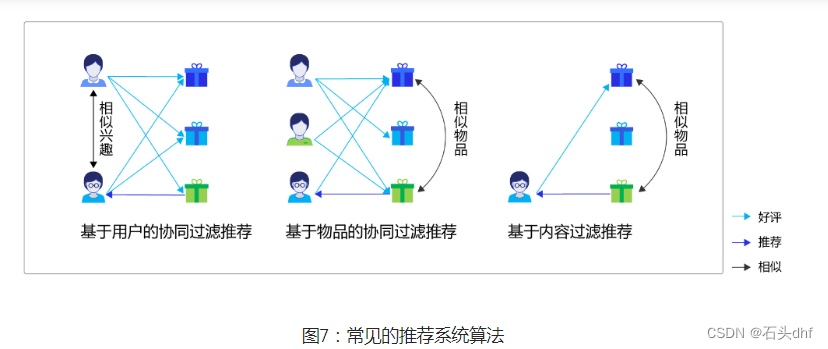
常用的推荐系统算法实现方案有三种:
-
协同过滤推荐(Collaborative Filtering Recommendation):该算法的核心是分析用户的兴趣和行为,利用共同行为习惯的群体有相似喜好的原则,推荐用户感兴趣的信息。兴趣有高有低,算法会根据用户对信息的反馈(如评分)进行排序,这种方式在学术上称为协同过滤。协同过滤算法是经典的推荐算法,经典意味着简单、好用。协同过滤算法又可以简单分为两种:
a)基于用户的协同过滤:根据用户的历史喜好分析出相似兴趣的人,然后给用户推荐其他人喜欢的物品。假如小李,小张对物品A、B都给了十分好评,那么可以认为小李、小张具有相似的兴趣爱好,如果小李给物品C十分好评,那么可以把C推荐给小张,可简单理解为“人以类聚”。
b)基于物品的协同过滤:根据用户的历史喜好分析出相似物品,然后给用户推荐同类物品。比如小李对物品A、B、C给了十分好评,小王对物品A、C给了十分好评,从这些用户的喜好中分析出喜欢A的人都喜欢C,物品A、C是相似的,如果小张给了A好评,那么可以把C也推荐给小张,可简单理解为“物以群分”。
-
基于内容过滤推荐(Content-based Filtering Recommendation):基于内容的过滤是信息检索领域的重要研究内容,是更为简单直接的算法,该算法的核心是衡量出两个物品的相似度。首先对物品或内容的特征作出描述,发现其相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。比如,小张对物品A感兴趣,而物品A和物品C是同类物品(从物品的内容描述上判断),可以把物品C也推荐给小张。
-
组合推荐(Hybrid Recommendation):以上算法各有优缺点,比如基于内容的过滤推荐是基于物品建模,在系统启动初期往往有较好的推荐效果,但是没有考虑用户群体的关联属性;协同过滤推荐考虑了用户群体喜好信息,可以推荐内容上不相似的新物品,发现用户潜在的兴趣偏好,但是这依赖于足够多且准确的用户历史信息。所以,实际应用中往往不只采用某一种推荐方法,而是通过一定的组合方法将多个算法混合在一起,以实现更好的推荐效果,比如加权混合、分层混合等。具体选择哪种方式和应用场景有很大关系。

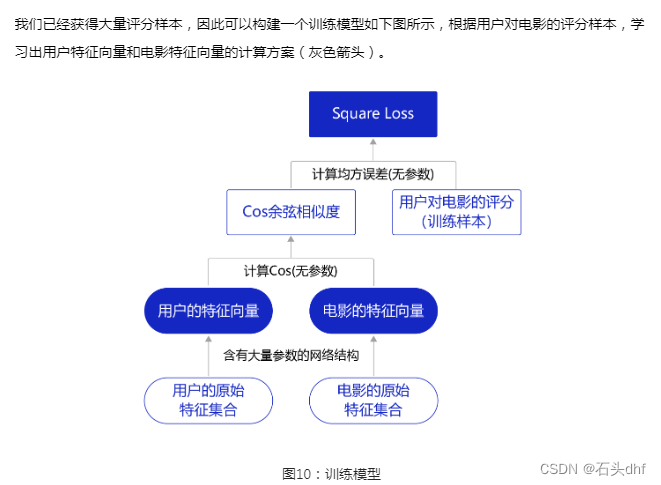
但不同类型的原始特征应该如何变换?有哪些网络设计细节需要考虑?我们将在后续几节结合代码实现逐一探讨,包括四个小节:
- 数据处理,将MovieLens的数据处理成神经网络理解的形式。
- 模型设计,设计神经网络模型,将离散的文字数据映射为向量。
- 配置训练参数并完成训练,提取并保存训练后的数据特征。
- 利用保存的特征构建相似度矩阵完成推荐。