0. 引言
上节,我们讲解了solr的核心配置文件managed-schema,了解定义索引的核心配置标签,今天我们来实操配置,创建一个索引
solr快速上手:solr简介及安装(一)
solr快速上手:核心概念及solr-admin界面介绍(二)
solr快速上手:managed-schema标签详解(三)
1. 业务场景概述
本次我们来创建一个订单索引,该索引包含如下字段,并且设置从数据库同步数据
| 字段 | 说明 | 数据类型 |
|---|---|---|
| id | 订单id | long |
| order_no | 订单号 | string |
| product_name | 商品名称 | string |
| create_time | 创建时间 | date |
| create_user | 创建人 | string |
| remarks | 备注 | string |
| status | 订单状态 | int |
| address | 地址 | string |
| labels | 商品标签(多个) | string |
2. 新建索引
1、在solr安装路径的server/solr文件夹下创建一个新文件夹,名称与索引名称一致,用于存放新索引相关配置文件
cd /data/solr-8.2.0
mkdir server/solr/orders
2、我们在上节讲到,可以通过复制server/solr/configsets/_default/conf来快速创建新的索引,那么我们先复制该配置文件夹到我们创建的orders下
cp -R server/solr/configsets/_default/conf/* server/solr/orders
3、修改managed-schema配置文件,因为带了很多默认配置,如果都不需要或者觉得删除麻烦的话,可以重新创建一个managed-schema文件,文件配置内容如下:
注意:
_version_字段要开启索引和排序- 所有字段用到的fieldType要在配置文件中显示配置
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="default-config" version="1.6">
<!-- 默认字段,不需要的可以删除 -->
<field name="id" type="long" indexed="true" stored="true" required="true" multiValued="false" />
<!-- docValues are enabled by default for long type so we don't need to index the version field -->
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- 定义字段 -->
<field name="order_no" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="product_name" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="create_time" type="date" indexed="true" stored="true" required="true" multiValued="false" />
<field name="create_user" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="remarks" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="status" type="int" indexed="true" stored="true" required="true" multiValued="false" />
<field name="address" type="text_general" indexed="true" stored="true" required="true" multiValued="false" />
<field name="labels" type="string" indexed="true" stored="false" required="true" multiValued="true" />
<uniqueKey>id</uniqueKey>
<!-- 要声明使用的type -->
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</schema>
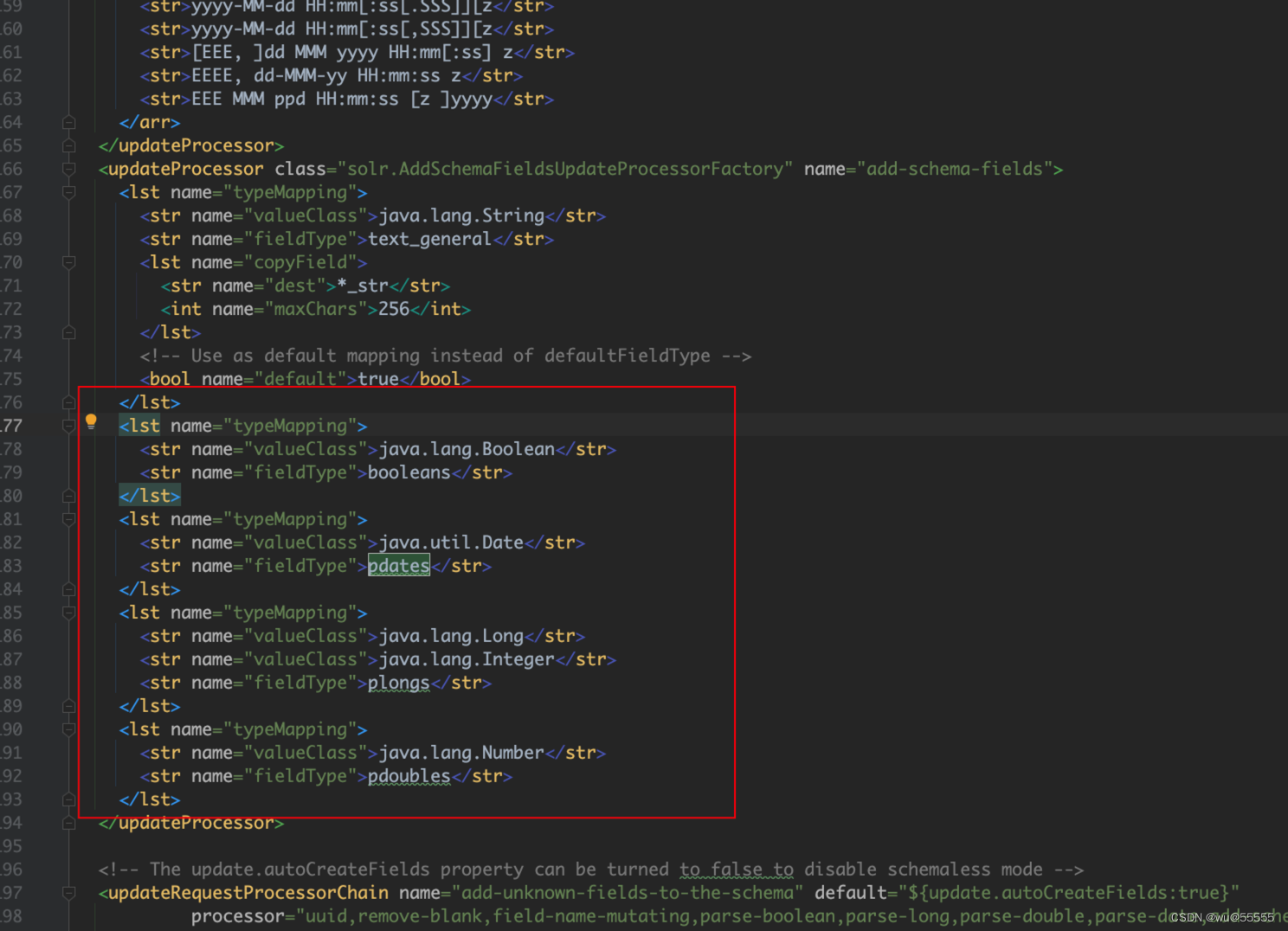
4、修改solrconfig.xml配置文件,因为里面有一些不需要的默认配置,我们需要将其去除:
比如这些typeMapper的类型我们都没用到,自然不需要
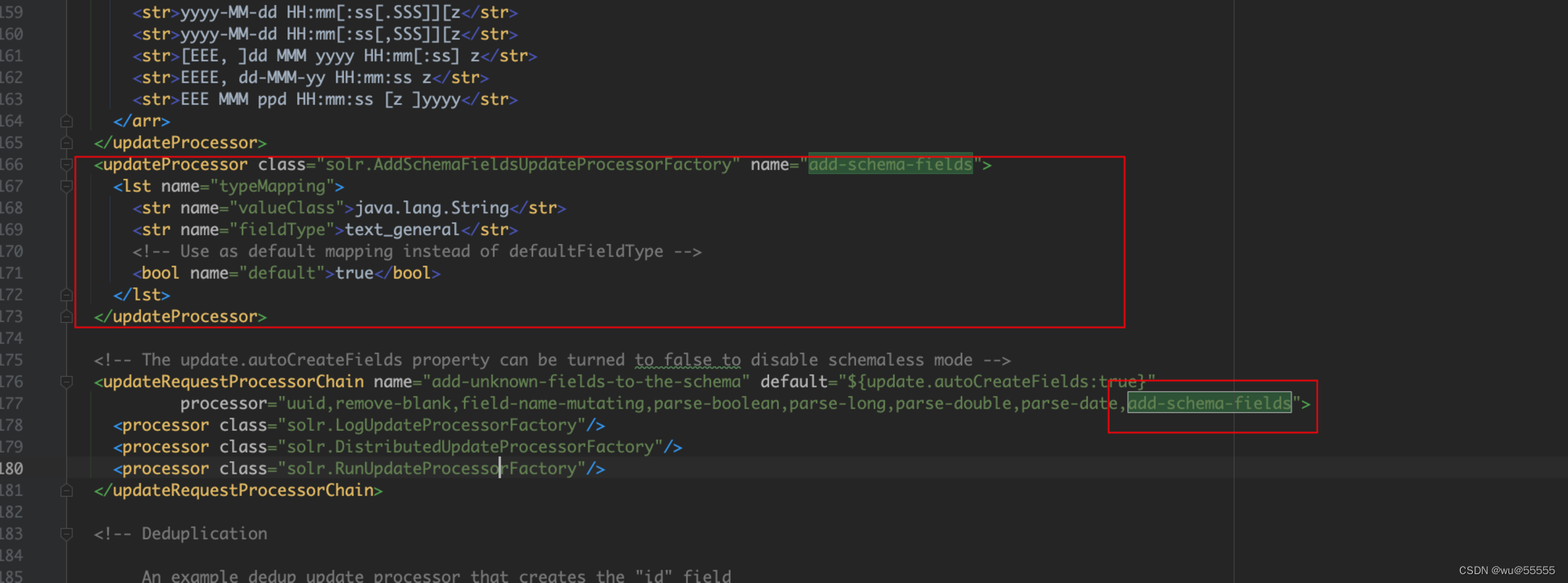
将下图中的add-schema-fields整个updateProcessor标签配置及引用处删除,如下,后续我们详细讲解solrconfig.xml的配置详情,这里我们先以创建好索引为主
5、在solr管理界面,core-admin菜单,点击add core新增索引,默认采用的是schema.xml的形式,如果你想要采用这种形式,如上节所说,需要在server/solr/orders/solrconfig.xml中添加配置<schemaFactory class="ClassicIndexSchemaFactory"/>
这里我们直接用默认的managed-schema来演示
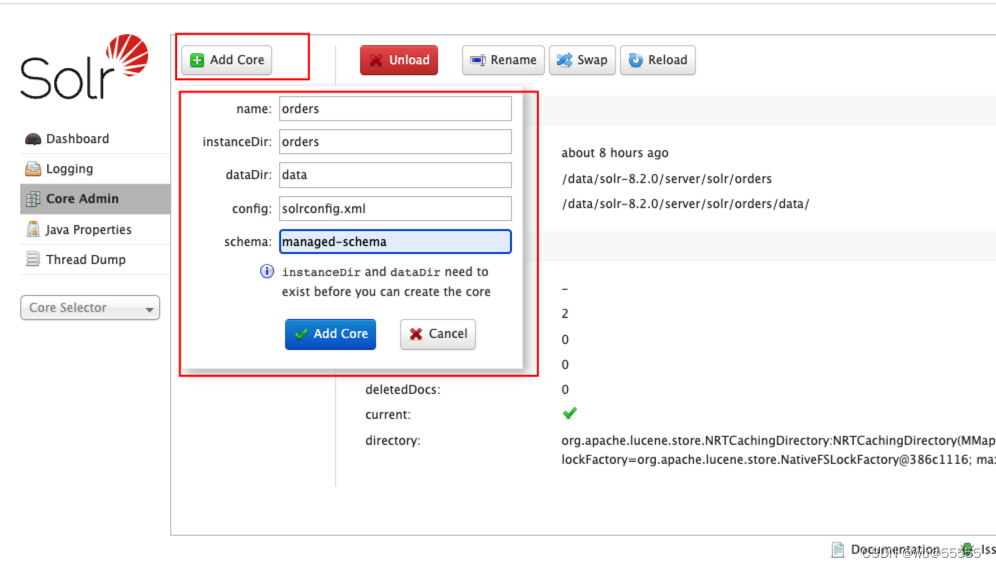
6、创建成功后,在schema页面可以看到索引的字段结构
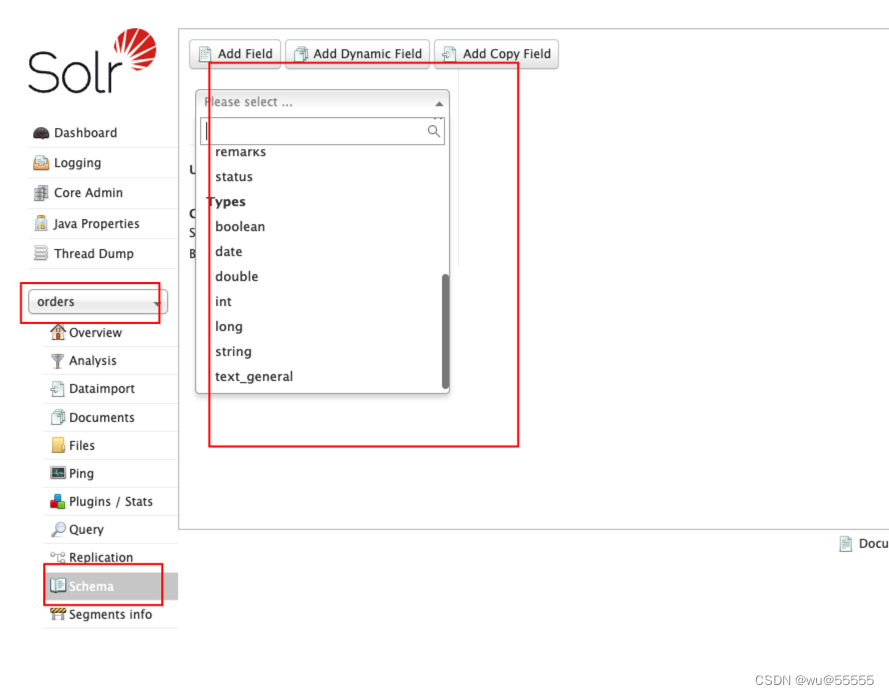
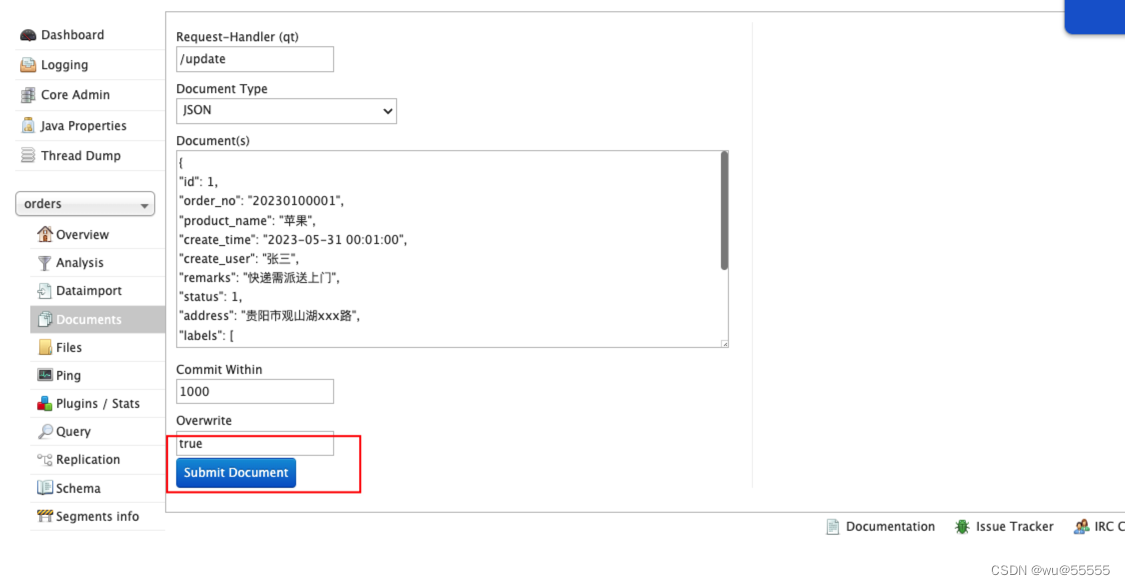
7、我们通过update接口新增几笔数据用于测试
{
"id": 1,
"order_no": "20230100001",
"product_name": "苹果",
"create_time": "2023-05-31 00:01:00",
"create_user": "张三",
"remarks": "快递需派送上门",
"status": 1,
"address": "贵阳市观山湖xxx路",
"labels": [
"水果",
"24小时",
"生鲜链",
"送货上门"
]
}
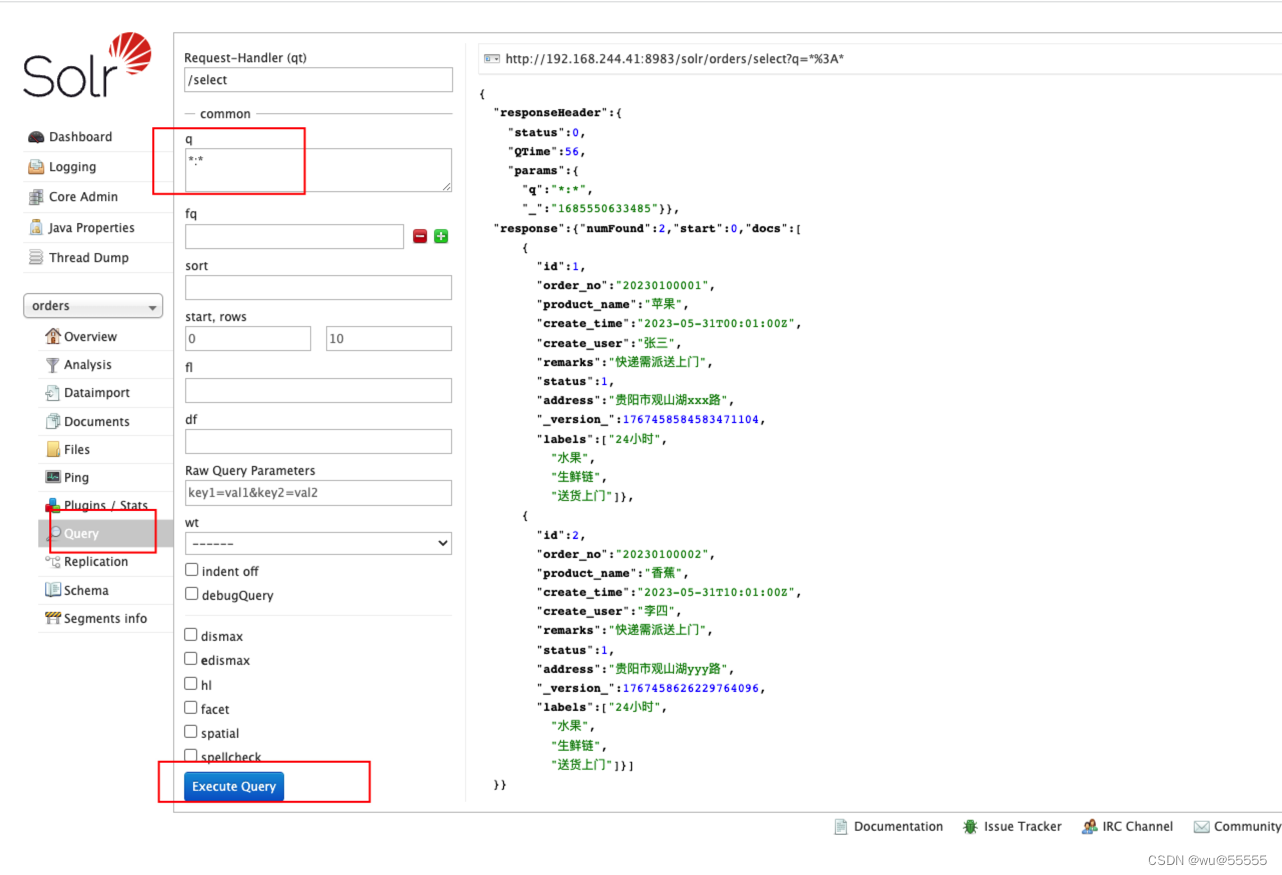
8、点击全查询,可以看到我们刚刚创建的数据
3. 总结
如此,我们针对索引的新建就完成了,但是现在的数据还是手动添加的,理论上我们还需要从我们的数据库中把数据同步过来,实现自动数据同步,那么下一节,我们来看看solr数据同步如何操作。