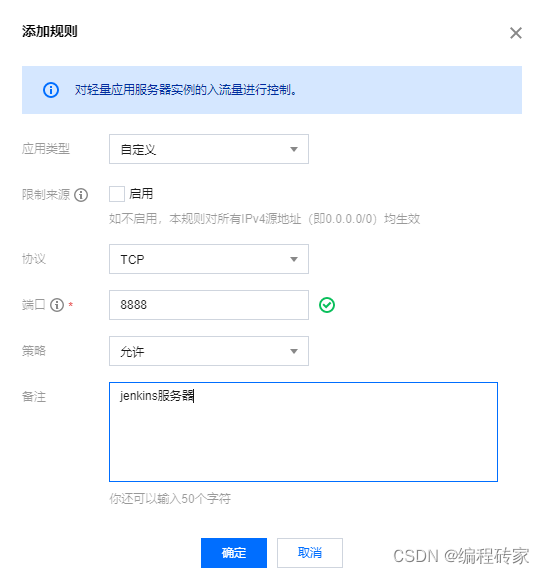
应用程序到数据库到操作系统到固态硬盘
在我研究了从应用程序发送的简单 SQL 查询是如何最终存储到磁盘的过程中,我发现术语 “页(page)” 和 “块(block)” 可能是软件工程中最多用的概念之一。有数据库页(database page),操作系统虚拟内存页(virtual memory page),文件系统块(file system block),固态硬盘页(SSD page),两种类型的固态硬盘块(SSD block),其中一个称为逻辑块(logical block),对应于文件系统,另一个是更大的单元,称为擦除块(erase unit),其中包含多个页。所有这些单元都可以具有不同的大小,有些匹配,有些不匹配。
在本文中,我将详细介绍一个 SELECT 语句以及在执行过程中不同层次的输入 / 输出(I/O)是如何一直执行到磁盘的底层。
这里是我们将要解释的完整图示:
但首先,基础知识
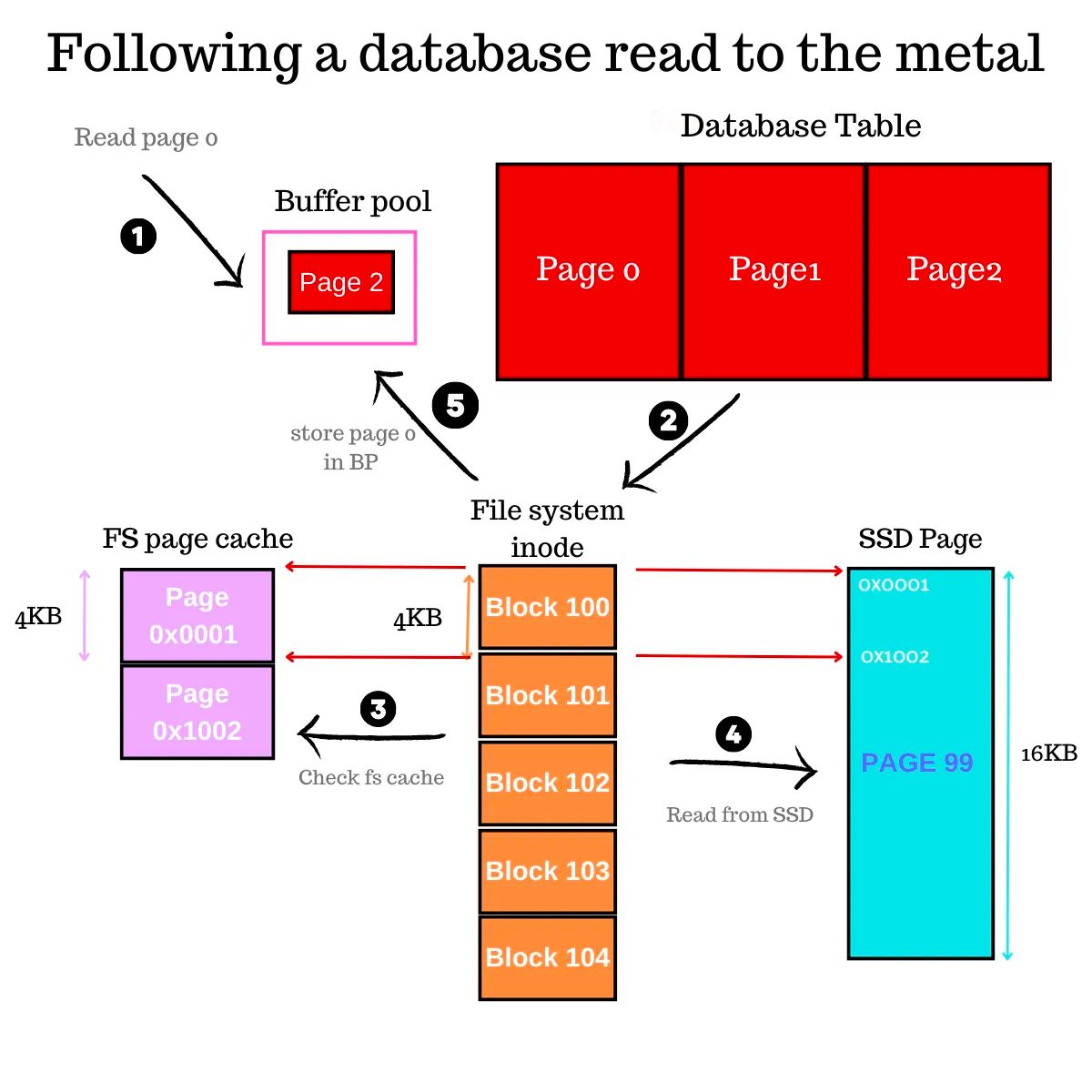
当您在数据库中创建一个表时,会在磁盘上创建一个文件,并将数据布局在固定大小的数据库页中。数据在页中的布局方式取决于引擎是行存储还是列存储。将页视为一种结构,它具有标头和数据,数据部分是行所在的位置。
数据库页可以是 8KB(Postgres)或 16KB(例如 MySQL InnoDB)或更大。表被存储为文件中的页数组,其中页面索引 + 大小告诉数据库确切的偏移量和读取量。例如,假设数据库页大小为 8KB,要从磁盘上读取第 7 页,您需要寻找偏移量 7 * 8192 + 1,并且您将读取 8192 字节的长度。
行及其所有列依次存储在页中。如果行无法适应页中剩余的空间,则会分配一个新页面,并将该行放入新页面中。
当从磁盘读取页面并放入缓冲池时,我们可以免费获取该页面中的任何行(和列)。无论您是否相信,这可能是数据库优化和数据建模中最重要的认识。
有了这些基础知识,让我们执行此查询,查询表为 “STUDENTS”,其中包含一个类型为 “serial” 的 ID 字段(单调递增)。该表有 20,000 行,分布在 20 个页面中。我们所需的行(1008 行)位于页面 1(第二个页面)。缓存中没有任何数据。为了保持简单,我不打算在这里包含索引,只是为了保持简单,虽然会比较慢。为简洁起见,我只画出前三个页面。
SELECT NAME FROM STUDENTS WHERE ID = 1008;无论我们是使用主索引作为表的聚簇索引,还是在没有主索引的情况下使用堆表(如在 PostgreSQL 中),我认为这里的模型是相似的。尽管 ID 字段没有建立索引,在 InnoDB 的情况下,您可以将另一个字段视为主键,它会强制我们进行全索引扫描,其中我们读取主索引的叶子页面;而在 PostgreSQL 中,则会对表进行顺序扫描。我们假设每个页面大小为 8KB。
数据库
数据库解析并理解查询,由于 ID 字段没有建立索引,所以它进入了全表扫描模式,以获取值为 1008 的行。
数据库从页面 0 开始,并检查页面 0 是否在缓冲池中。缓冲池是所有数据库进程之间共享的内存空间,用于存储页面,也可以在其中进行写入操作。数据库没有找到页面 0,因此它向表文件发送读取页面 0 的请求。
文件的偏移量是 0*8192,我们要读取 8192 字节。页面被读取并放置在共享缓冲区内存中。页面包含行 1 到 1000,数据库解析页面,反序列化并在内存中查找每行的 ID 值,但没有找到。因此,我们继续读取页面 1。
读取页面 1 时,文件的偏移位置为 1*8192,我们要读取 8192 字节。页面 1 被放置在共享缓冲区中,与页面 0 一起存储。数据库在页面中查找行 1008,并找到并返回给用户。
现在让我们进一步细分,看看数据库向操作系统发出读取请求时会发生什么。
文件系统
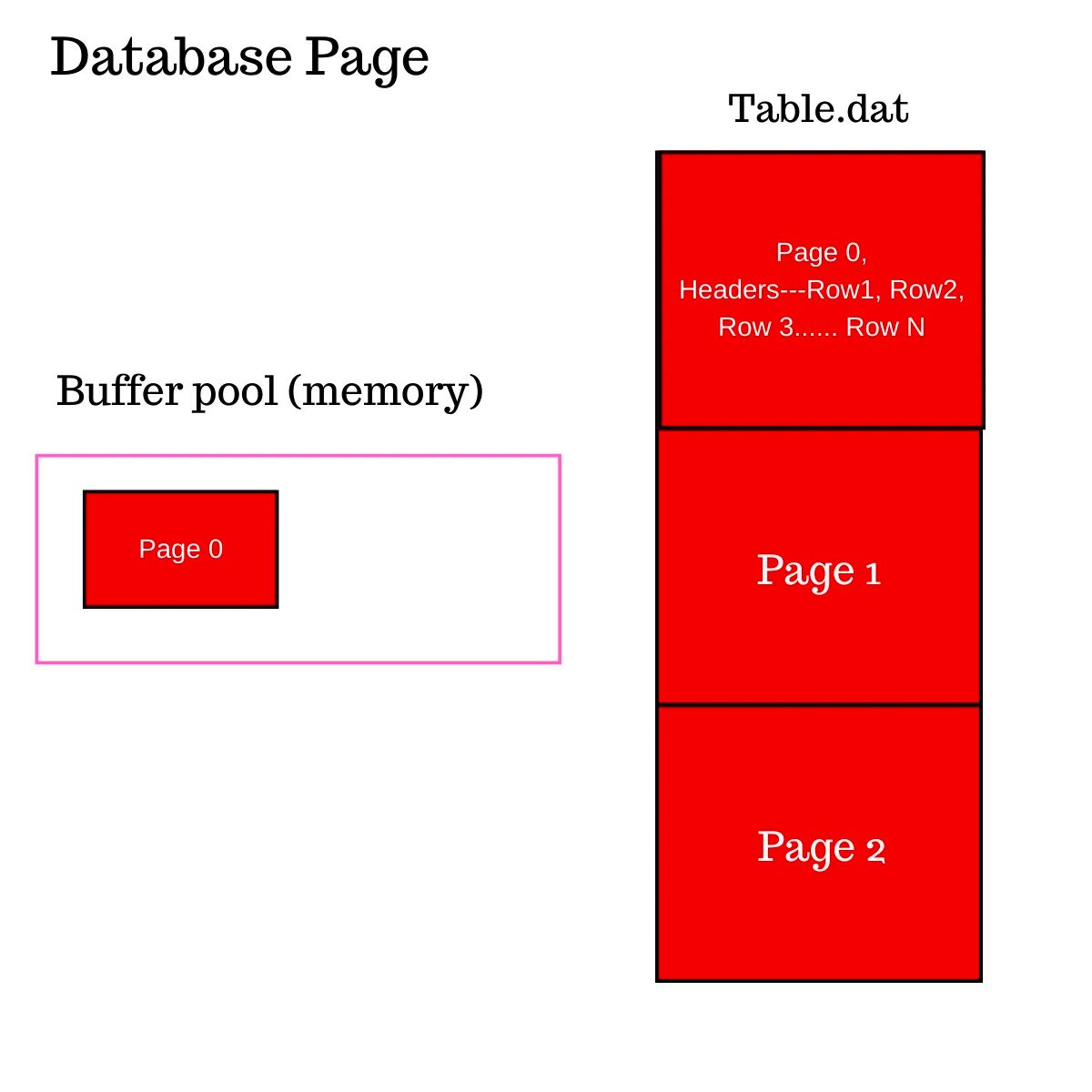
文件系统以块或逻辑块的单位从磁盘读取和写入数据。这些单位的大小可以从 512 字节到 4KB 不等,其中 4KB 是最常见的大小。
操作系统接收到读取文件偏移量为 0,读取 8192 字节的请求,并使用文件系统索引节点或 "inode" 将请求的字节映射到文件系统块。每个逻辑文件系统块地址(LBA)映射到存储设备中的特定物理块,我们将在后面学到这一点。如果您读取单个字节,实际上会从磁盘中读取整个块。
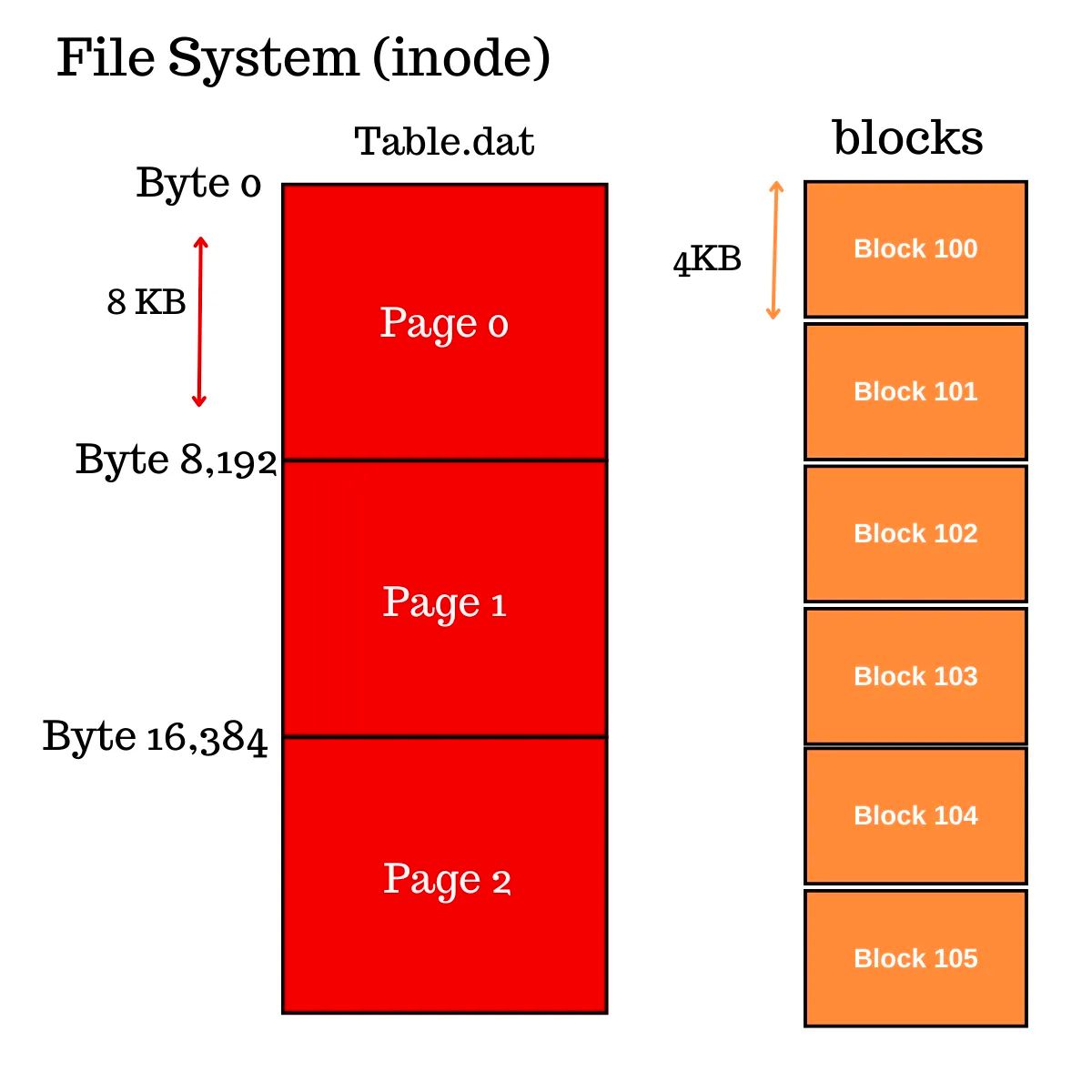
当请求从偏移量 0 开始读取 8192 字节时,操作系统执行以下检查:
- 文件的偏移量 0 到 8192 字节之间的块是哪些?
- 假设文件系统块大小为 4KB,则得到两个块。
- 文件系统查找文件的索引节点以查找逻辑块地址(LBA),假设这些块是 100 和 101。
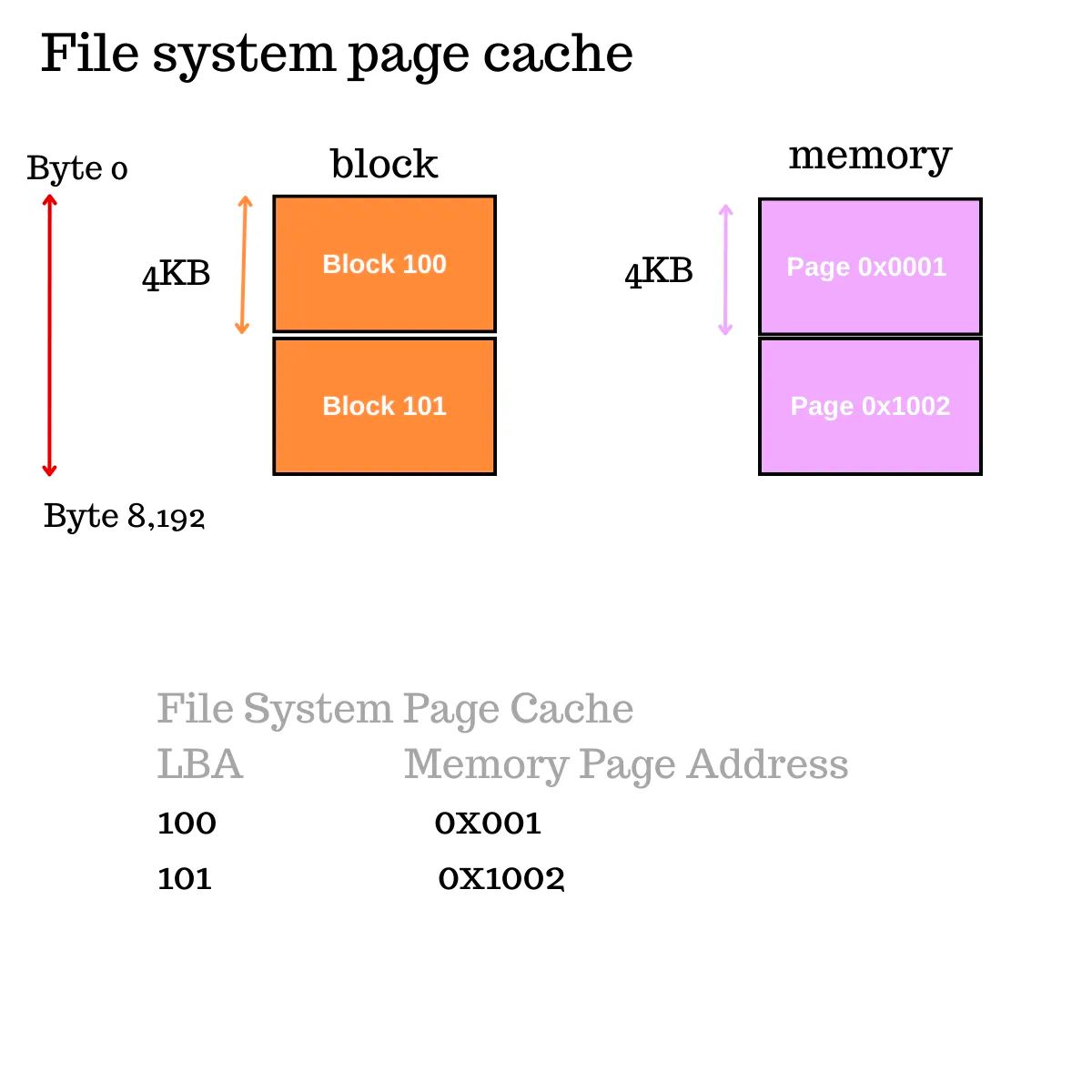
- 操作系统然后在文件系统页缓存中查找块 100 和 101,以查看先前的读取是否已将它们获取并放置在内存中。
- 文件系统页缓存位于内存中,存储块地址和主内存中虚拟内存页的地址。
- 操作系统中的虚拟内存页通常是 4KB,与块大小相匹配。因此,一个块可以适配到一个内存页中。
- 假设操作系统在页缓存中未找到块 100 和 101,因此准备从磁盘中读取。
注意,索引节点包含有关文件的其他元数据,例如权限信息。
存储
我们了解到读取页 0 相当于偏移量 0 和长度 8192,它被转换为文件系统块 100 和 101,每个块的大小为 4KB。操作系统检查了缓存,但找不到这些块,因此从磁盘中读取。
假设使用 NVMe 固态硬盘,操作系统通过 NVMe 驱动向存储设备发送读取命令。读取命令有许多参数,但最重要的是起始 LBA(逻辑块地址),第二个参数是要读取的块数。这意味着驱动程序发出了一个读取命令,传递了 (100, 0)。长度为 0 表示在 NVM 命令集中读取 1 个块。
现在有趣的地方来了。在 NVMe 中,“块” 的大小可能与文件系统块大小不同。例如,在这里我们假设 NVMe 块与文件系统块大小相同,都是 4KB。如果它们不同,操作系统需要更改读取参数。例如,如果 NVMe 块大小为 2KB,则文件系统块大小将包含 2 个 NVMe 块。因此,读取命令将为 101, 3。
固态硬盘(SSD)被分成页面,这是最小的读写单元。SSD 的 NAND 页面目前的大小为 16KB。页面被分组成更大的单元,通常也称为块,以擦除单元的方式。要写入 SSD 页面,页面必须处于擦除状态,而单独擦除页面是不可能的,必须擦除整个擦除单元。
现在,我们的 NVMe 逻辑块地址映射到这个页面中的一个偏移量。因此,在这种情况下,由于我们的 NVMe 逻辑块大小为 4KB,4 个块适合于 SSD NAND 页面。
SSD 实际上并不使用逻辑块地址,它只知道页面的物理位置。因此,需要进行从逻辑块地址到物理页面偏移量的转换。由于 SSD 页面可以大于块,多个块可以映射到不同偏移量的同一页面上。
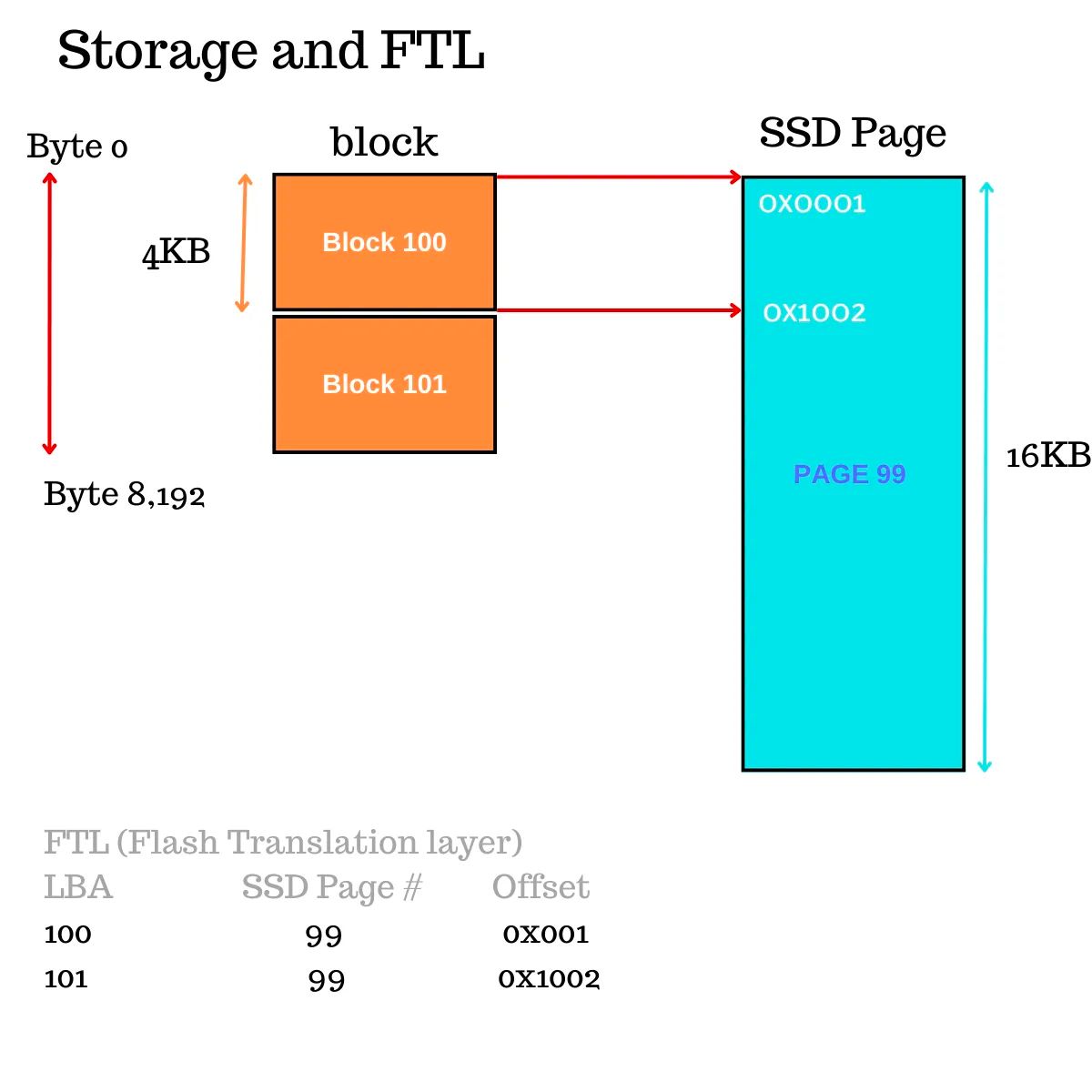
NVMe 控制器接收到读取 LBA 100 和 LBA 101 的命令,NVMe 驱动器的一个特点是,这些逻辑块地址(这两个块)被转换为物理页面和偏移量,例如页面 99 和偏移量 0x0001 和 0x1002。接下来,NVMe 控制器检查本地 SSD DRAM 缓存,以查看页面 99 是否在缓存中。是的,这里有一个 SSD 缓存。如果页面 99 不在缓存中,则整个页面(整个 16KB)被完全获取到缓存中并放置在缓存中。
一旦页面完全被获取到缓存中(整个 16KB),相应的块会从页面中提取并返回给操作系统主机。在这种情况下,只返回了前 8KB。
你可能会问为什么不让操作系统直接访问页面的物理地址?为什么需要进行这种转换?原因是磁盘有时需要移动数据,当操作系统指向物理位置时,移动数据变得困难。
具有讽刺意味的是,可以将数据的移动卸载到主机上,但这不会增加应用程序的复杂性成本。没有免费的午餐。这是一个深入研究的课题,你可以决定深入探索。
回到文件系统
操作系统获取代表两个块(100、101)的 8KB 数据,并将其放入两个内存页面中。然后,它更新文件系统页面缓存,以便下一次请求读取 100 或 101 时可以从主机内存中获取。
回到数据库
然后,操作系统将控制权返回给数据库应用程序,如果你还记得,它发出了读取偏移量为 0、长度为 8192 的请求,对应于页面 0。数据库将原始字节放入共享缓冲池内存(与文件系统缓存不同)。页面 0 现在对于从中提取数据的任何其他查询都是 “热点”,在刷新到磁盘之前,页面 0 可以接收写入操作。
当然,下一个页面,即页面 1,也经历了同样的过程,直到找到行 ID 为 1008 的行。
总结
要从数据库中读取一行数据,你必须读取包含该行的页面。为了读取数据库页面,数据库会向文件发出正确偏移量和长度对应于页面的读取请求。操作系统将这些字节映射到文件系统块地址(或 LBAs),对比文件系统页面缓存,看是否存在具有这些块的内存页面。否则,会向存储控制器发送读取命令。设备将逻辑块转换为物理地址,并将页面加载到缓存中,并将所请求的字节返回给操作系统主机。主机将块放入文件系统页面缓存,并返回给数据库,数据库将页面放入共享缓冲池中并开始处理,并将所请求的单行返回给用户。
如果你使用索引会怎样?类似的情况,索引是存储在磁盘上的 B + 树结构,也具有页面。在遍历树时,你将获取页面,因此概念是相同的。
如果你喜欢我的文章,点赞,关注,转发!