同 · 6 评论文章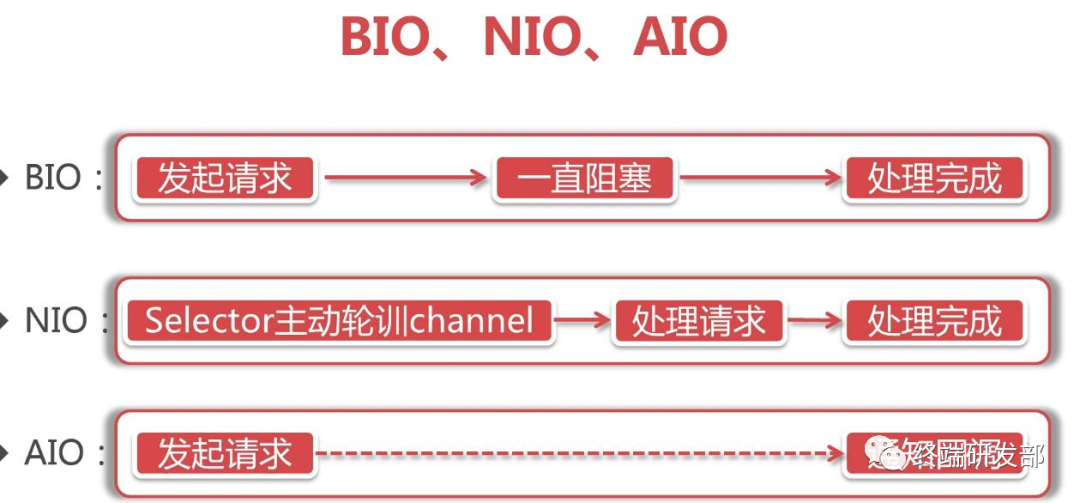
IO多路复用解决的问题
阻塞与非阻塞
解决接收数据前的耗时问题
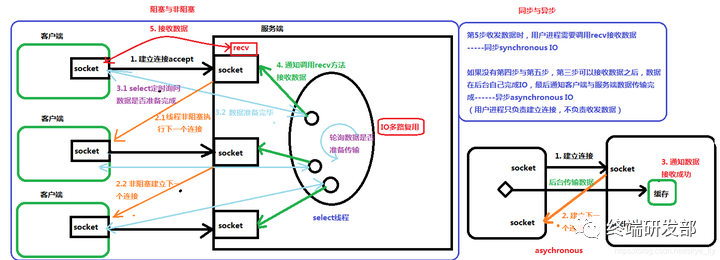
客户端向服务端发起请求,建立连接
双方会收发数据,但是如果一方没有成功发送数据,另一方的线程就会阻塞。
采用select()等多路复用模式,集中到一个线程去监听多个连接上对方的数据是否准备完毕,
如果select收到对方线程准备发送数据的信号,就会通知用户进程调用recv方法去接收连接上输送的数据
recv本身也可长期监听连接对方的数据是否有发送,但是recv的资源开销比较大只能一对一监听,select多路复用开销小,可以一对多监听
同步与异步
解决接收数据时的耗时问题
IO多路复用可以在一定程度上解决阻塞IO和同步IO的问题。通过使用IO多路复用,程序可以同时监视多个IO流,而不会阻塞在单个IO操作上。当某个IO流就绪时,程序可以立即进行处理,而不需要等待其他IO操作的完成。通过将IO流设置为非阻塞模式,程序可以立即返回并继续执行其他任务,而不必等待IO操作的完成。
多路复用的优点
多路复用可以在一个连接上同时处理多个请求响应,这样可以大大的减少连接的数量,并提高了网络的处理能力。
由于是共享连接不同请求响应数据包可以合并到一个IO上处理,这样可以大大降低IO的处理量,让性能表现得更出色。
多路复用的基本原则,就是尽量减少因IO读取而造成的频繁系统调用。所谓多路复用,是指通过一次系统调用,获得IO状态,获取到IO状态之后,由APP自己对符合状态的IO进行读写操作。
无论是BIO,NIO还是多路复用,都是同步IO模型,其中BIO是同步阻塞模型,NIO和多路复用是同步非阻塞模型。
补充:
redis的网咯IO
Redis 使用 epoll 作为 I/O 多路复用技术的实现;Redis 自身的事件处理模型将 epoll 中的连接、读写、关闭都转为时间,从而避免了在网络 I/O 上时间的浪费。
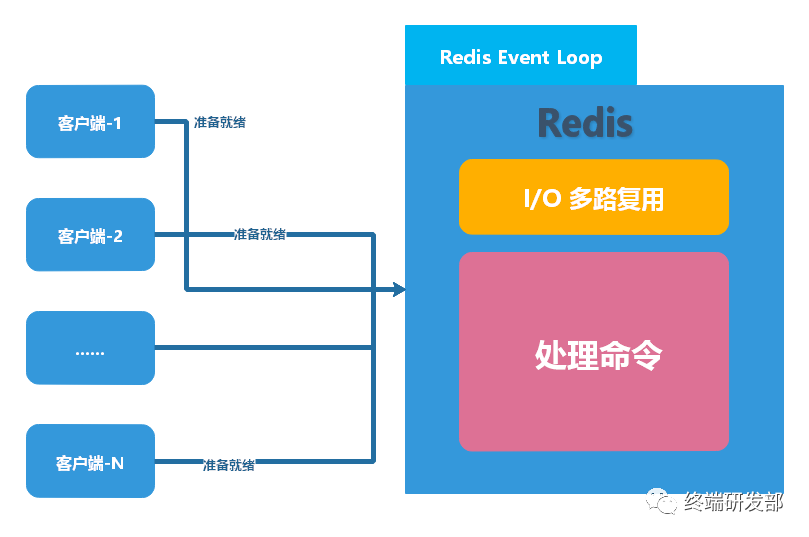
避免了线程切换和竞态产生的消耗。
影响Redis耗时的操作
对bigkey的写入删除操作;
sql语句复杂(Redis使用的是同步IO,高并发时此处会阻塞主线程,6.0后使用多线程机制执行sql语句);
同时删除大量key;
AOF设置为高频率写入磁盘;
不合理的key淘汰机制(内存满了后要先删除部分旧的key才能写入新的key,高版本Redis优化后采用了异步线程来执行淘汰)。
Redis 6.0多线程模型思想上类似单reactor多线程和多reactor多线程,但不完全一样,这两者handler对于逻辑处理这一块都是使用线程池,而redis命令执行依旧保持单线程。如下:
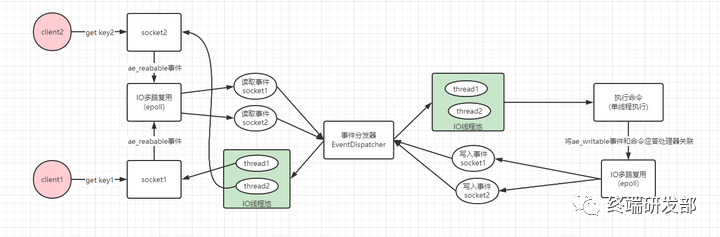
Redis的优化
Redis 基于的底层 I/O 多路复用库有多套。包括select、epoll、evport和kqueue等。
每个IO多路复用函数库在 Redis 源码中都对应一个单独的文件,比如ae_select.c,ae_epoll.c, ae_kqueue.c等。调用 epoll 机制,让内核监听这些套接字。Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。
正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。
补充:
BIO、NIO、AIO适用场景分析:
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
我是程序员小于哥
@终端研发部
每天专注于Java面试,技术编程技巧,互联网科技的分享,关注我职场技术不迷路,笔芯哦~
如果看到这里,说明你喜欢这篇文章,请 转发、点赞。同时 标星(置顶)本公众号可以第一时间接受到博文推送。

回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
lazy-mock ,一个生成后端模拟数据的懒人工具
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
字节跳动一面:i++ 是线程安全的吗?
一条 SQL 引发的事故,同事直接被开除!!
太扎心!排查阿里云 ECS 的 CPU 居然达100%
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的
在这里获得的不仅仅是技术!


喜欢就给个“在看”
![[数据结构习题]栈——中心对称链](https://img-blog.csdnimg.cn/5e936a0dc79247a9b1ff7e8c3daefec8.gif#pic_center)

![新Linux服务器安装Java环境[JDK、Tomcat、MySQL、Nacos、Redis、Nginx]](https://img-blog.csdnimg.cn/df468fd399484871b7ad3e4b7af26684.png)