1. Tugraph
Tugraph是一款开源的性能优秀的图数据库,该图数据库使用多版本的B+Tree作为数据的存储引擎,同时设置了点边数据在这个存储引擎上的布局(主要考虑数据的局部性),从而达到高性能查询的目的。本文主要从Tugraph使用的存储引擎和Tugraph的设计角度进行一些分析。TuGraph的源码仓库:GitHub - TuGraph-family/tugraph-db: TuGraph is a high performance graph database.
2. LMDB
2.1 LMDB的特点:
优点:
- 基于B+树的key/value存储
- 支持事务(ACID),隔离界别为Serializable
- 支持多版本控制,读操作不会阻塞写操作
- 使用memory-mapped映射文件,不需要调整cache的参数,冲突重启不需要恢复数据
- 使用CacheLine对齐的数据结构,对CPU的缓存友好
- 支持并发操作,支持多进程或者多线程,Writer不会阻塞Reader,同样Reader不会阻塞Writer
- 在多CPU机器上读操作可以实现真正的线性扩展,没有死锁的问题
- 完全隔离的多版本并发(实现中两个版本),Serializable的隔离等级,可以实现事务的嵌套(Tugraph没有实现事务的嵌套)
- 可以批量写
- 使用Copy-on-Write,数据不会被覆盖,只会Append写入,两个版本保证旧数据会空间会被回收复用;
- 无需WAL,DB崩溃后无需恢复,没有commit的数据视为无效数据无需恢复
- 使用单级存储(Single-Level Store)
- 读操作直接饮用MMAP指针,没有数据拷贝开销
- 写操作直接写入MMAP映射到磁盘,没有buffer,也不需要buff的调参。依赖于OS的pageCache,在应用层没有cache的浪费
缺点:
- 任意时刻只能一个线程写数据
- 对于长时间事务来说,多版本树可能会蜕变成append-only树,导致写入后数据无限增长;
- 没有compaction机制,导致数据不能做TTL的回收
- 使用操作系统来管理内存,数据库的性能会收到系统的影响比较大
- 使用mmap,频繁缺页产生中断,会对性能产生影响
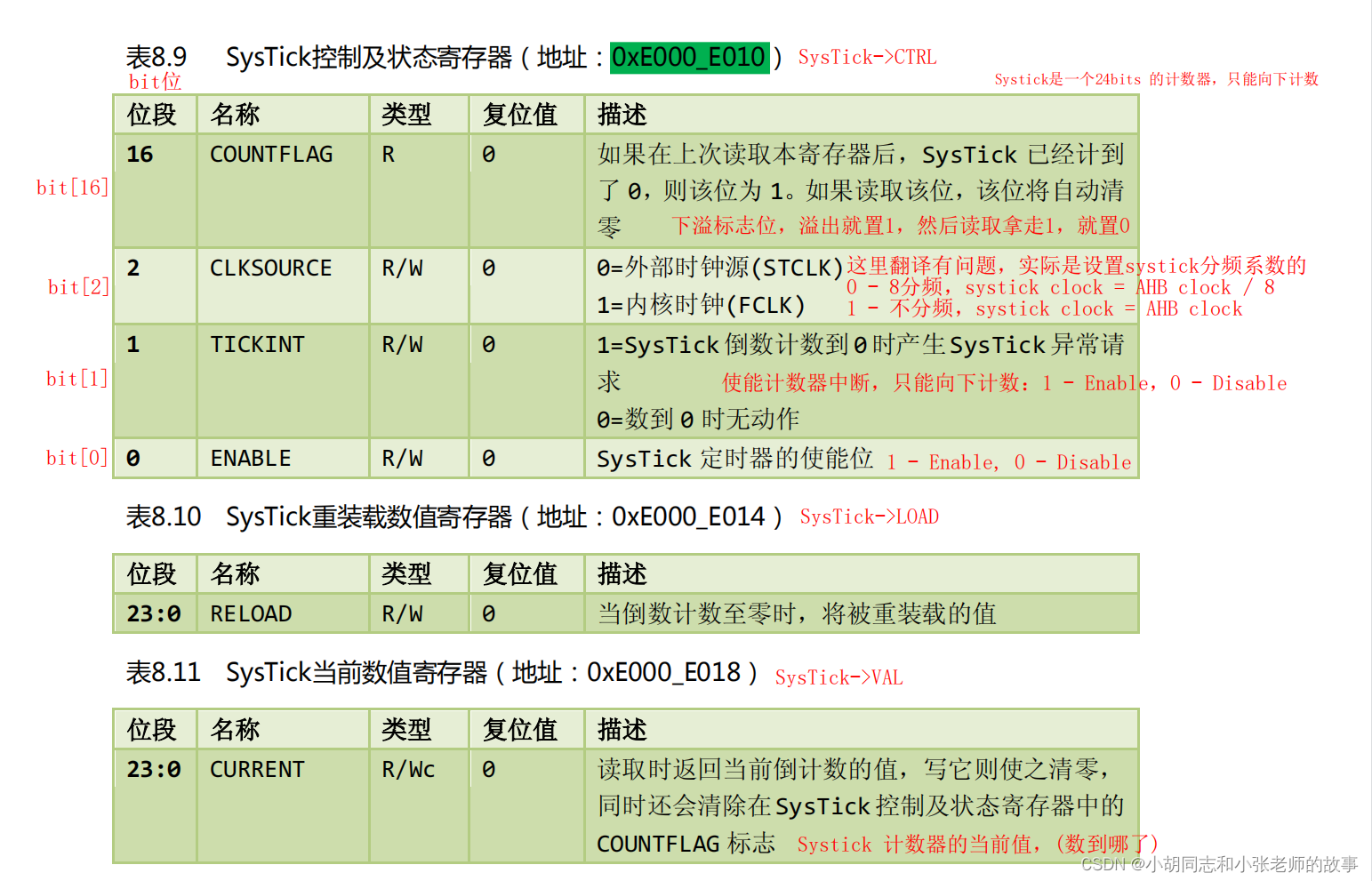
2.2 LMDB的实现原理
Append only tree:
如下图有个三层结构的B+Tree结构
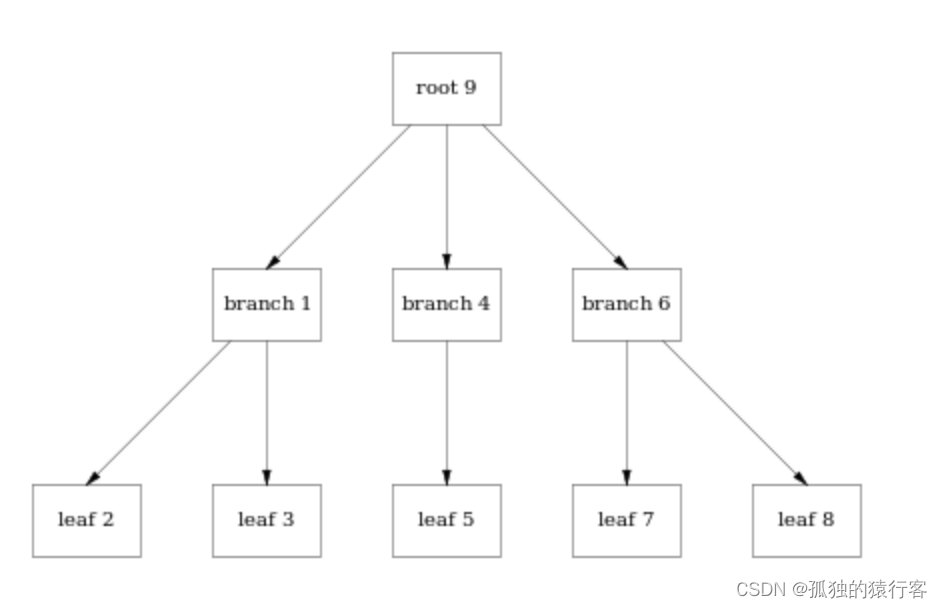
他在硬盘上的存储结果如下所示:
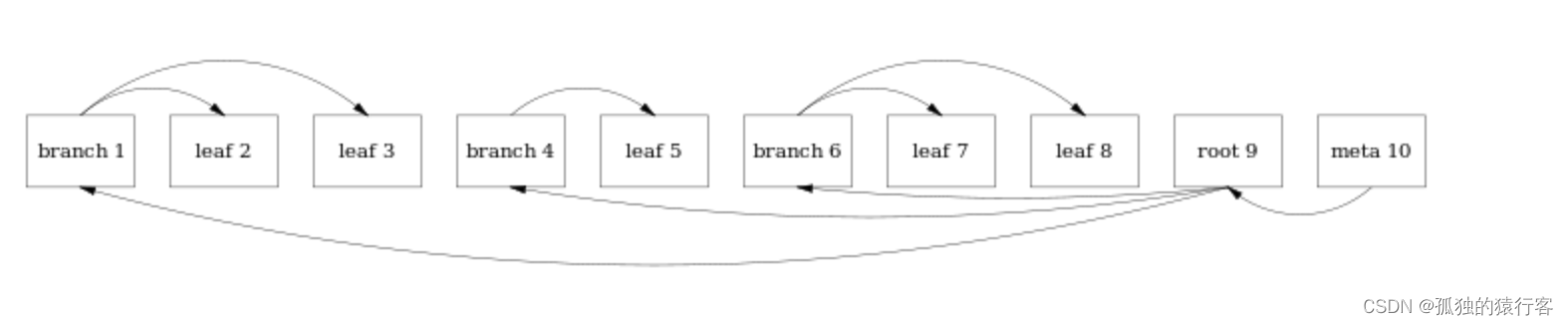 每个方框的是一个page的大小,由于磁盘测存储是一维的,所以这里会按照page Flat成一位的存储,Mata存在在文件的最尾部,他记录的root的pageID,从Meta中就可以将整棵树遍历,一般Meta在内存中;当我们修改Leaf8中的数据的时候,会有如下的变化:
每个方框的是一个page的大小,由于磁盘测存储是一维的,所以这里会按照page Flat成一位的存储,Mata存在在文件的最尾部,他记录的root的pageID,从Meta中就可以将整棵树遍历,一般Meta在内存中;当我们修改Leaf8中的数据的时候,会有如下的变化:
 由于我们采用COW的方式,因此并不会in-place的修改leaf8上的数据,而是将leaf8 copy到一个新的page,由于file中增加的新的page,改变了树的结构,因为这个修改会将leaf8的父节点,一直到根节点复制一份。新的父节点指向新的叶子结点(这里是leaf12),对于没有修改的leaf还保持指向不变。此时会有两个版本的数据同时存在,如果此时有读tranaction指向leaf8,他读到的数据还是之前的老版本数据,一直到其tranction结束;当修改leaf12的事务完成写的时候,整个修改在磁盘上的形式如下所示:
由于我们采用COW的方式,因此并不会in-place的修改leaf8上的数据,而是将leaf8 copy到一个新的page,由于file中增加的新的page,改变了树的结构,因为这个修改会将leaf8的父节点,一直到根节点复制一份。新的父节点指向新的叶子结点(这里是leaf12),对于没有修改的leaf还保持指向不变。此时会有两个版本的数据同时存在,如果此时有读tranaction指向leaf8,他读到的数据还是之前的老版本数据,一直到其tranction结束;当修改leaf12的事务完成写的时候,整个修改在磁盘上的形式如下所示:
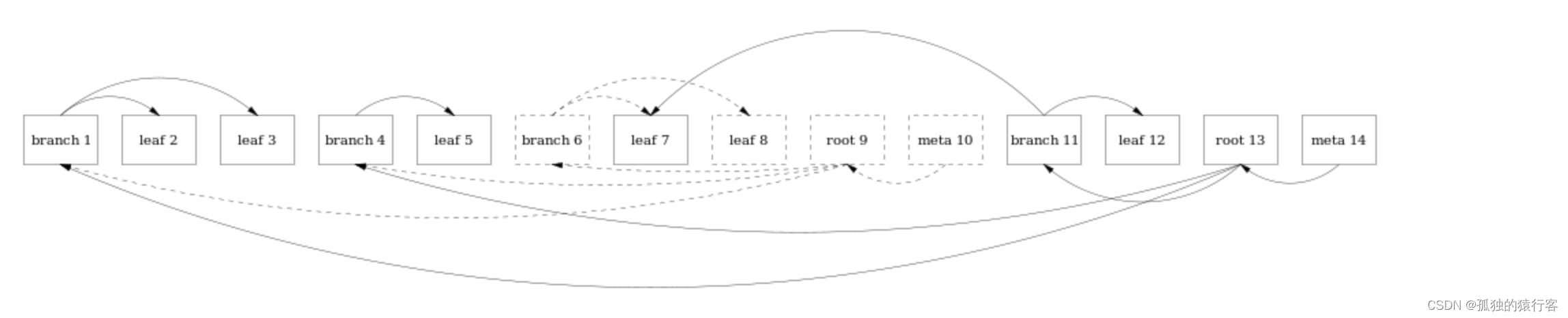 可以看到,修改一个page的数据需要增加4个page的数据append到文件的尾部,会带来一定的写放大,以及磁盘空间的浪费。但是这种顺序的写入相比随机in-place的写入效率会高很多,并且这种写入不需要事务日志,因为数据本文件本身就是日志;这种Append-Only的形式带来的问题就是旧版本数据的会积累的越来越多,文件大小会无限的增加上去,为了解决这个问题,LMDB采用每个root维护两个B+Tree的方式;其中一个存储用户的数据,另一个存储给定的事务中空闲的pageID 列表,这样就的一些老的page可以被重复利用,从而保证数据库无限制的增加,同时也减少了Compaction的过程(注意这里是有条件的,旧的page不被其他事务引用的情况下才会进行服用旧的闲置的page);
可以看到,修改一个page的数据需要增加4个page的数据append到文件的尾部,会带来一定的写放大,以及磁盘空间的浪费。但是这种顺序的写入相比随机in-place的写入效率会高很多,并且这种写入不需要事务日志,因为数据本文件本身就是日志;这种Append-Only的形式带来的问题就是旧版本数据的会积累的越来越多,文件大小会无限的增加上去,为了解决这个问题,LMDB采用每个root维护两个B+Tree的方式;其中一个存储用户的数据,另一个存储给定的事务中空闲的pageID 列表,这样就的一些老的page可以被重复利用,从而保证数据库无限制的增加,同时也减少了Compaction的过程(注意这里是有条件的,旧的page不被其他事务引用的情况下才会进行服用旧的闲置的page);
LMDB的实现方式
下面以进行四个transaction进行数据写入为例:
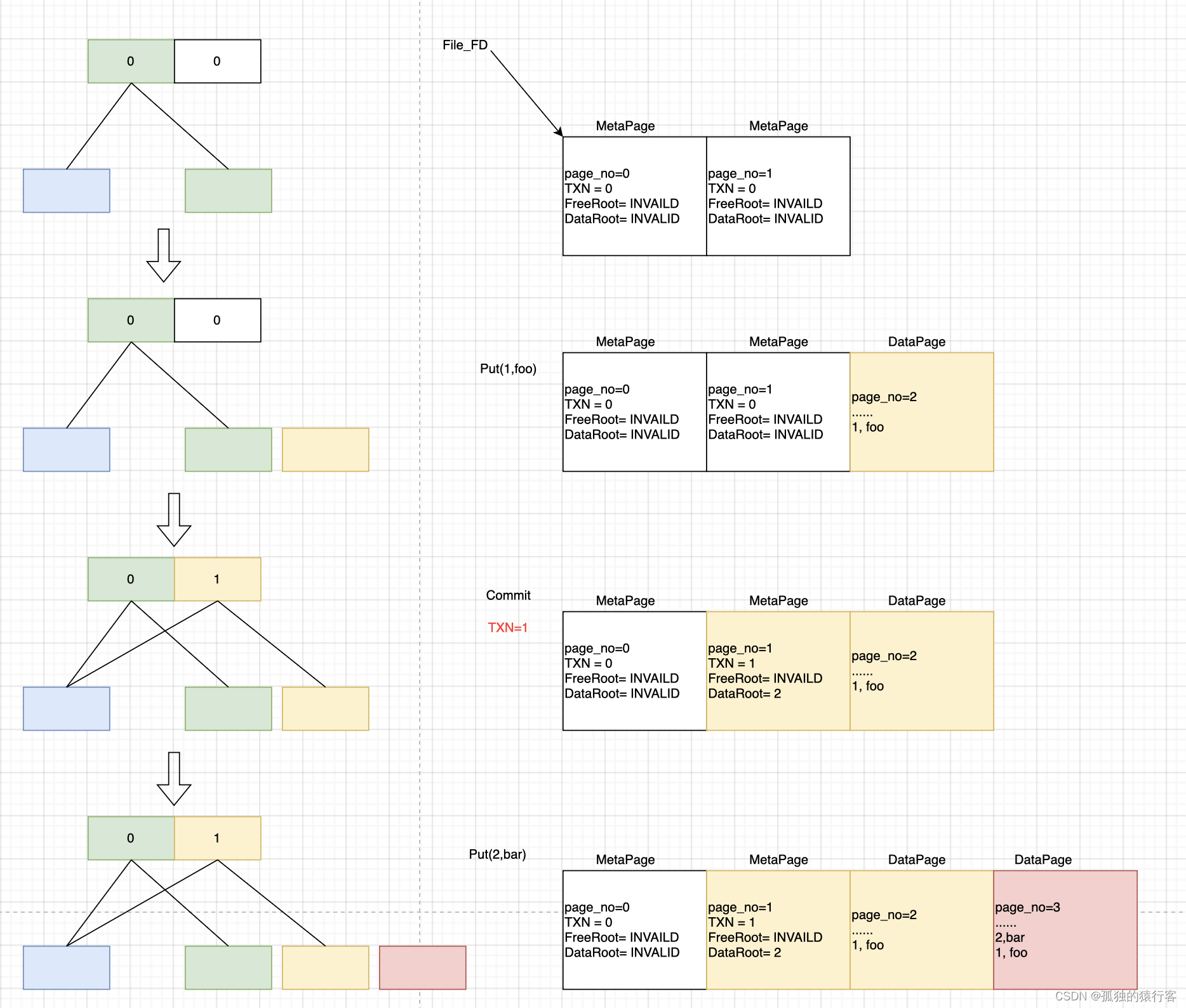
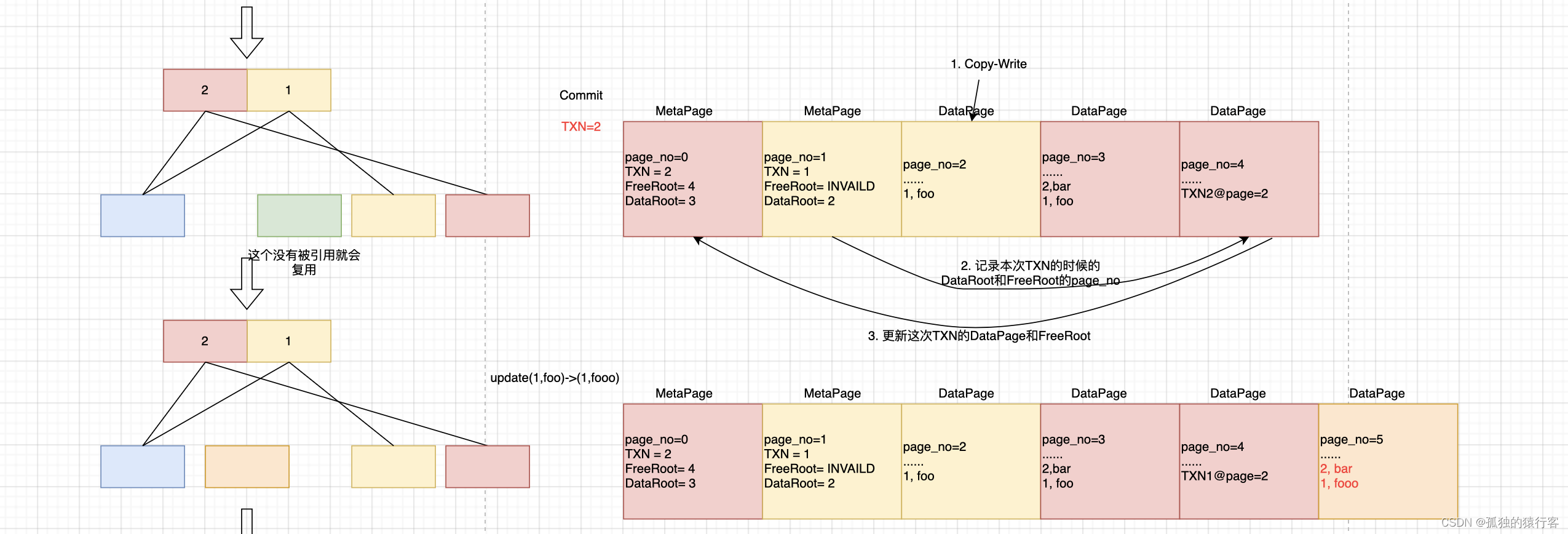

可以看到LMDB的数据数据没有像Append-only Tree那样数据无尽的增长下去,这主要归功于lmdb的多版本的功能(目前只有两个版本),旧版本数据不在被读者使用的时候,就会释放空间,义工后续的数据写入;
3. Tugraph设计解析
Tugraph的数据是在lmdb的基础上使用page为单位存储点以及改点的临边的数据,这样可以保证能够快速读取某点以及某点所以临边的数据;
Tugraph的设计:
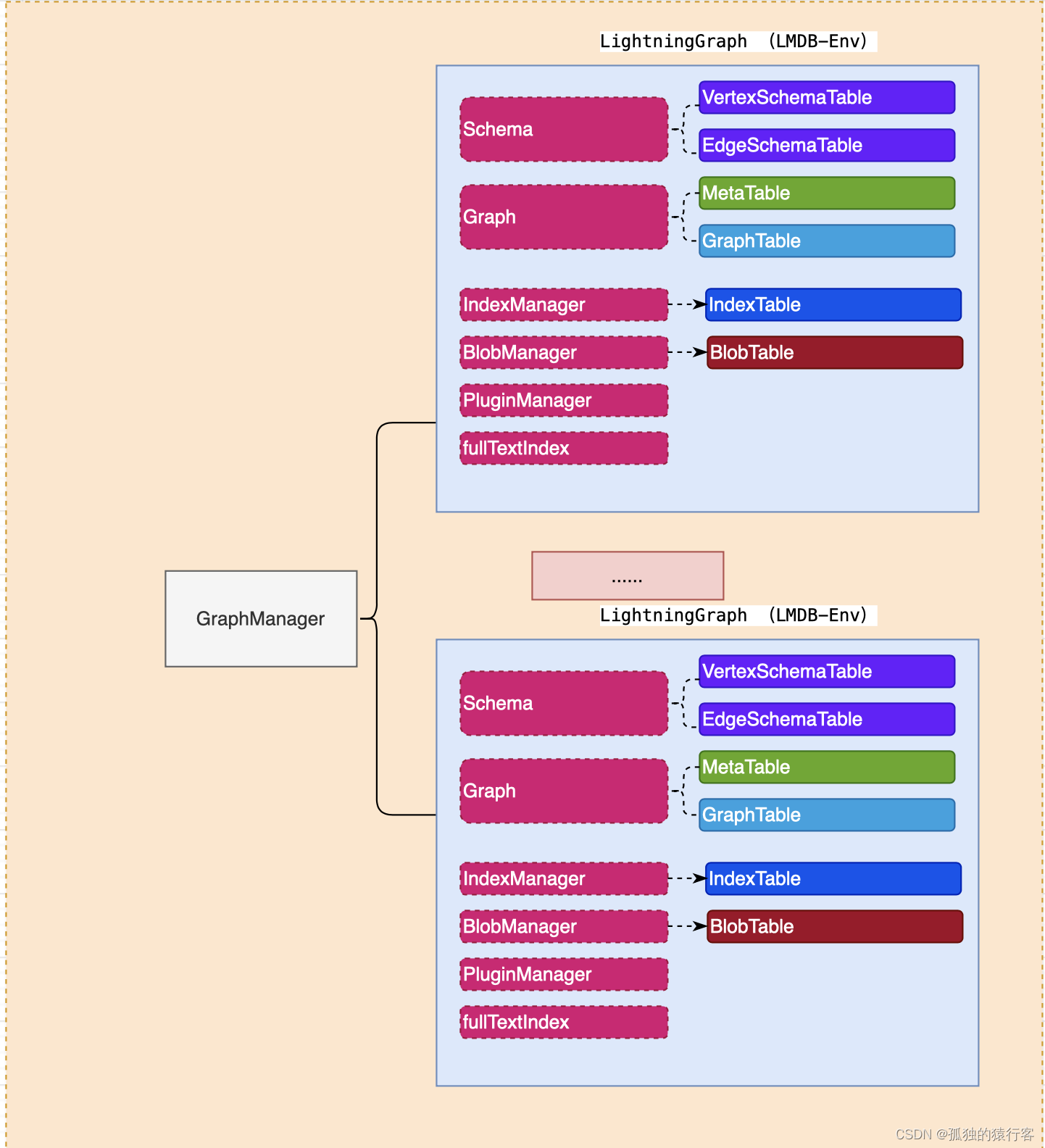
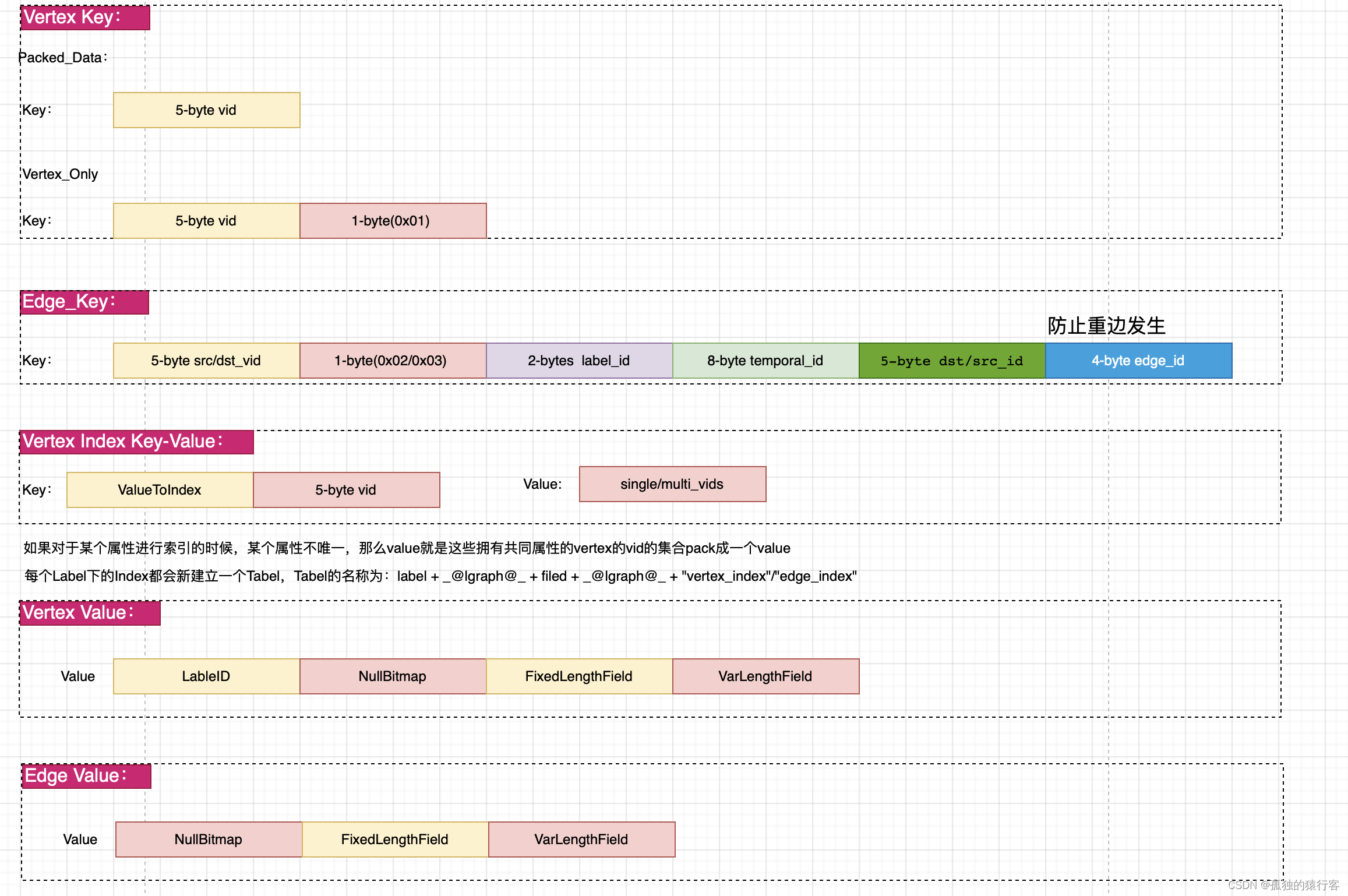
如图所示,tugraph支持多图空间,用GraphManager来管理多个图,每个图里面分为schema模块,graph模块,索引管理模块,插件管理模块,以及全文索引管理模块等组成。其中schema模块主要管理数据的元信息,而真正的数据存储在graph中,这里面每个模块管理的数据都在对应到lmdb的一个表中。而tugraph的点边数据组成如下所示:
4. 总结
Tugraph采用lmdb作为存储引擎,也就具备了lmdb的优缺点,具有优秀的查询性能,但是尽管采用多版本的append-Only Tree和COW技术,使得在写入数据的时候具有明显的写放大行为;同时由于没有compaction的行为,使得Tugraph的数据只能不断的增长;
5. 参考文献
- how the append-only btree works
- LMDB API查询
- LMDB benchmark
- http://www.lmdb.tech/media/20141120-BuildStuff-Lightning.pdf OpenLDAP Project LMDB
- Symas LMDB Tech Info | Symas
- https://arxiv.org/pdf/1910.05773.pdf LiveGraph的原理介绍
- https://www.usenix.org/system/files/conference/osdi16/osdi16-zhu.pdf Gemini: A Computation-Centric Distributed Graph Processing System
- https://www.usenix.org/system/files/conference/fast15/fast15-paper-zheng.pdf
- https://www.usenix.org/system/files/conference/osdi12/osdi12-final-126.pdf
- MMap: Fast Billion-Scale Graph Computation on a PC via Memory Mapping - PMC MMap: Fast Billion-Scale Graph Computation on a PC via Memory Mapping